Dictionary structure, key eviction, hash table resize and rehash, and command execution

By now, I’ve already considered how Redis server starts up, how clients connect to it, and how Redis reads their commands and writes responses — both in a single-threaded and I/O threaded mode. Finally, I’ve made my way to the heart of Redis in this Redis Internals series. In this post, I’ll describe how its db engine, if I may call it so, is implemented. This is where Redis finally executes a command. Unlike I/O operations, like reading and parsing clients’ commands and writing responses, this is always done in a single main thread.
I won’t repeat the basic concepts that Redis relies upon, like epoll multiplexing mechanism, event loop, and non-blocking I/O. Instead, let’s get straight to where I left off when I described command parsing: command processing.
From a higher-level view, this logic looks like the following. A command is looked up, then Redis checks whether it can execute it for this client, and if it can, it does some chores and finally executes it.
Redis Looks Up a Command and Checks Whether It Can Execute It
First, Redis looks up a command. All commands are stored in a redisServer.commands dict, which is populated during start-up. Redis simply fetches a command from this dictionary. If it doesn’t exist, then it’s not executed, apparently.
Before executing a command, Redis runs some checks. There are lots of them, indeed. Here are some of those:
- Redis makes sure that a client has passed a correct number of arguments.
- Redis checks ACL whether a client is allowed to run this command.
- Given there are problems with saving data on disk, if a command is a write one and it’s sent by an ordinary client, not a master, then Redis rejects this command.
- Given healthy replicas, quantity and max allowed lag are configured. If there’re not enough of them, the write command can’t be run.
- Apparently, Redis can’t execute a write command from ordinary clients (non-master) on a read-only slave.
- Given stale reads are not allowed, if a command which doesn’t allow stale reads is run on a replica with a broken connection to a master, it’s rejected. You can tell that a command allows stale reads if it has a CMD_STALE flag — echo or hello, for instance. Most of them don’t, though.
- Given an RDB file or AOF file is loading right now if the current command isn’t loading-compatible, then it’s rejected. As always, this property is defined as a flag — CMD_LOADING, in this case. The same goes for asynchronous loading, which is available only on a replica during a catch-up with the master.
- If a replica wants to execute a read-, write-, or a replicable command (that is, almost any command), Redis master rejects it.
Besides those checks, Redis runs some mandatory procedures.
Overview of Structures Redis Uses for Data Storage
Each Redis database has two dictionaries. The first one is used for keys with expiry date. It’s redisDb.expires, and values stored there are expiration timestamps. The other is for client values; it’s redisDb.dict.
Each Redis dict has two hash tables. Both are implemented as a plain array; each slot, or bucket, contains a list of elements — in case of several elements’ hashes point at the same array index (this is known as a hash collision). Thus, it’s a classic hash table implementation, nothing special:
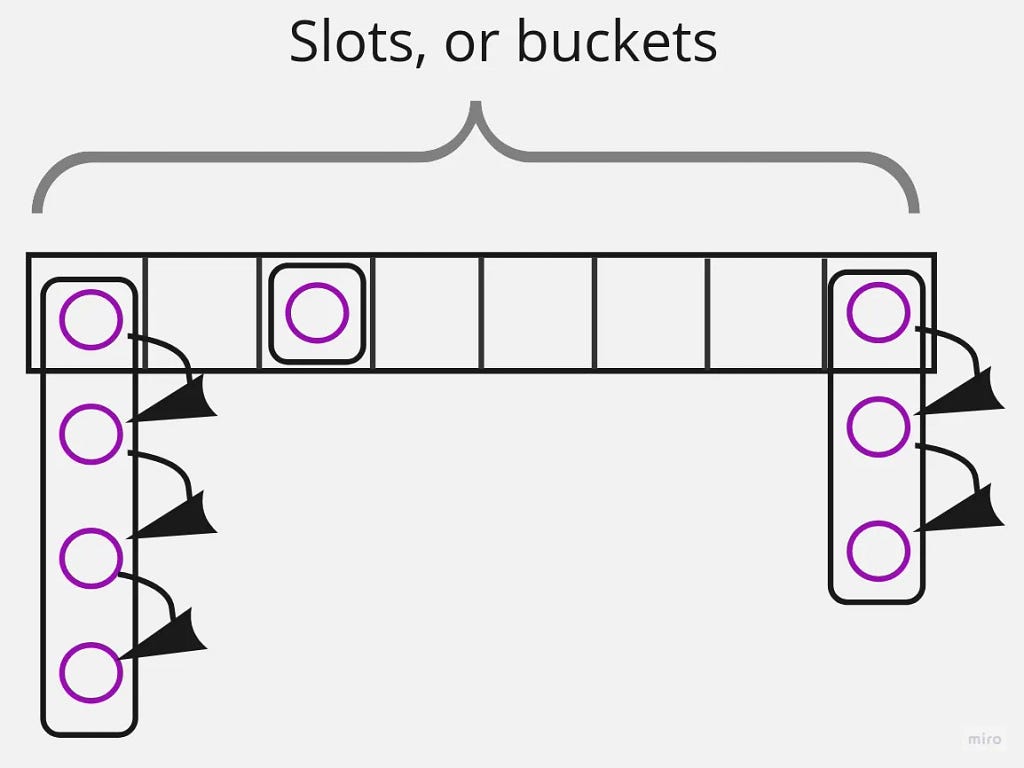
But why two of them? Just wait a sec, I’ll describe it in the next section.
