A walkthrough of the C2PA content authenticity specification and its Rust SDK

Distinguishing authentic human-produced media from deepfakes or other algorithmically generated media is notoriously difficult. Existing tools produce a probability that given media is generated, but certainty is elusive. In the coming years, verifying the authenticity of political and election-related media will become critical as algorithmic media and deepfakes have flooded online spaces. Aside from sifting through online mis-or-disinformation, there’s also value in establishing authenticity for artists who want to assert claims of originality over their digital works.
The kinds of things one might need to know to understand if a digital image or video is authentic, and not artificially generated or copied, might include:
- Some sort of cryptographically secure signature verifying the integrity of media metadata like camera information, coordinates, and other things
- Some way of knowing that the media was not substantially digitally altered from its original form, or if it was, what those alterations were
There is a solution to that. Below I’ll talk about the following:
- The C2PA specification
- How the specification works
- Code walkthrough
- What does this get us?
- Problems
- What does this mean for the future?
The C2PA specification
The Coalition for Content Provenance and Authenticity, part of the Content Authenticity Initiative (led by Adobe), has produced the C2PA technical specification. Rather than trying to detect algorithmically-generated media, it outlines a system by which the provenance (origin) of media can be verified, along with the sequence of modifications performed to the media over its lifetime. This information is asserted cryptographically within an associated metadata structure.
Put another way: this standard provides confidence that supported classes of media are in fact human-generated — when stated as such in its metadata. Media without this metadata doesn’t benefit from the C2PA standard. This standard is opt-in, and relies on the partnership and adherence to the standard by equipment manufacturers (for example, cameras), media editing software (Photoshop and others), and any systems which might want to verify the origin of the media.
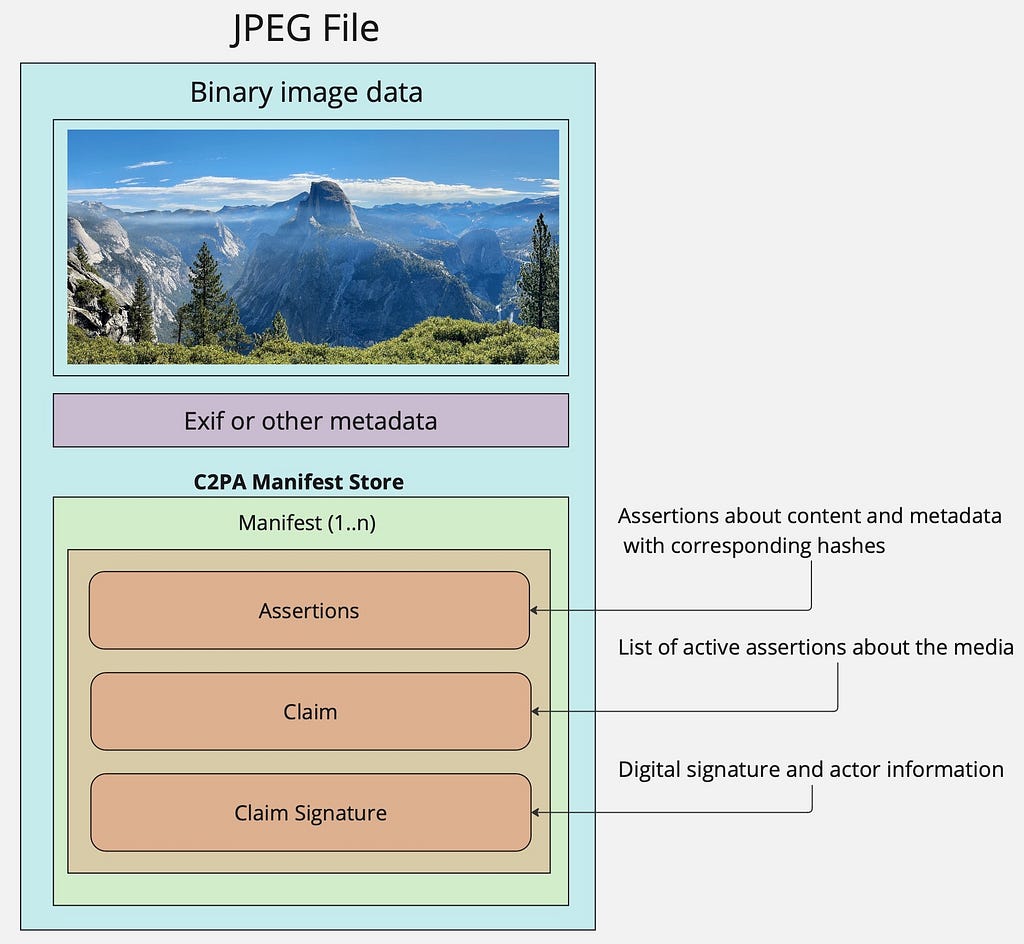
A related concept to this system is the Exif format associated with media, which might include information about the geolocation a photo was taken, hardware details, and camera settings. Exif data are then embedded into the media file, such as JPEG, directly. This data is generally not cryptographically signed.
