Comparing languages and libraries with a spatial nearest neighbour problem

Introduction
In my previous article, I presented how to solve the nearest neighbour problem using SQL and the Python libraries Geopandas and Scikit-learn.
I’ll review the previous solutions and present new ones using other libraries and languages this time. At the end, I’ll compare these solutions on speed and complexity.
The solutions to be presented are:
- SQL: using Distinct and Lateral Join on PostgreSQL
- SQL: using Google Big Query
- Python: using Geopandas, Shapely, PyGeos and Scikit-Learn
- Apache Sedona: using SQL
- Kotlin: using JTS
- Scala: using JTS
- Rust: using Geo and Rstar
My motivation is simple: Spatial data analysts spend hours solving these problems, so knowing what to expect from various languages, libraries, and technologies helps you plan your projects. On a more personal side, I used this project to explore other languages such as Scala, Kotlin, and Rust.
Method
All solutions will use the same data and return the same output. The datasets are at this link. They were gathered in 2021.
The goal is to find the closest postcode centroid in the Code Point dataset to each UPRN in the Open UPRN dataset. For simplicity, both datasets were limited to the District of Vale of White Horse found in the Boundary Line dataset.
In cases where the UPRN is equally distant to two or more postcode centroids, all the solutions implemented return the first postcode of the set ordered alphabetically and ascending.
There are 3,972 postcode centroids and 82,464 UPRNS in the filtered datasets. This results in 327,547,008 combinations.
I used two approaches:
- All vs all (Brute force)
- Sort Tile Recursive Tree (STRT)
In the All vs All approach, every UPRN is tested against every Postcode Centroid, and the closest one is chosen. This is an inefficient approach but a simple one. Testing every possible combination takes time. As I said, there are 327,547,008 combinations.
A Sort Tile Recursive Tree (Wikipedia, 2023) pre-classifies the geometries into subsets of close elements, so when you need to find the nearest element to a particular coordinate, you don’t have to test all the elements in the dataset, only those in the subset to which the testing coordinate belongs.
For example, there are ten geometries, and the STR tree classifies them into two subsets in this case. If you want to find the closest geometry to a certain point, you need to check which subset is closer and test every set element. This reduces the amount of combinations to test.
The code for all solutions is in this repository. The notebook contains the SQL, Python, Apache Sedona solutions, and speed comparisons. The Scala, Kotlin, and Rust solutions are within their own subfolders.
Speed Comparisons
Table 1 shows the comparison between the execution time of the different implementations.
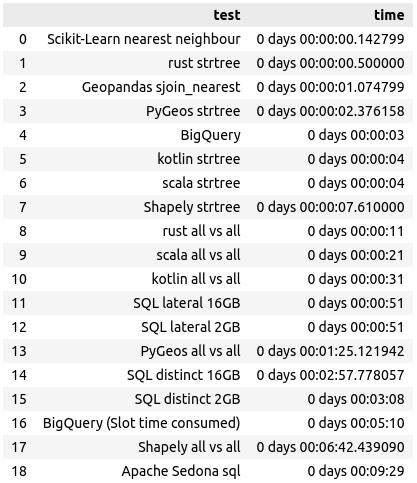
Scikit-Learn, in position 0, is the clear winner. However, it only works if the data are points. Polygons are not allowed as inputs (scikit-learn, n.d. b).
It is not a surprise that Rust comes next. It is known for being fast (Rust Team, 2018). This solution is fast; it can handle other geometries, such as lines and polygons. I did enjoy writing on Rust, but the concept of borrowing and passing ownership made me stumble a few times.
One of the things I enjoyed the most about Rust (also quite present in Scala and Kotlin) is that you can iterate easily through collections such as lists without for loops. It cleans up the code and is faster than a normal loop (doc.rust-lang.org, n.d.; Scala Documentation, n.d.; Kotlin Help, n.d. a).
Surprisingly, many Python solutions run very fast for a language famed for being slow (positions 0, 2, and 3). The development teams behind these libraries (Scikit-Learn, Geopandas, and Pygeos) greatly focus on optimisations. Scikit-Learn has documentation to improve speed (scikit-learn, n.d. b), while GeoPandas, the version I used, uses vectorised operations prototyped by PyGeos and then adopted by Shapely 2.0 (geopandas.org, n.d.).
