A walkthrough about how to get the most out of your GPUs

Managing your GPU resources is just as crucial as managing your Python environment, especially if you work on multiple projects or collaborate with a team. As discussed in the previous article (check it out here), conflicting training jobs started on the same hardware and unnecessary GPU allocation can quickly become a headache.
In this article, we’ll deeply dive into the importance of isolating your GPU environment and explore how Genv, a fully open-source tool, can help you manage your GPU resources effectively with an example project.
Why does it matter?
Have you ever found yourself amid a data science project, juggling multiple tasks and deadlines, when suddenly, your run fails after eight hours of training just before it would have finished? Someone tried to run something on your GPU when it was already in use. It is stressful, decreases your team’s productivity, and causes delays in the projects.
Another reason why is the greediness of some manual allocation types. If you’re coming from a research direction, you’ve probably witnessed every data scientist having their own GPU. It’s all too common for teams to fall into the trap of manual allocation, with everyone hoarding their own under-desk GPU. But what happens when you see CUDA out of memory while someone else’s GPU sits there, twiddling its thumbs? It’s time to consider a better way to share those precious resources. Sharing is caring, so why not pool those resources together?
So, let’s roll up our sleeves and get our hands dirty in the world of GPU environment management with Genv!
Setup: pool them all, rule them all
If you have multiple machines with multiple GPUs, the first thing to do is pool all of them to share. By pooling multiple machines together and using Genv to manage them, you can create a powerful cluster tackling demanding deep-learning tasks. It is easily done by creating a text file with the IP address of the machines and then using Genv remote to see them.
$ cat hostfile.txt
gpu-server-1
gpu-server-2
$ genv remote --hostfile hostfile.txt devices
HOST TOTAL AVAILABLE
gpu-server-1 1 1
gpu-server-2 2 2
Total 3 devices with 3 available on 2 hosts
For this article, I use a single machine with two GPUs but keep in mind that Genv can be there wherever you see some GPUs — it doesn’t matter if it is a single or multiple GPU machine.
Example project
Let’s say we are three data scientists in a team. And guess what; we have limited resources. We have two GPUs instead of the traditional lab approach. Each data scientist/researcher is working on a different project. DS #1 wants to train a language model and needs a whole GPU. DS #2 needs to debug her code, and DS #3 is working on the visualization of the data to understand how to work on feature engineering in the next step. As you might have noticed, DS #2 and #3 don’t need a whole GPU since their tasks are not GPU-heavy tasks.
To make everyone happy and keep them productive without interruption due to a lack of resources, we will let DS #1 allocate one GPU and let #2 and #3 share the second GPU using fractions.
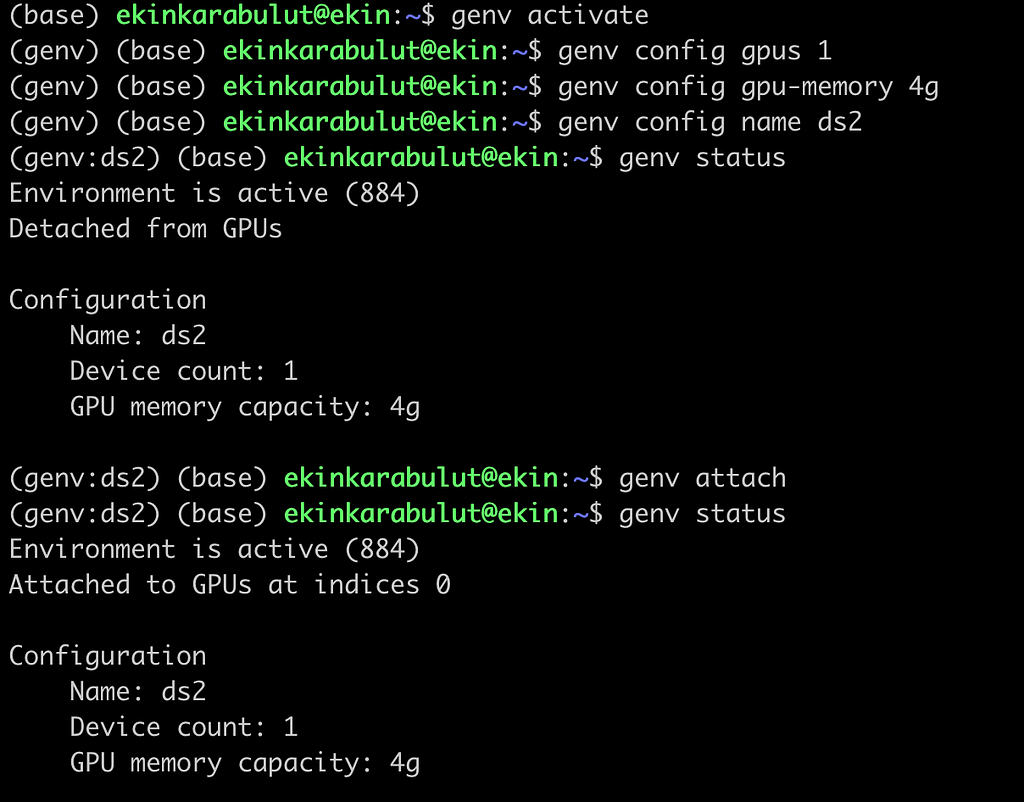
So first things first, we activate Genv, which means that we are in a Genv environment. So, we go ahead and configure one GPU for the DS 1. Since she needs one GPU, she is ready to go with training.