The C2PA specification embeds metadata into media files directly (for supported media types; for others, it produces a “sidecar” manifest file). The manifest includes information such as:
- Media origin information (digital camera capture, other creative work)
- Media modifications over time, by what tool, and by what actor
- Digital signatures ensuring the manifest is tamper-evident
- And more
The metadata itself is stored in JUMBF format (the JPEG Universal Metadata Box Format).
How the specification works
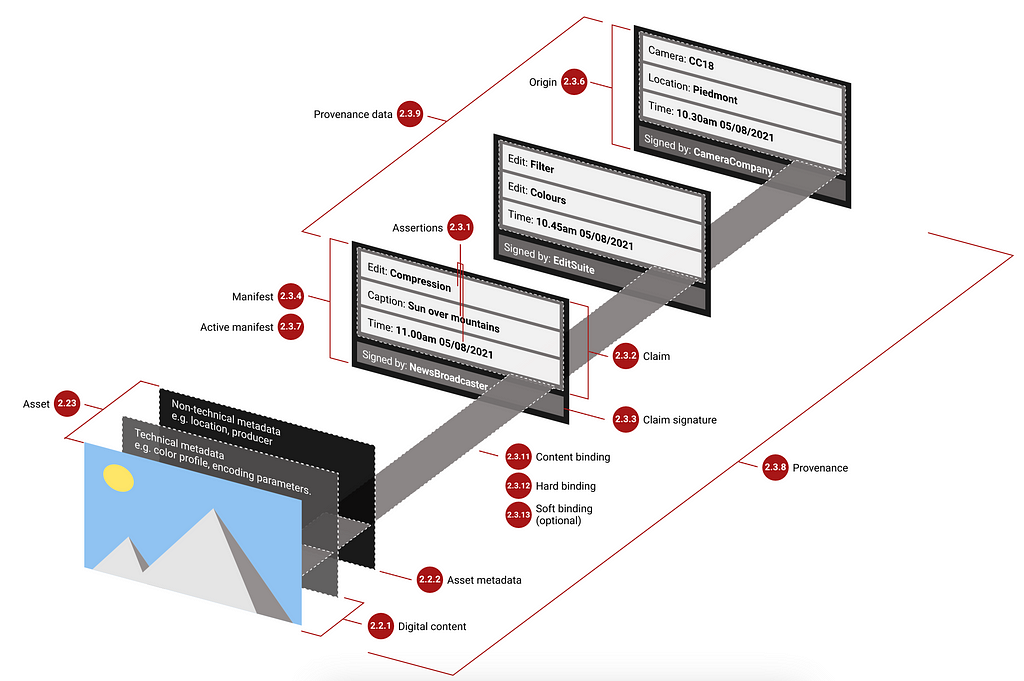
The specification describes a manifest, which contains a set of data about the origin of the media, and assertions about all subsequent actions performed on it.
For example, a manifest might assert that a photo was taken at a specific date and time, on a specific camera, and was subsequently edited (say, cropped) via a media editing tool. The assertions about the media can be digitally signed with the W3C Verifiable Credentials of the actor (person or organization) into a Claim. I’ll walk through an example of this in code further below.
While complex, and making a few assumptions (such as the trustworthiness of the tools which have updated the manifest), this information can tell us the difference between media taken on a camera versus generated by a model like Midjourney.
The cryptographic signatures included with the Claims then allow the ability to determine whether any of the assertions or other metadata have been modified after-the-fact. For example, an attempt by someone to modify the provenance of the media from pure algorithmic media to digital capture.
Code Walkthrough
There is a Rust SDK (also a few others, like c2pa-js) available to apply C2PA concepts to a variety of file types.
At this time, I couldn’t find a simple step-by-step walkthrough for how to use it, so I posted a quick outline demonstration of the SDK here using some explorative code.
This code initializes a new Manifest for a given media file. It encodes information such as author details, assertions about the content, and metadata like Exif or custom structs.