As you can see from the code, I just ran the functions, while in the other languages, I had to build my solutions. If you need to build something of your own, you’ll notice that Python is not fast by nature and needs very specific knowledge of how to speed up processes. Most likely, you’ll end up playing with Cython, Numba, etc., and to me, these options look more esoteric than simply learning how to use a faster language.
In position 4, we have Google Big Query (GBQ). GBQ is quite fast and easy to use (it is just SQL), but there are some caveats:
- I had to rewrite my SQL commands as “distinct on” and “lateral joins” were not supported (Google Cloud, n.d. b).
- GBQ does not support projected coordinate systems (Google Cloud, n.d. a), which forced me to work on EPSG 4326 instead of EPSG 27700. This caused a discrepancy in some of the outputs.
Notice that there is another entry for GBQ almost at the end. GBQ runs fast because it splits the problem into parallel workers (Google Cloud, n.d. c). But if you add up the time each one takes to do the job, it would end in position 16. However, for the end user, the job gets done fast, which is what matters.
In positions 5 and 6, we have the Java Virtual Machine (JVM) languages, Kotlin and Scala, using a STR Tree from Java Topological Suite (JTS). I found these easier to write and debug than Rust and generally faster than Python. Scala is quite present in Apache Spark (Apache Spark, 2019) and other great tools (index.scala-lang.org, n.d.), and Kotlin is often used for Android development (Kotlin Help, n.d. b).
As said before, Scala, Kotlin, and Rust have a very rich set of collections and methods that I recommend everyone to explore.
In position 7, we got Shapely using a STR tree. This library has been adopting some of the optimisations from PyGeos (shapely.readthedocs.io, n.d.), but it is still not as fast.
So far, all the solutions are highly optimised or use STR Trees. That shows that Sort Tiles Recursive trees are fundamental for an efficient KNN solution.
We have Rust, Scala, and Kotlin in the next three places using an All-vs-All approach. This brute-force approach demonstrates how fast these languages can run even when executing an inefficient solution.
At positions 11, 12, 14, and 15, we find SQL on PostgreSQL. SQL performance has many factors (PostgreSQL Documentation, 2023), but I’ll focus on the settings and query.
Two different SQL were used: a Lateral Join and a Distinct On clause. The first one is faster based on the results. Both queries were run with different memory allocations but didn’t impact the results much.
It is unfair to only judge PostgreSQL on speed. It can do what GeoPandas will never do: handle multiple users, multiple queries (both simple or complex ones), and multiple tables all at once. Here, I’m just using two tables, but in the real world, most likely, I’d stick to PostgreSQL as most of the data is already in the server, and I don’t want to choke my PC’s memory.
In positions 13 and 17, we have the All-vs-All implementations of PyGeos and Shapely. I don’t expect anyone to use a brute-force approach for a KNN problem. These were done to demonstrate that these solutions are very slow.
Ultimately, we have PySpark using the Apache Sedona extension and the SQL API. The speed result could be blamed on many things:
- My incompetence in setting up Apache Sedona properly.
- It is meant to run in a distributed environment, solving large dataset problems (sedona.apache.org, n.d.), and not in a laptop running a small benchmark.
I’m very confident that Apache Sedona would shine in a proper environment and using a large dataset that I can’t simply load to Geopandas.
Conclusion
Different libraries and languages were tested to solve the same Spatial KNN problem. Every library and language has its purpose. Python has access to great optimised and easy-to-use libraries. Scala, Kotlin, and Rust are fast languages and have access to many libraries, but you need more knowledge to get the same result. SQL is very simple to use, allowing you to do very complex queries, but don’t expect a fast execution unless you are using Google Big Query.
All code and results are stored in this repository.