Which data structures do hash tables contain? Each one stores linked lists of dictEntrys. The client key is in its key field. In the case of a dict struct, val field stores a redisObject which points to a client-set value. Most of the time, data that clients create and manipulate is stored exclusively there — in a redisObject.ptr pointer. expires dictionary stores client-defined expiration timestamps in the dictEntry.v.s64 field in milliseconds.
Here is an overall view of what a dictionary looks like:

Short Recap of Maintenance Procedures: Resize and Rehash of Dictionaries
When the number of elements in a hash table is high, the hash collision number increases. For instance, if a hash table has four buckets and four hundred elements, each bucket contains a list of about a hundred elements in length. Search time complexity effectively degrades to linear — O(n) instead of remaining constant — O(1).
That’s why Redis monitors a hash table size: if the number of elements becomes too high, a hash table is expanded. Having a sparse hash table is no good either: Redis has some procedures which iterate over a hash table. If it has a million buckets and just one element, most CPU cycles are wasted on iteration itself instead of doing some useful stuff. That’s why Redis shrinks sparse hash tables.
But it’s not an in-place algorithm. Expanding and rehashing all of the elements in one go would take a lot of time. That’s why Redis does that incrementally. First, it creates a new hash table with a suitable size. Then, it starts moving elements there from the first hash table gradually. In each cron iteration, Redis rehashes elements residing in one hundred consecutive buckets. Besides, while accessing or mutating a hash table, elements from a single bucket are rehashed. Redis remembers a bucket index where it left off; it’s stored in dict.rehashidx. All the previous buckets are guaranteed to be empty; all the subsequent ones probably contain some data:
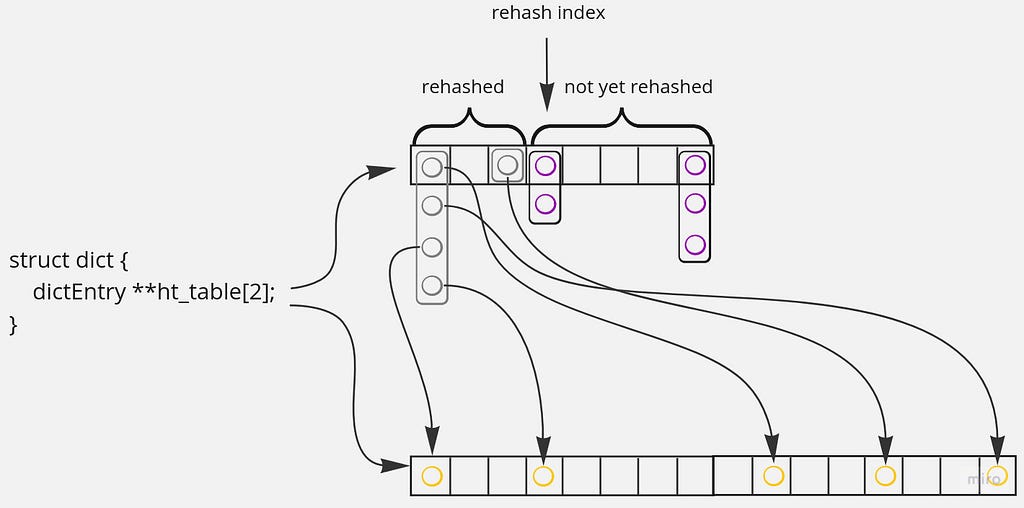
You can read implementation details of those processes in the first post of this series.
