Things I wish I had known before playing around with Triton

This is the second article regarding Triton Inference Server. In the first one, I described features and use cases. If you missed it and don’t understand some of the concepts from this text, I encourage you to read it first. You can find it here.
This article describes tips and tricks, presents a cheat sheet of useful commands, and provides code samples for benchmarking different model configurations for computer vision models. This article is more technical, and by reading it, you will learn specific commands for optimizing and configuring the models Triton serves.
Note: in all of the commands below, I use containers with versions 22.04or 22.11, but you can choose whatever version works for you. Those containers depend on CUDA drivers, and the versions I am using in the commands below might not work for you.
Cheatsheets
- Run Triton in the docker container
- Important note: You have to pass the absolute path of the current directory and mount at the same path in the container filesystem. Otherwise, it won’t be able to find models in the model-repository
docker run
--gpus=all
-it
--shm-size=256m
--rm -p8000:8000
-p8001:8001
-p8002:8002
-v$(pwd):/workspace/
-v /$(pwd)/model_repository:/models
nvcr.io/nvidia/tritonserver:22.11-py3
bash
2. Use model-analyzer tool in the docker container
docker run
-it
--gpus all
-v /var/run/docker.sock:/var/run/docker.sock
-v $(pwd):$(pwd)
--net=host
nvcr.io/nvidia/tritonserver:22.11-py3-sdk
3. Define global response cache
tritonserver --cache-config local,size=1048576
4. Define model response cache (in config.pbtxt)
response_cache { enable: true }
5. Define the models’ poll interval
tritonserver --repository-poll-secs
6. Typical model-repositorystructure
model_repository/
└── text_recognition
├── 1
│ └── model.plan
└── config.pbtxt
7. Define dynamic batching (here, I use 100 microseconds as the time to aggregate dynamic batch in config.pbtxt )
dynamic_batching { max_queue_delay_microseconds: 100 }
8. Define the model’s max batch size (here, I use eight as the maximum batch size in config.pbtxt)
max_batch_size: 8
9. Model warmup
- Add this line in config.pbtxt. The field key must match the defined input name, type, and dims.
model_warmup [{
name : "regular sample"
batch_size: 1
inputs {
key: "input__0"
value: {
data_type: TYPE_FP32
dims: [ 3, 224, 224 ]
zero_data: true
}
}
}]
10. TensorRT optimization (use half-precision model, define max workspace size in config.pbtxt)
optimization { execution_accelerators {
gpu_execution_accelerator : [ {
name : "tensorrt"
parameters { key: "precision_mode" value: "FP16" }
parameters { key: "max_workspace_size_bytes" value: "1073741824" }
}]
}}
11. OpenVINO optimization (for models executed on CPU in config.pbtxt)
optimization { execution_accelerators {
cpu_execution_accelerator : [ {
name : "openvino"
}]
}}
12. TF JIT optimization (in config.pbtxt)
optimization {
graph { level: 1 }
}
13. TensorFlow XLA optimizations
TF_XLA_FLAGS="--tf_xla_auto_jit=2 --tf_xla_cpu_global_jit" tritonserver --model-repository=...
14. TensorFlow with automatic FP16 optimization (in config.pbtxt)
optimization { execution_accelerators {
gpu_execution_accelerator : [
{ name : "auto_mixed_precision" }
]
}}
Tips and Tricks — Things I Wish I Knew Before Playing Around With Triton
- To use model-analyzerin docker container, remember to mount a volume with model-repository at the same path in the container as is in the host filesystem. Otherwise model-analyzer will have problems with finding deployed models.
docker run -it
--gpus all
-v /var/run/docker.sock:/var/run/docker.sock
-v $(pwd):$(pwd)
--net=host
nvcr.io/nvidia/tritonserver:22.11-py3-sdk
cd /home/<path_to_model_repository_parent>
model-analyzer profile
--model-repository $(pwd)/model_repository
--profile-models <model-name>
--triton-launch-mode=docker
--output-model-repository-path $(pwd)/output/
-f perf.yaml
--override-output-model-repository
2. To export the model to TensorRT, use the following docker image:
docker run --gpus all
-it
--rm
-v $(pwd):/workspace
nvcr.io/nvidia/tensorrt:22.04-py3
- It’s very important to use the same version of tensorrt container as tritonserver due to version validation. In other words, Triton won’t server model exported with a different version of TensorRT.