I’d follow the following rules next time I need to choose a library or language for a Spatial KNN problem:
- GeoPandas
– the data fits the memory
– you don’t plan to do complex queries - SKLearn
– the previous conditions
– the data is just points
– GeoPandas wasn’t fast enough - PostgreSQL
– the data does not fit the memory
– the data is already in the database, and reading it into the memory will take time
– you plan to perform complex queries - BigQuery
– the conditions from PostgreSQL point
– you want a very fast result, or your data is massive
– you are happy to use geographical coordinates
– you are also happy with rewriting your query to fit BigQuery SQL standards - PyGeos: You don’t want to use GeoPandas, and you want to speed up things and stay within Python
- Shapely: You don’t want to use GeoPandas or PyGeos, and you want to stay within Python
- Scala/Kotlin
– the data fits the memory
– you need to write a complex program of which KNN is just one part, and you need the whole program to run fast - Rust
– the data fits the memory
– you need to write a complex program of which KNN is just one part, and you need the whole program to run very fast
– you are happy to deal with a reduced universe of libraries - Apache Sedona
– your data is massive and needs to be spread on different clusters
References
Apache Spark (2019). Apache SparkTM — Unified Analytics Engine for Big Data. [online] Apache.org. Available at: https://spark.apache.org/.
doc.rust-lang.org. (n.d.). Comparing Performance: Loops vs. Iterators — The Rust Programming Language. [online] Available at: https://doc.rust-lang.org/book/ch13-04-performance.html [Accessed 1 Aug. 2023].
geopandas.org. (n.d.). Roadmap — GeoPandas 0.13.2+0.gd5add48.dirty documentation. [online] Available at: https://geopandas.org/en/stable/about/roadmap.html [Accessed 3 Aug. 2023].
Google Cloud. (n.d. )a. Data types | BigQuery. [online] Available at: https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types#geography_type [Accessed 3 Aug. 2023].
Google Cloud. (n.d.)b. Query syntax | BigQuery. [online] Available at: https://cloud.google.com/bigquery/docs/reference/standard-sql/query-syntax.
Google Cloud. (n.d.)c. Understand slots | BigQuery. [online] Available at: https://cloud.google.com/bigquery/docs/slots.
index.scala-lang.org. (n.d.). Awesome Scala. [online] Available at: https://index.scala-lang.org/awesome [Accessed 3 Aug. 2023].
Kotlin Help. (n.d. a). Collection operations overview | Kotlin. [online] Available at: https://kotlinlang.org/docs/collection-operations.html [Accessed 1 Aug. 2023].
Kotlin Help. (n.d. b). Kotlin for Android — Help | Kotlin. [online] Available at: https://kotlinlang.org/docs/android-overview.html.
osdatahub.os.uk. (2021). OS Data Hub. [online] Available at: https://osdatahub.os.uk/.
PostgreSQL Documentation. (2023). Chapter 14. Performance Tips. [online] Available at: https://www.postgresql.org/docs/current/performance-tips.html [Accessed 5 Aug. 2023].
Rust Team (2018). Rust Programming Language. [online] Rust-lang.org. Available at: https://www.rust-lang.org/.
Scala Documentation. (n.d.). Collections Methods. [online] Available at: https://docs.scala-lang.org/scala3/book/collections-methods.html [Accessed 1 Aug. 2023].
scikit-learn. (n.d. a). How to optimize for speed. [online] Available at: https://scikit-learn.org/stable/developers/performance.html [Accessed 3 Aug. 2023].
scikit-learn. (n.d. b). sklearn.neighbors.NearestNeighbors. [online] Available at: https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.NearestNeighbors.html#sklearn.neighbors.NearestNeighbors [Accessed 5 Aug. 2023].
sedona.apache.org. (n.d.). Apache SedonaTM. [online] Available at: https://sedona.apache.org/1.4.1/ [Accessed 5 Aug. 2023].
shapely.readthedocs.io. (n.d.). Migrating from PyGEOS — Shapely 2.0.1 documentation. [online] Available at: https://shapely.readthedocs.io/en/stable/migration_pygeos.html [Accessed 3 Aug. 2023].
Wikipedia. (2021). R-tree. [online] Available at: https://en.wikipedia.org/wiki/R-tree.
Spatial KNN Benchmark: From SQL to Rust was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.