Redis Runs Some Regular Procedures Before Command Execution
Clients are evicted
Redis tracks how much memory each client consumes. Those clients are stored in a redisServer.client_mem_usage_buckets array. Clients are grouped in buckets by the amount of memory they occupy, and clients are stored in each bucket as a list. For instance, the first bucket stores clients, which take up to 32 kB. The second one stored clients taking up to 64 kB, and so on: memory threshold doubles with each subsequent bucket. The last one stores clients occupying more than 4 GB:

If a memory limit for how much memory clients can occupy is configured, Redis starts the eviction procedure. What is meant by client eviction is all memory associated with a client is freed. Redis starts with the last redisServer.client_mem_usage_buckets bucket, where the clients consuming the highest amount of memory are located. Before each new client’s eviction, Redis checks whether the total memory occupied by all clients fits into the specified limit. If it does, eviction stops. If not, the next client in the current bucket is evicted. If no clients are left in a current bucket, Redis moves to the next one. During a client eviction process, everything about a client is freed: read but not yet parsed commands, parsed commands with arguments, non-sent replies, watched keys, pubsub-related stuff. Besides, a connection socket is closed.
Keys are evicted
Key eviction is a process that runs when Redis occupies more memory than a configured limit, and it has to delete some keys. If a policy has a random in its name, it’s really nothing special: Redis just picks a random key in each database and deletes it. It’s quick and dirty.
But for all other policies, key eviction logic is more involved. From the higher level, each iteration looks like the following. Redis takes a sample of keys from the first database, then for each element, it calculates a property called “idle time” and finally inserts an element in a 16-sized pool in ascending order. Over time, the meaning of “idle time” broadened, but the crucial property remained: the greater the value, the more suitable it is for eviction. This process is repeated for each database. Finally, when Redis has a pool of keys from each database, the key with the highest “idle time” is deleted.
Don’t forget that this logic is executed in the context of running a command. Redis doesn’t aim to arrive within memory limits in one go — this can take too long. Instead, keys are evicted iteratively and within strict temporal boundaries. The maximum duration is configured by maxmemory-eviction-tenacity setting. When it’s lower or equal to ten, the specified value is a factor of 50 μs. When it’s higher than ten but lower than 100, each subsequent duration is 15% higher than the previous. maxmemory-eviction-tenacity equaling 100 effectively disables a time limit:

The default value is 10, so before executing a command, Redis performs key eviction for not much longer than 0.5 ms.
Now let’s look at one iteration of key eviction in more detail. I start with an eviction pool filling. The following logic is executed for each database, but keys are inserted in a single fixed-sized pool.
Redis gets a sample of keys from a current database
This is what dictGetSomeKeys() does. Strictly speaking, it doesn’t get a sample. In statistics, the sample is supposed to be random and filled independently. Instead, this procedure simply takes maxmemory-samples (by default, it’s five) subsequent elements starting with the one chosen randomly from a given dictionary.
Which dictionary is sampled? If a policy has a volatile in its name, it means that only keys with explicitly set expiry timestamps are eligible for eviction. In this case, an expires dictionary is sampled. Otherwise, dict is chosen.
When rehashing is not in progress, implementation is quite straightforward. Redis just picks a random bucket in a hash table and iterates it, collecting elements along the way. First, it iterates each bucket’s list. If it’s empty or there are no more elements in it, Redis moves to the next bucket. When it’s collected maxmemory-samples of them, it stops.
When rehashing is in progress, the logic is a bit more involved. Generally, it looks like the following. First, Redis generates a random index. Then, it goes to the first hash table’s bucket, which resides under this generated initial index and iterates all elements from that bucket’s list. Then, it goes to the second table’s bucket of the same index and gets all elements from there. Then, Redis repeats that with the subsequent index, and so on — until the necessary number of elements is collected. To illustrate this process, I’d like to consider one normal case and two more edge ones, in more detail.