3. Basic command to convert ONNX model to TensorRT
trtexec --onnx=model.onnx
--saveEngine=model.plan
--explicitBatch
4. To export the model in half-precision, you can add the following flags:
trtexec ... --inputIOFormats=fp16:chw
--outputIOFormats=fp16:chw
--fp16
- This optimization gave up to a 2x speedup in latency and throughput on MobileNetV3 compared to the FP32 ONNX model.
5. To export the model in quantized format (some of the weights will be stored as int8), use the following flags:
trtexec ... --inputIOFormats=int8:chw
--outputIOFormats=int8:chw
––int8
- This optimization gave up to 2–3x speedup in latency and throughput on MobileNetV3 compared to the FP32 ONNX model.
6. To export the model with dynamic batch size, you have to specify three parameters to trtexec program. For a model trained on the ImageNet, those parameters can look like this:
trtexec ... --minShapes=input:1x3x224x224
--maxShapes=input:8x3x224x224
--optShapes=input:4x3x224x224
- This optimization gave up to a 2x speedup in latency and throughput on MobileNetV3 compared to models in single batch mode.
7. You should use explicit batch size for higher throughput and lower latency in single batch mode.
- Around 20% increased throughput and 16% reduced inference time were observed for the model with the explicit batch size compared to the model with dynamic batch size.
8. To export a model to ONNX (for example, from PyTorch code) with dynamic batch size, you have to specify the parameter dynamic_axes.
- You can define input and output names to gain better control over parameter names during inference. Otherwise, names based on the model’s layers names will be used.
- You can take a look at the PyTorch example to gain a better understanding of the process.
9. General configuration in config.pbtxt
- Define max_batch_size of the model to a reasonable value greater or equal to 1. If the model does not support dynamic batches, for example, a model exported to TensorRT with an explicit batch size equal to 1, you should select this value to 1.
- If max_batch_size is larger than one, then in dims, the first dimension by default is always -1. If you define dims: [3, 224, 224] Triton will append -1 at the first position on the list for you.
10. General model-analyzer configuration
- If you use a docker container to perform model analysis and tune Triton configuration parameters remember to mount a volume with the model-repository inside the container at the same path as it is on the host machine. Otherwise, perf_analyzer and model_analyzer will struggle to find models.
docker run -it
--gpus all
-v /var/run/docker.sock:/var/run/docker.sock
-v $(pwd):$(pwd)
--shm-size 1024m
--net=host
nvcr.io/nvidia/tritonserver:22.04-py3-sdk
- You can check the documentation and all parameters of the model_analyzer here.
Here’s an example of the command:
model-analyzer profile
--model-repository $(pwd)/model_repository
--profile-models model_onnx
--triton-launch-mode=docker
--output-model-repository-path $(pwd)/output/
-f perf.yaml
--override-output-model-repository
11. General perf-analyzer configuration
- It’s problematic to analyze models that operate on images if you can’t request random data. In this case, you can prepare a file with example data to be sent in a request. It has a predefined format with data as a flat list of values and the shape of a desired tensor. In the example below, I want to send an image of a shape (640, 480, 3) but in the field content I have to specify the image as a flat list of values, in this case, of the shape (921600,).
{“data”: [{<input_name>: {“content”: [3, 5, …], “shape”: [640, 480, 3]]}
- Command with data example stored in a file data.json will look like this:
perf_analyzer -m python_vit
-b 1
--concurrency-range 1:4
--input-data data.json
--shape image:640,480,3
12. Ensemble model
- You must create an empty directory with a version to meet Triton’s requirements.
Ensemble model
For example, the deployment of a ViT model as a Python model looks like this:
Functions initialize and execute are required by Triton. The initialization model and feature extractor are obtained from huggingface. execute does some preprocessing, calls models, and returns results.
