As Large Language Models become ubiquitous, platform developers should start providing them as native services. What will this look like?
Tom: “Currently, his bank account is blowing up.”
Jean-Ralphio: “I made my money the old-fashioned way: I got run over by a Lexus.”
Tom: “I still can’t believe you won all that money in the lawsuit.”
Sometimes it feels like we, as software developers, are sitting around a table as though we were Tom Haverford and Jean-Ralphio Saperstein, from the popular television sitcom, Parks and Rec. Instead of discussing potential business models for Jean-Ralphio, though, we’re talking about how we can integrate text generated by GPT-4 and other Large Language Models (LLMs) into our applications and services. Sometimes, we even ask them, directly. However, I am much more excited to see what happens when we transition to using Platform-Native LLMs. There are still a lot of hurdles to cross, but the benefits far outweigh the technical challenges.
We Have the Technology
There’s a long history of moving Machine Learning workloads, typically considered to be computationally expensive, out of the cloud and onto our native devices. On Apple’s platforms, we’ve had access to facial detection models since iOS 5, speech recognition since iOS 10, and, with the release of Core ML in 2017, a whole host of different models. Last year, Mozilla did something remarkable by releasing a local translation plugin for its desktop Firefox Browser.
Large Language Models are where it’s at, though. In the last two months (ever since the release of Llama), we’ve seen an explosion of text-generating, code-slinging models that you can run on just about any hardware. I started playing with one tool, called Dalai, that brings a library of these models as close as a command-line script away. If it is impressive to see these systems responding intelligently to textual queries using web-based tools such as Chat GPT, it feels even more so to know that this isn’t happening in some faceless data center somewhere, but rather, on my system. If you really want to, you can even download the Vicuna model and run it in your browser, thanks to a project called Web LLM.
This growth isn’t just for hobbyists and technophiles, though. Last week, at I/O 2023, Google announced its new Large Language Model, powering a whole slew of services, called Palm 2. The most compressed, streamlined version of this model is already running on Android phones.
These are exciting developments. Platform-Native LLMs are a desirable development for a variety of reasons. The first and most natural benefit is “cutting the cord.” If we can only use LLMs as long as we are connected to the internet, on a sufficiently speedy connection to make near real-time responses, our services are hampered. Natural Language is an interface for our applications. Just as we do not kick users to a CLI the moment the lights go out, users shouldn’t expect their natural language interfaces to fail, just because our WiFi connection is a little slow.
Then there’s the price tag. To be useful, none of these systems are computationally cheap. OpenAI’s GPT API can be expensive for complex applications. I haven’t seen pricing information for Google’s Palm 2 API, but it certainly won’t be free. While we should always be willing to pay for quality services, a “count your nickels and dimes” approach to something that is quickly becoming ubiquitous is a bad situation if it results in poor user experiences.
Already, we’re seeing a trend toward credit-based pricing schemes for SaaS applications. While this ameliorates the difficult problem of pricing for the developers, it risks obscuring the cost of a service, leaving the user confused. This application for teachers sidesteps the issue by throttling its services for individual users (relying instead on school districts’ acquisition managers to deal with the complexity). As developers, we’re okay with waving our hands at the nuances of tokenization and being charged for a service based on an obscure metric. Teachers don’t work with tokens, though, and they’ll never see all of the prompts and text that go into building our system. This means that they can’t easily translate their workload into an understandable budget. Platform-Native LLMs can solve this problem by swapping the cost of an API call, measured in tokens and dollars, for a simpler calculus, involving the cost of the time it takes a given system to respond.
There are a multitude of benefits to Platform-Native LLMs. Unfortunately, there are a couple of hurdles to clear…
Well, Almost
Large Language Models are, by necessity, quite large. The Web LLM took several minutes before it was capable of responding to my queries. It took much less time when I tried to download the models for Dalai, directly. It was only a few GB of space, and that’s okay on my MacBook. That might not be okay on my iPhone. These systems are substantially larger than the task-specific models we’ve seen embedded in local systems, before. How much space on a user’s device can or should platform developers devote to this kind of a subsystem?
File size isn’t the only issue, here, though. The responses I received from Dalai, running the 7-Billion parameter version of Alpaca, were quite good, but not as good as the responses I get from Chat GPT or Bard. On top of that, it still felt like molasses on a late-model MacBook Pro. What kind of speed/capability tradeoffs are we willing to make, in return for the benefits of local model execution?
The problem that concerns me the most, though, is consistency. The following GIF features three different responses to two different queries. The first one asks for a simple recommendation: “I’m drafting an article on artificial intelligence, what’s an interest-arousing opening sentence?” Now, I didn’t use any of these suggestions, but they were illuminating. ChatGPT and Alpaca each gave me a one-sentence answer. Google’s Bard gave me an encyclopedia of options, complete with a set of principles to consider.