Rehashing is in progress: the dictionary is expanding, and a random index is greater than a rehash index.
Let’s say a random index is 5:
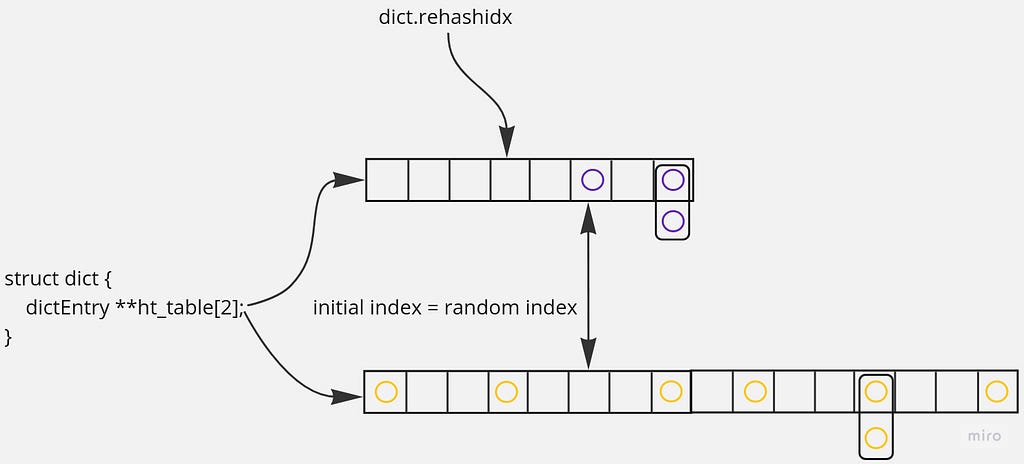
The iteration looks like this:
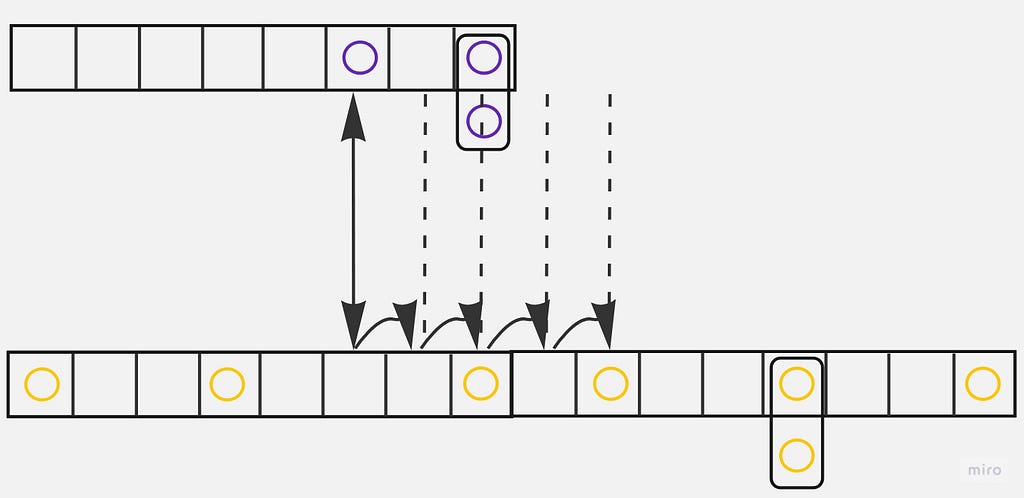
Here is what the resulting pool looks like:

Now, let’s move on to some more rare cases.
Rehashing is in progress: the dictionary is shrinking, and a random index is less than a rehash index but greater than the second hash table size.