Here’s its config.pbtxt:
And the directory looks like this:
python_vit/
├── 1
│ └── model.py
└── config.pbtxt
Here’s an example of the ViT model deployed as an ensemble model with separate pre- and post-processing.
ensemble_model/config.pbtxt
preprocessing/1/model.py
preprocessing/config.pbtxt
vit/config.pbtxt
The directory structure looks like this:
model_repository
├── ensemble_model
│ ├── 1
│ └── config.pbtxt
├── preprocessing
│ ├── 1
│ │ └── model.py
│ └── config.pbtxt
└── vit
├── 1
│ └── model.onnx
└── config.pbtxt
Take a look at a comparison of those two deployment configurations. You can see that optimization of the core model speeds up the inference pipeline up to around 30%.

I’ve selected MobileNetV2 as a benchmark. Below, you can find two tables with results for different batch sizes:
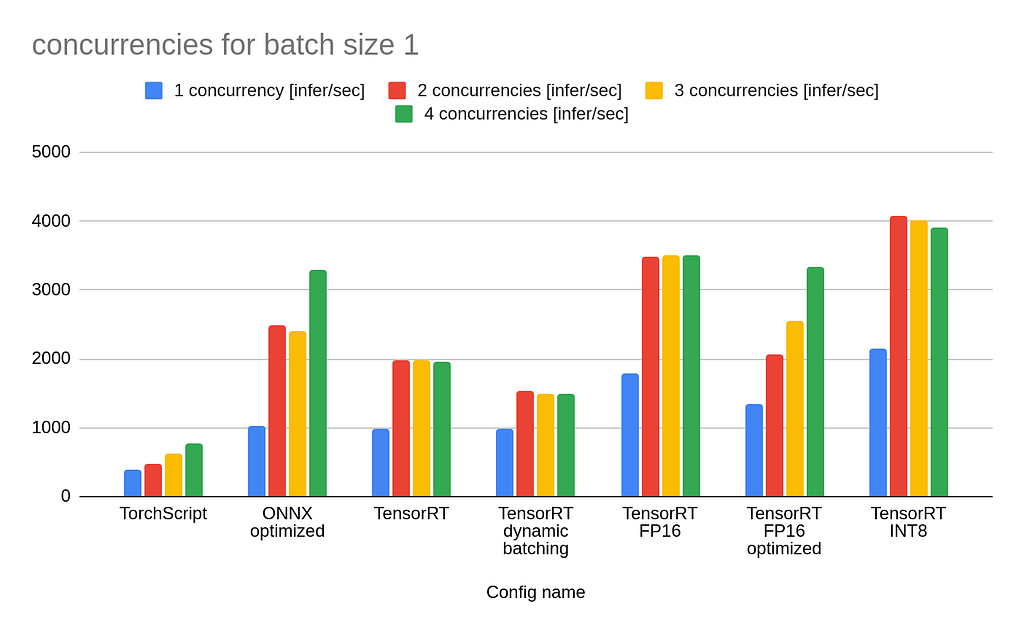

As one could expect, TorchScript without any optimizations is the worst in this comparison. From the table above, we can conclude that increasing batch_size with dynamic batching translates to increased throughput. Model conversion to FP16 and INT8 gives a noticeable speedup but may cause reduced performance.
What is interesting is that TensorRT FP16 has higher throughput than TensorRT FP16 optimized. The first model was exported as a half-precision model, whereas the second one was exported as a full-precision model and configured in Triton to use FP16. From the chart above, we can conclude that if you want to use a half-precision model, it’s better to export it in this form and not rely on Triton’s conversion. As always, results will differ on different hardware, and you should test all configurations before deployment on your machine.
This article presents a cheat sheet with useful Triton commands and configurations that you can refer back to when working with this tool. Code and benchmarks for different configurations of the model for computer vision are presented. The reader observed optimizing a complex model by separating the pre and post-processing code from the model inference itself.
I hope you learned something new today, and I encourage you to play around with Triton. I have a feeling you might like each other 🙂.
Originally published at https://www.reasonfieldlab.com.
Triton Inference Server Tips and Tricks was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.