For example:
// Create a new manifest for new media
let mut manifest = Manifest::new("mikes-c2pa-test-code/0.1".to_owned());
// Establish this media as a new, original creativ work
let creative_work = CreativeWork::new()
.add_author(
SchemaDotOrgPerson::new()
.set_name("Mike Cvet")
.expect("set name")
.set_identifier("mikecvet")
.expect("set identifier")
)?;
// An assertion that this media was created, and some context about it
let created = Actions::new()
.add_action(
Action::new(c2pa_action::CREATED)
// Pretend this is an original digital image creation use-case
.set_source_type("https://cv.iptc.org/newscodes/digitalsourcetype/digitalCapture".to_owned())
.set_software_agent("mikes-c2pa-test-code/0.1")
.set_when(now_string.clone())
);
// Add the assertions into the manifest
manifest.add_assertion(&creative_work)?;
manifest.add_assertion(&created)?;
// Create a signing tool
let signer = create_signer::from_files(
signcert_path, pkey_path, SigningAlg::Ps256, None
);
// Sign and embed the manifest into the media file
manifest.embed(&source, &dest, &*signer.unwrap())?;
The content of the Manifest includes sections about the assertions and some signature information.
The actual signature cryptographic hash is redacted from the Manifest display output.
"manifests": {
"urn:uuid:5772a32a-777e-46d5-b65e-50426d95e84e": {
"claim_generator": "mikes-c2pa-test-code/0.1 c2pa-rs/0.25.2",
"title": "title",
"format": "image/jpeg",
"instance_id": "xmp:iid:56beb158-2cde-4ef4-b111-5a5a4aea7bef",
"ingredients": [],
"assertions": [
{
"label": "stds.schema-org.CreativeWork",
"data": {
"@context": "http://schema.org/",
"@type": "CreativeWork",
"author": [
{
"@type": "Person",
"identifier": "mikecvet",
"name": "Mike Cvet"
}
]
},
"kind": "Json"
},
{
"label": "c2pa.actions",
"data": {
"actions": [
{
"action": "c2pa.created",
"digitalSourceType": "https://cv.iptc.org/newscodes/digitalsourcetype/digitalCapture",
"softwareAgent": "mikes-c2pa-test-code/0.1",
"when": "2023-08-21T08:46:18.159790+00:00"
}
]
}
},
[...]
"signature_info": {
"issuer": "C2PA Test Signing Cert",
"cert_serial_number": "720724073027128164015125666832722375746636448153"
},
"label": "urn:uuid:5772a32a-777e-46d5-b65e-50426d95e84e"
}
}
The ManifestStore manages Manifests , their de/serialization, and their validation.
Examining the formatted display structure of the ManifestStore shows the following:
{
"active_manifest": "uuid:5772a32a-777e-46d5-b65e-50426d95e84e",
"manifests": {
/* Note that this is identified as the active manifest; other
* manifests may be present */
"urn:uuid:5772a32a-777e-46d5-b65e-50426d95e84e": {
/* Everything else, contained in the manifest
* described in the box above */
}
}
An active manifest refers to the most recent set of assertions applicable to the media. There may be numerous manifests associated with a media file; historical ones represent claims made for past versions.
A derived asset is built from existing media or content. An example is an image loaded into an editing tool and modified. When creating a new Manifest , these prior asserts are included as parent Ingredients. Within the Rust SDK, it is not possible to load and edit an existing Manifest from a media file; a new one must be created. For example, if media editing software wanted to add an assertion that the parent media was cropped, it might look something like this:
// Manifests cannot be edited. To modify the contents of the manifest store,
// pull in earlier versions of the content and its manifest as an ingredient.
let parent = Ingredient::from_file(file_path).expect("source file");
let mut manifest = Manifest::new("mikes-c2pa-test-code/0.1".to_owned());
let actions = Actions::new()
// This media was opened by the specified user agent
.add_action(
Action::new(c2pa_action::OPENED)
.set_parameter("identifier", parent.instance_id().to_owned())
.expect("set id")
.set_reason("editing")
.set_software_agent("mikes-c2pa-test-code/0.1")
.set_when(now_string.clone())
)
// This media was cropped by the specified user agent
.add_action(
Action::new(c2pa_action::CROPPED)
.set_parameter("identifier", parent.instance_id().to_owned())
.expect("set id")
.set_reason("editing")
.set_source_type("https://cv.iptc.org/newscodes/digitalsourcetype/minorHumanEdits".to_owned())
.set_software_agent("mikes-c2pa-test-code/0.1")
.set_when(now_string.clone())
);
This establishes a new Manifest, which contains a new set of assertions about the content:
{
"claim_generator": "mikes-c2pa-test-code/0.1 c2pa-rs/0.25.2",
"title": "test_file.jpg",
"format": "image/jpeg",
"instance_id": "xmp:iid:996edb05-fdf0-4d28-93a2-4e8bf3db3684",
"ingredients": [
{
"title": "test_file.jpg",
"format": "image/jpeg",
"instance_id": "xmp:iid:56beb158-2cde-4ef4-b111-5a5a4aea7bef",
"relationship": "parentOf",
"active_manifest": "urn:uuid:5772a32a-777e-46d5-b65e-50426d95e84e"
}
],
"assertions": [
{
"label": "c2pa.actions",
"data": {
"actions": [
{
"action": "c2pa.opened",
"parameters": {
"identifier": "xmp:iid:56beb158-2cde-4ef4-b111-5a5a4aea7bef"
},
"reason": "editing",
"softwareAgent": "mikes-c2pa-test-code/0.1",
"when": "2023-08-22T05:08:19.134866+00:00"
},
{
"action": "c2pa.cropped",
"digitalSourceType": "https://cv.iptc.org/newscodes/digitalsourcetype/minorHumanEdits",
"parameters": {
"identifier": "xmp:iid:56beb158-2cde-4ef4-b111-5a5a4aea7bef"
},
"reason": "editing",
"softwareAgent": "mikes-c2pa-test-code/0.1",
"when": "2023-08-22T05:08:19.134866+00:00"
}
]
}
}
],
This new set of assertions is signed, and embedded into the media as the new active manifest.