Let’s say a random index is 4. In this case, an initial index is set to rehash index because all the buckets before the rehash index are empty:
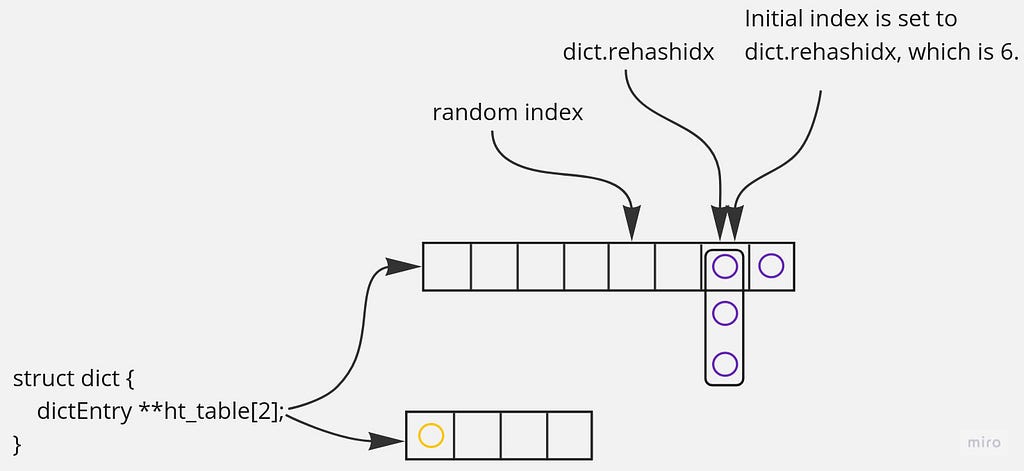
During pool population, only the larger table is iterated — the one that is being shrunk because an initial index is greater than the size of the second hash table:

As a result, there are only four items in a pool — this is less than what was asked. But there are no more items left.
Rehashing is in progress: the dictionary is expanding, and a random index is still less than a rehash index.
Let’s say a random index is 1:

In this case, Redis iterates through both hash tables but skips already rehashed buckets from the first hash table — they are empty anyway:
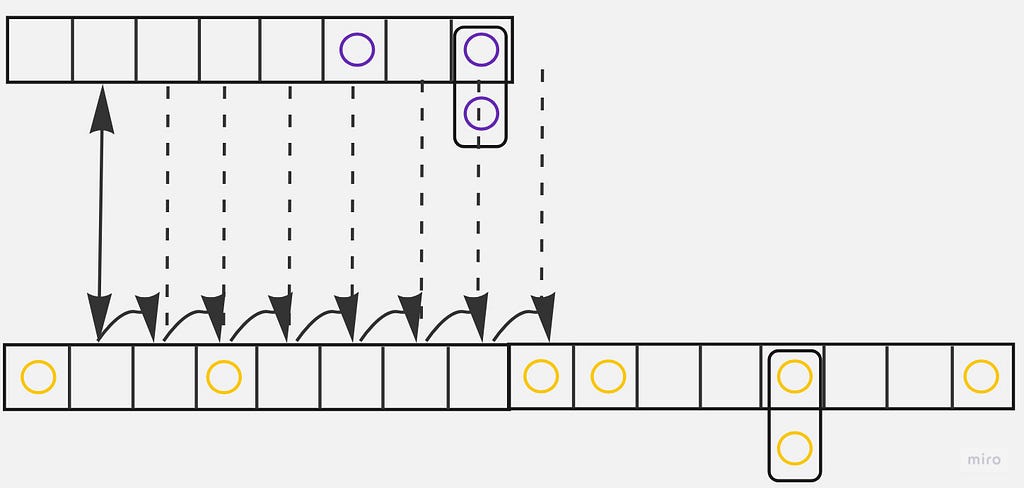
Here is the resulting pool:

After a pool is ready, Redis goes to the next part.
Redis sorts a pool
Then, Redis sorts a pool in an ascending idle time order. For different key eviction policies, “idle time” means different things, but it has a crucial property: the greater it is, the better candidate for eviction a corresponding item is.
