The case when there are no I/O threads

In the previous article of the Redis Internals series, I described what happens on the Redis side when a client connects to it via TCP. Now, I’ll consider what happens when a client sends a command and receives a response. Please note that I won’t delve here into an implementation of how Redis retrieves or writes data — its db engine, if I may call it so.
This part is command specific, and I will consider a general way of figuring this out, with an example, in a future article. Instead, this article focuses on how Redis receives a request and writes a response when there are no I/O threads. It’s probably the shortest and easiest article in this series, but it is a foundation for a more sophisticated I/O threads mechanism. I will describe it in the next article.
This article relies heavily on a concept of event loop — Redis’ driving force behind executing commands. So, at the risk of repeating myself time and again, I’ll first skim through its main parts. If you’ve already read any of my previous articles, feel free to skip them and head right to the main part.
Recap of Redis Start-Up Process
Epoll instance
An epoll instance is a fundamental data structure within the Linux kernel, encompassing two crucial components: an interest list and a ready list. By adding a file descriptor to the interest list, also known as an epoll set, the epoll instance continuously monitors it asynchronously for events. Events signify changes in the state of a file descriptor, primarily involving two distinct alterations.
The first change occurs when a file descriptor becomes readable, indicating data availability for reading. Essentially, the file descriptor transitions from a not-ready state to a state ready for reading. The second alteration occurs when a file descriptor’s buffer has sufficient space to write data. In such scenarios, these file descriptors are commonly referred to as writable. Whenever any of these events occur, the epoll instance promptly adds the corresponding file descriptor to the ready list:
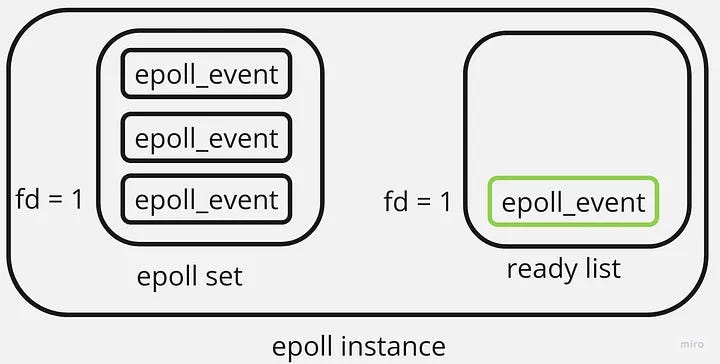
To retrieve the file descriptors that are currently ready for input/output operations, the epoll_wait() procedure can be invoked.
Epoll represents just one of several multiplexing mechanisms utilized to track the state of file descriptors asynchronously. In the context of Redis, when it is built on the Linux operating system, epoll serves as the chosen implementation.
Connection socket
During a startup, Redis creates listening sockets and registers them in an epoll instance for read events. Those listening sockets store all incoming client connection requests in an associated TCP buffer called an accept queue:
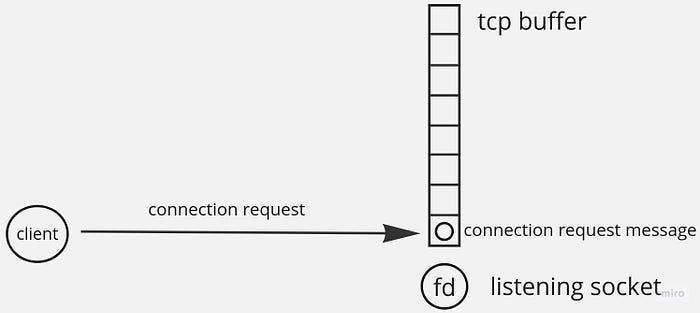
Redis accepts up to one thousand connection requests per single event loop iteration. As a result, each client has its own connection socket — the one with which a TCP connection is established. This connection socket receives its client’s commands:
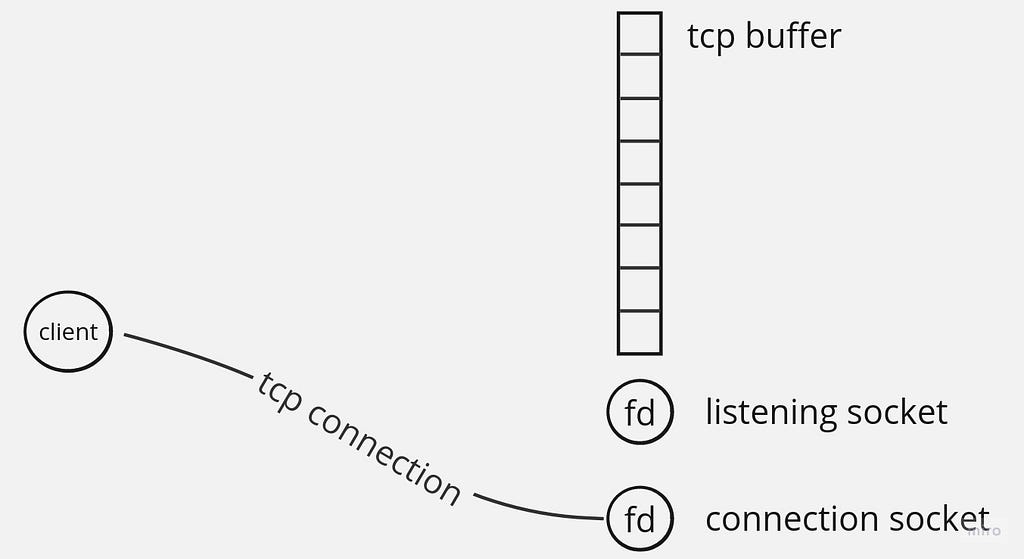
Each connected socket is also registered in an epoll instance for read events. When a client sends a command and it’s put in a connection socket’s receive queue, it means that a socket has just become readable and readQueryFromClient() is executed.