What does this get us?
Astute readers might say “tracking the origin and modifications to media is fine, but what prevents someone from modifying this metadata?”
I edited the manifest in the above test file, changing the date of the opening and cropping the image from 2023–08–22T05:08:19 to 2023–08–23T05:08:19 , a day later. Then, when trying to load the ManifestStore as such:
let manifest_store = ManifestStore::from_file("./out/test_file.jpg")?;
match manifest_store.validation_status() {
// Note: there are only statuses present if there are errors
Some(statuses) if !statuses.is_empty() => {
println!("Loading manifest resulted in validation errors:");
for status in statuses {
println!("Validation status code: {}", status.code());
}
panic!("data validation errors");
},
_ => ()
}
I’ll get the following:
Loading manifest resulted in validation errors:
Validation status code: assertion.dataHash.mismatch
The ManifestStore detected that the hash of the asset (including its manifest) didn’t match the stored hash in the manifest itself. Thus, it is evident via the data hash mismatch that the image or manifest was tampered with.
So theoretically, if everything works as expected, we can use this data to fully understand whether the creation and modification history of a given media file is fully accounted for and authentic.

Problems
The C2PA standard isn’t a panacea, either. While it feels like it has a good chance of establishing authenticity for a class of media, there are other considerations.
Privacy
The standard works by associating individuals’ unique identification data to the media’s origin or manipulation. The broad distribution of that data, perhaps by default, depending on where the industry goes, may be unintended by, or undesirable for, the media producers or authors.
Equitable access to authenticity
In a future where we consider media more authoritative when signed with the creators’ verified credentials, the value of media produced by those who lack those credentials is diminished.
Standards adherence
The technical standard is not a regulation, and will only make an impact once a critical mass of companies and their associated software apply it. Most media would need to have a C2PA manifest in order for most benefactors to make general use of it. If, for example, Apple decided it wasn’t interested, or similarly, the popular video editing tool of tomorrow decides the same, this excludes an enormous amount of everyday user-generated media from the ecosystem.
Standards abuse
Because C2PA is an open standard, there’s not really anything stopping someone from creating a tool which conforms to the standard, but, for example, labels all algorithmically generated media as digital captures and signs it as such. This would pollute the corpus of available C2PA manifests, and would require examination of user agents present in the manifest history (if that could be trusted either) as an additional input to authenticity determination.
What does this all mean for the future?
If we were to assume that this standard penetrates the technology industry more deeply, and companies commit to consistently adhering to the standard, we could think about bucketing media into three groups:
- Media with trustworthy provenance information, which provides context about the media’s lineage of creation and modification with some cryptographic guarantees provided by its digital signatures.
- Media with detectable modifications or inconsistencies to its provenance data (for example, the case mentioned above — replacing an origin of pure algorithmic media to digital capture, or modified timestamps or actors identifiers). The tampering will be evident to interested or skilled observers who will then draw their own conclusions about the legitimacy of the media.
- Media without any provenance information. It’s difficult to be certain about its origins, and we must rely on probabilistic techniques to try and determine its authenticity.
One could imagine that journalists, media organizations and social platforms apply different standards to the publication of these categories. For the first, they can treat claims of authenticity as highly credible. For the second, the opposite.
For the third, these organizations will have to make journalistic decisions based on their risk tolerance, the credibility of actors, and the output of tools trying to detect generative media. Similar considerations apply to evidence presented in court, media used in classrooms, and other contexts.
It’s still early to know how this will play out, and what risks lie ahead. But it seems like this specification, and its momentum, could play a major role in the verification of media legitimacy in the coming years. Given sufficient industry commitment and support, this system brings the potential to make media provenance transparency the standard in online spaces.
Although the CAI seems to have broad industry interest, we’re waiting to see what kinds of concrete technological commitments will happen industrywide to make use of this provenance specification.
Verifying the Origin of Media in an Algorithmic World was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.