Idle time in case of LRU policy
The “idle time” name was coined at times when the only policy implemented in Redis was the Last Recently Used. When it’s employed, the best candidate for eviction is the last recently used one, indeed. In this case, redisObject.lru stores LRU_BITS (which is 24) least significant bits of a timestamp when a corresponding key was last looked up:
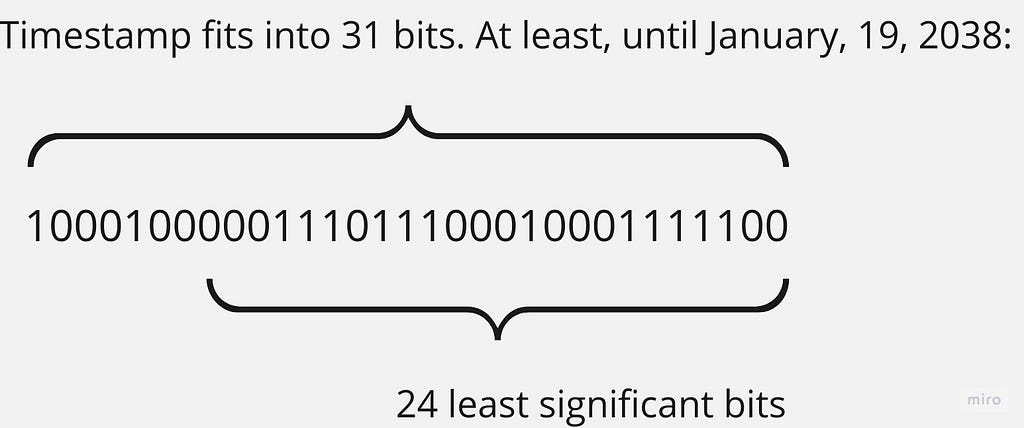
It means that this value wraps around every 194 days. In other words, Redis can’t tell the difference between the last lookup time of one day ago and 195 days ago. For most workloads, I think it’s OK though: if you have keys that are looked up that rarely, it’s not a problem to hit a database one or two times a year in case they got evicted.
In the case of LRU policy, the best candidate for eviction is the one used the least recently. In this case, “idle time” means what it is: a time interval when a current key has not been looked up:
idle = now() - dictEntry.val.lru
Let’s now move to how idle time is calculated when LFU is used.
Idle time in case of LFU policy
In this case, redisObject.lru stores a combination of when the key was last looked up, concatenated with a relative usage frequency:
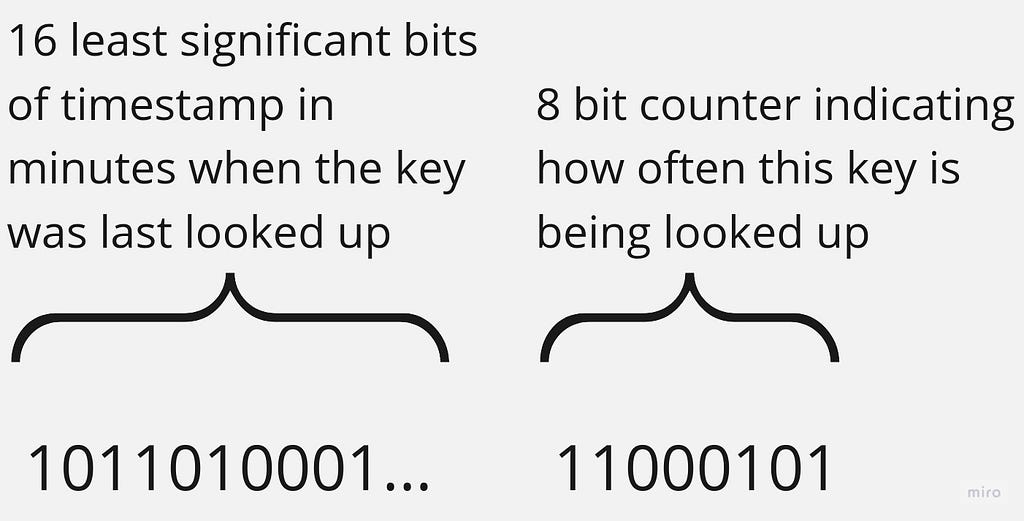
The last lookup time wraps around every 45-something days, which isn’t a problem still, I believe. Redis needs it to calculate key usage frequency; I’ll describe it in a few moments. The frequency itself is not a precisely calculated value reflecting a physical concept of frequency. We don’t need that. It’s enough for us if it just correlates with usage frequency so that it can be used for comparing with each other. Since it is just 8 bits, 0 is for the least frequency, and 255 is for the greatest one.
Now, how is it updated? It’s a three-step process. First, a counter is decreased proportionally to the time a corresponding key has not been looked up. That sounds natural: if a key was last looked up a month ago, its usage frequency is low. That’s what Redis stores the last lookup time for. Second, a counter is increased probabilistically: the greater a counter, the less likely it is to increase. Why so? Because we need a counter to fit in 8 bits, so we slower its increase rate. Third, a new timestamp in minutes is taken, and the 16 least significant bits are extracted and concatenated with a new counter.