As shown in Figure 2, the whole GPU is ready for DS #1, and she can’t see the other one within her environment. Once she starts running her script, she will only see her processes, shown below:

So, we are left with only one GPU for DS #2 and DS #3. Since they don’t have any GPU-heavy training jobs, sharing one GPU will be enough for them. The second data scientist configures an environment with one GPU, but sets up 4 GBs of memory for himself. If he exceeds this limit, he will get a warning that he is above the limit. If you want to have a fair game as a system admin or data science lead, you can also enforce different types of limits, such as maximum memory capacity for each user or the maximum number of devices a user can attach to an environment. Genv will terminate the processes that do not respect the set rules.
When we run nvidia-smi now, you will see that the GPU memory is configured depending on the configured capacity.

After DS #3 makes the same configuration, everyone is set. A whole day of training, debugging, and visualization can start now.
When everyone starts working on their tasks, this is the utilization and process output we see outside of any environment (see Figure 5). As I mentioned, each data scientist will only see their processes and GPU — not each other. DS #1 allocated GPU 0, and she runs her job while utilizing nearly 90% of the GPU.
DS #2 and DS #3 allocated GPU 1 while utilizing 64% of the GPU. This shows us that giving one GPU per person is unnecessary in every scenario. If you are training on one GPU and not maxing out the utilization, increase your batch size — if you are debugging or running not heavy jobs, allocate a fraction of the GPU to max out the total utilization. What is sadder than seeing your GPU sitting idle? Seeing more than one GPU idle!

Now, let’s say DS #2 finished debugging her code and wants to start training a multi-class image classifier. This time, 4G is not enough. When he tries to allocate one whole GPU, he will receive an error message because all the GPUs are taken by others (instead of crashing all current training runs, his and others). He can now talk with others to see when they will be done so that he can start his training job. Another crisis is averted — no need to crash or slow down other’s runs.
A small disclaimer: As you can see, the rules of physics apply to Genv too. Even if you can use fractions of GPU or share them, if you don’t have enough resources to use them optimally, you don’t have much of an option except to buy new ones. However, using the ones you have very efficiently will increase everyone’s productivity and let you fully leverage the resources you currently have.
Conclusion
In today’s world, where data science is rapidly growing, access to GPU resources has become essential. However, the traditional method of allocating one GPU per data scientist is inefficient and costly. By pooling resources and sharing GPUs, teams can unlock the full potential of their hardware while minimizing idle resources. With tools like Genv, it’s easy to configure and monitor GPU usage and enforce limits to ensure fair access for all team members. By implementing these strategies, teams can boost productivity, reduce costs, and achieve greater results from their data science projects.
References
[4] Any question, feature request?: Link to Discord Server
[5] Genv at Open-Source Spotlight by Data Talks Club on Youtube
Want to Connect?
So if you're looking for someone to geek about data science and
pesky infrastructural bottlenecks, ping me on LinkedIn or on Discord.
Let's nerd out together over our love for data, GPUs, and all things AI.
Simplifying GPU Management for Data Scientists With Genv was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.