The second question was much more interesting: “Provide a one-word response to summarize the intent of…” the Jean-Ralphio quote, above. ChatGPT was rather dry. It simply said “humor.” Google’s Bard became somehow defensive and started lecturing me about the fact that insurance fraud is a crime. Of all things, the Vicuna model gave me the most interesting answer.
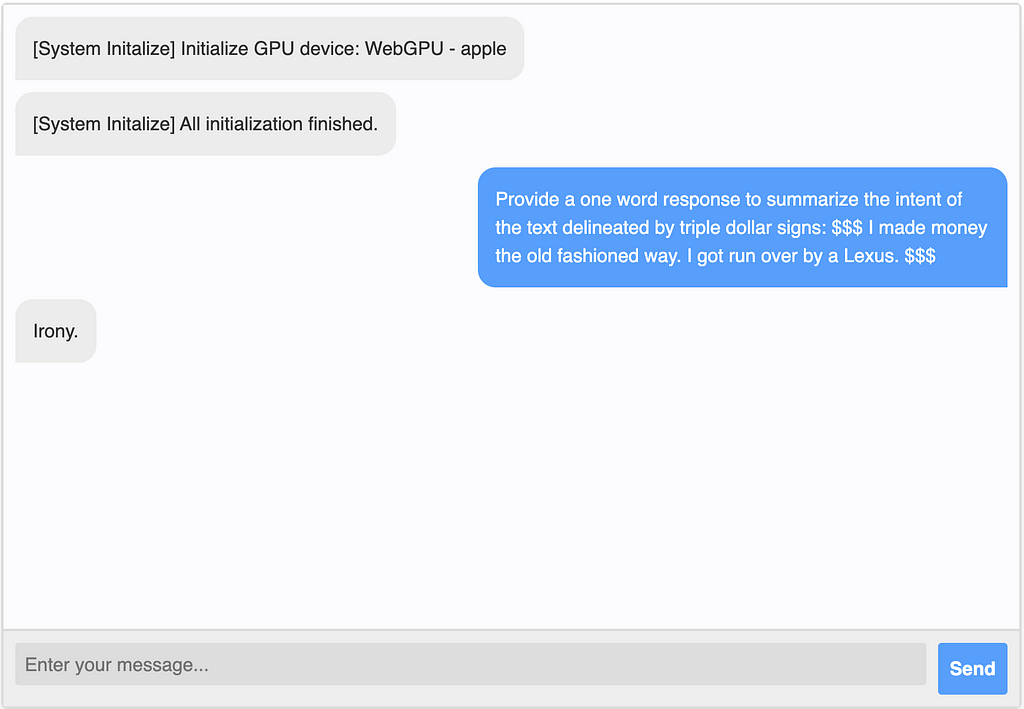
Now, the problem that I demonstrated here, of semantic analysis, is an old one. There are plenty of models that are devoted to classifying human-generated text. Let’s consider this to be a stand-in for any problem where we translate or transition from a free-form, organic medium (natural language) to a discrete format (such as a label), or vice versa. The problem here is twofold: each model gave me a response in a different format and each model’s response was, fundamentally different.
The first could be solved, in a straightforward manner, using a well-crafted prompt. The second could also, to a degree. We could provide a predefined set of labels as part of our problem and ask each language model to choose the best one. That might work. However, as our list of options grows larger and their delineations more subjective, we increase the risk that each model will produce a fundamentally different response from the other. In other words, each model, on each platform, will have a personality.
Call me an old-fashioned application developer, this isn’t the way APIs are supposed to work. They’re not supposed to have personalities. So much of what we do depends on a deterministic understanding of how our application code runs and how it interacts with the services that support it. I can’t say that I completely understand how the non-deterministic, subjective, and far-ranging aspects inherent in LLMs will affect this. It might even be that certain applications choose not to use Platform-Native LLMs for this reason, relying instead on the consistent personality of a third party.
Conclusion
These challenges aren’t insurmountable, they’re just difficult. We’ve had plenty of those before. In the Web community, we’ve demonstrated that we can take gnarly technologies and turn them into beneficial services for our users. It happened with the push notifications, where the same interface and functionality were exposed as a JavaScript API, despite having a heterogenous set of providers. It happened just this year, when the Chrome team released WebGPU support.
I fully expect to start seeing Platform-Native LLMs from multiple service providers. Apple’s Core ML and Webkit team have already done some great things, and they’re obviously onboard with the idea that we should be able to keep our important workloads on our devices. I don’t have my fingers crossed for WWDC, this year, but who knows — maybe next year. Likewise, Mozilla seems to be doubling down on responsible (interpreted as“local” or “private”) AI integrations. In quick succession, they launched a Mozilla AI subsidiary and their recent Responsible AI Challenge. Maybe that’s where the charge will start to standardize LLM interactions within Browser applications. We’ll see.
Platform-Native LLMs will be yet another powerful service for application developers to integrate. I’m excited by the prospect. Let’s harness them, as we do all of our tools, to enable and empower people through the systems we build.
We’re Ready for Our Platform-Native LLMs Now, Please was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.