How’s “idle time” calculated when this policy is in place? In the case of LFU, we need an inversed frequency so that the higher the frequency, the lower the “idle time,” so the less suitable this item is for eviction. The opposite is true: the lower the frequency, the higher the “idle time”, so the more suitable this item is for eviction. Thus, Redis extracts this frequency and subtracts it from its maximum possible value, 255:
idle = 255 - LFUDecrAndReturn(o);
Idle time in case of volatile-ttl policy
When this eviction policy is used, it is an expires dictionary, which is sampled. Keys there are ordinary client-set keys, but values are expiration timestamps. We invert them: the lower an expiration timestamp, the better it suits for eviction:
idle = ULLONG_MAX - (long)dictGetVal(de);
Redis removes a key with the highest “idle time”
By now, Redis has an ordered pool of elements. Then, Redis just picks the last element — the one with the highest “idle time”, and deletes it.
That’s pretty much it. Now Redis is ready to run a client command.
Redis Executes a Command
Finally, Redis runs a command. This boils down to invoking a redisCommandProc *proc field of a client’s parsed command. So, if you want to see a source code of some specific command, head to commands table, find there a command you’re interested in, and click on the eleventh argument. This procedure is an implementation of a command you’re looking for.
Generic flow of a command
It’s quite simple, actually. First, Redis finds an element in a dictionary with one of the procedures whose name starts with lookupKey…. Typically, it’s either lookupKeyWrite(), or lookupKeyRead(), or lookupKeyWriteOrReply(), or lookupKeyReadOrReply(). The difference between read and write procedures are that the latter deletes an expired element even on a read-only replica. …OrReply procedures add a reply in case the key is missing.
After an element is found, Redis runs whichever logic is implied by a command. That’s the core of a command. If it’s complicated enough, it’s often extracted into its own procedure. For instance, in the case of a simple get command, the found value is just wrapped in a reply and stored in a client struct for future sending. In the case of a zadd command, where Redis inserts each element a client sent in a sorted set, this logic is encapsulated in zsetAdd procedure, and so on. Just pick a command you’re interested in and dive into its implementation!
Key lookup
The majority of Redis commands first look up a passed key. Let’s consider this in more detail.
lookupKey…-family of procedures operate on a redisDb level: they all have it as a first argument. This is quite a high level of abstraction: there is no search logic itself. Instead, it’s outsourced to the dictFind procedure, which operates on dict-level. This procedure is a typical implementation of a hash table search logic, with some Redis specifics in case of rehash is in progress. First, Redis runs one step of it, and second, Redis checks both hash tables for a searched key. Besides, if rehash is in progress, Redis runs a rehash step on each data manipulation operation.
When dictFind returns a dictEntry and it exists, Redis checks whether this element has already expired. If it has, but a command is executed on a replica by a master, elements are never considered expired. Otherwise, unless a key was looked up with either lookupKeyWrite() or lookupKeyWriteOrReply(), it’s considered expired but not physically removed. Besides, if EXPIRE_AVOID_DELETE_EXPIRED is present, the current expired key is not evicted either. In all other cases, an expired key is deleted. As a special case, this includes a situation when a key has expired on a read-only replica, but it’s looked up with a …Write-family of procedures.
Finally, if a key has survived an expiration logic, its access time is updated depending on an eviction policy used. There are two exceptions for this. The first one is when a client explicitly specified that it doesn’t want to modify an access time. The second one is when there is currently a child process running. Why? When a child process is created through forking, it inherits access to the same data as the parent process.
This is made possible by the copy-on-write (CoW) technique, which is a mechanism implemented by the operating system. If either the parent or child process modifies shared data, a new memory page is copied, and the changes are visible only to the process that made the modification. This results in increased memory usage and potential performance overhead. That’s why Redis avoids performing maintenance tasks while a child process is running.
In closing
That’s it for this article and likely for this Redis Internals series. I’ve described some parts which were interesting to me, but of course, there are lots of cool features left that I haven’t touched.
Redis is an incredible piece of software: it’s extremely fast, well-designed, and its code is remarkably readable. I’ve had a really good time diving into it, and I encourage you to do it too.
Redis Internals: Redis Processes a Command was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.