A promising new sampling method

Some weeks ago I heard of an innovative work going in the llama-cpp repository that would add grammar constraint-based sampling to the repository.
What does that mean? In summary, this new feature would give us a huge potential for generating complex structural output, such as JSON and API calls without the needing of fine-tuning the model.
But additionally, it also means in theory we can generate syntax-error-free code! All we need to do is feed in the grammar of the target programming language, and we’ll have a code that “compiles”, because the generated output will necessarily follow the grammar.
I personally expect this feature to be so powerful that it could replace libraries like Guidance altogether.
Of course, there’s an additional complexity involved, which is writing context-free grammar. If you want to understand better how this is implemented, check the original PR.
In this article, we’ll focus on building a full working example in Python that leverage the power of this new feature.
Our agenda for today:
- Choosing a model
- Preparing and testing our environment
- Writing a simple grammar to understand how it works
The example code snippets are available here.
Choosing a model
First things first — a lot has happened in the last few months, so we should choose an up-to-date model according to some benchmarks.
Fortunately, I’ve found this very interesting leaderboard which ranks different Large Language Models according to different benchmarks.
A model that caught my attention is this llama2–13b-megacode2_min100:
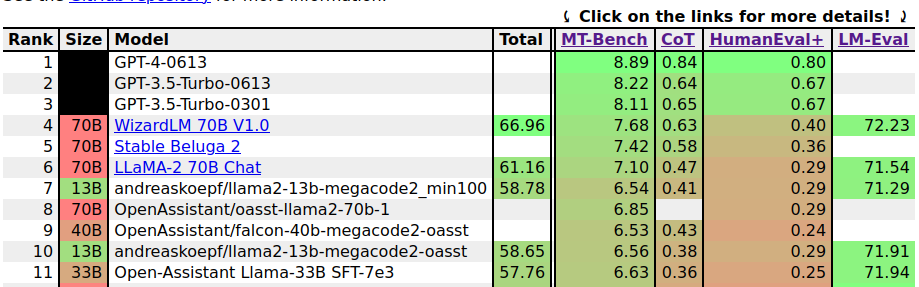
Its performance is comparable to much larger models, although still far behind the open-source leader WizardLM 70B. Nonetheless, I want to test something that is of a reasonable size to test. So this will do.
Unfortunately, I couldn’t find a GGML version of it, so I took instead the oasst version that scores slightly lower (to be honest, almost the same). Here’s the model converted by The Bloke. I downloaded the q4_K_M version binary file.
Preparing our environment
I’ve initially checked llama-cpp–python and found out that we also have Python bindings available since last week! But unfortunately, I’ve tested it, and did not work as expected… yet! So I created a bug report — in the meantime, I was able to get results using llama-cpp server directly. My code is mostly based on this Pull Request example so the credits go to the original author.
First, install your llama.cpp from source following the instructions here. Once you are able to build, you can access build/bin and find the server binary there.
Save your downloaded model next to this server, and then start it with:
./server -m llama2-13b-megacode2-oasst.ggmlv3.q4_K_M.bin
In a separate file, add the following code:
"""Code based on https://github.com/ggerganov/llama.cpp/pull/2532"""
import requests
grammar = r'''
root ::= answer
answer ::= "Good"
'''
prompts = [
"How's the weather in London?",
]
for prompt in prompts:
data_json = { "prompt": prompt, "temperature": 0.1, "n_predict": 512, "stream": False, "grammar": grammar }
resp = requests.post(
url="http://127.0.0.1:8080/completion",
headers={"Content-Type": "application/json"},
json=data_json,
)
result = resp.json()["content"]
print(f"Prompt: {prompt}")
print(f"Result: {result}n")
Install the requests with pip install requests and run this script. If all goes well, you should see the following output:
(env-llama-grammar) (base) paolo@paolo-MS-7D08:~/llama-grammar-example$ python minimal_example.py
Prompt: How's the weather in London?
Result: Good
Your environment works! Let’s break this down.
Writing a simple grammar
In the previous example, we’re constraining the token generation using this grammar:
grammar = r'''
root ::= answer
answer ::= "Good"
'''
It always outputs Good. This example is not so exciting! Let’s try some more interesting examples. Let’s extend the grammar to resolve between three options, and test it with three different prompts. We’ll do this using the or logical operator which is represented by the pipe ( | ) character.
grammar = r'''
root ::= answer
answer ::= ("Sunny." | "Cloudy." | "Rainy.")
'''
prompts = [
"How's the weather in London?",
"How's the weather in Munich?",
"How's the weather in Barcelona?",
]
It seems like this model likes Cloudy weather, it returns this answer most of the time. Did get a sunny once, so we know it works as expected:
(env-llama-grammar) (base) paolo@paolo-MS-7D08:~/llama-grammar-example$ python3 weather_example.py
Prompt: How's the weather in London?
Result: Sunny.
Prompt: How's the weather in Munich?
Result: Cloudy.
Prompt: How's the weather in Barcelona?
Result: Cloudy.
If you’ve used frameworks like Guidance before, which I wrote extensively about in the past, we’ve just replicated their Select functionality!
But it can be more interesting than that. We can nest the token structure in the grammar. For instance, let’s make a model that replies about the weather or complains:
grammar = r'''
root ::= answer
answer ::= (weather | complaint | yesno)
weather ::= ("Sunny." | "Cloudy." | "Rainy.")
complaint ::= "I don't like talking about the weather."
yesno ::= ("Yes." | "No.")
'''
In summary, this grammar describes an answer that can be either about the weather, a complaint, or just a yes/no.
Let’s see it in action:
(env-llama-grammar) (base) paolo@paolo-MS-7D08:~/llama-grammar-example$ python3 complaining_example.py
Prompt: <|im_start|You are a weather predictor. Answer with either Sunny, Cloudy or Rainy. How's the weather in London?<|im_end|><|im_start|>
Result: Sunny.
Prompt: <|im_start|How's the weather in Munich? Is it sunny? Answer with yes or no.<|im_end|><|im_start|>
Result: Yes.
Prompt: <|im_start|How's the weather in Barcelona? Try to complain about this.<|im_end|><|im_start|>
Result: I don't like talking about the weather.
Worked pretty! But not before I tweaked the prompt a little bit. You may notice some special tokens there, that flag when the user input starts and ends, as well as when the assistant reply starts.
Before adding the special tokens, the model would just complain all the time — so keep in mind that even using grammar still requires a good model and some prompting to get the most out of it.
Conclusion
Of course, studying the basics about compilers does help in understanding this type of grammar, but you don’t need to get too complex into this for it to be useful. Also, you can probably find useful examples out there. One of the examples provided in llama-cpp repository implements a JSON grammar for instance, which is super useful if you’re making the model call a REST API.
One thing I might try next is pulling the grammar of Python and generating syntax-error-free code.
Hope you found this new feature as exciting as I did! Cheers!
Testing Out Llama Cpp Grammar Constraint-based Sampling was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.