Event loop
The event loop represents a programming construct that builds upon a system’s multiplexing mechanism. Its essence lies in an infinite loop that continuously retrieves file descriptors whose state has undergone changes, indicating their readiness for read or write operations.
The event loop operates through a series of fundamental steps:
- Initially, you register interest in I/O events for each relevant file descriptor. In the case of using an epoll as the multiplexing mechanism, it’s epoll_ctl() system call. This action, often referred to as subscribing to an event, signifies detecting a change in a file descriptor’s state. For example, when a client sends a request and it’s received by a connection socket, the socket’s state alters, signaling the presence of newly arrived data awaiting an application’s reading.
- Subsequently, you await I/O events on the registered file descriptors by invoking a blocking system call specific to the chosen multiplexing mechanism. In the case of an epoll mechanism, this involves utilizing the epoll_wait() procedure. The blocking system call can either wait indefinitely until at least one event occurs or specify a timeout duration.
- Once the blocking system call from the previous step returns, you obtain the events that have transpired.
- Following that, you identify the type of event, such as a read or write event, and handle it accordingly by executing the associated callback function, typically referred to as a handler in Redis.
- Lastly, you continuously repeat these steps, perpetually monitoring and tracking the state of file descriptors asynchronously.
By adhering to this event loop pattern, developers can efficiently manage I/O operations and respond promptly to changes in file descriptor states.
Redis Receives a Command
That’s what readQueryFromClient() does. First, it checks whether a command should be parsed right away or should be postponed until IO threads do it. I’ll consider an IO threads scenario in the next article, so here, we have this mechanism disabled. Redis then reads a raw command data from a socket and stores it in a client’s query buffer. This is a piece of functionality involving a connection, and in such cases it’s implemented as a function pointer in ConnectionType struct. Here is an example of what a raw command data could look like if a client sent set a 12345:
*3 // this is a number of arguments
$3 // this is a length of the following lexeme -- a command, in this case
set // this is a command itself
$1 // this is a length of the first argument, in bytes
a
$5 // this is a length of the second argument, in bytes
12345;
This is a multi-bulk request format — a part of RESP, the default Redis protocol.
Then, Redis reads a client’s buffer and parses a command. All the heavy lifting is implemented in processMultibulkBuffer() procedure. It fills client’s argv field with parsed arguments. For instance, for the previous command, there are three of those: set, a, 12345.
Note that the first line of a multi-bulk command is always the number of arguments. Thus, Redis always knows whether an entire command was parsed. It might not be the case when, for example, a current command is really large, and it can’t fit within a single TCP segment. Or when a client sends multiple commands, and the last one, again, doesn’t make it in a TCP segment. And if epoll_wait() returns just before the second TCP segment arrives, and Redis gets a partial command.
It’s OK, though: the TCP stack of an underlying system will wait until it arrives, and Redis will find this out by calling epoll_wait() in the subsequent event loop iteration.
If an entire command is parsed, then Redis is ready to execute it. That’s what processCommandAndResetClient() does. Besides actually executing a command, it does some auxiliary bookkeeping stuff: resets client fields used for command parsing tracking, and updates some stats.
I will describe a command execution in one of my following articles.
Redis Writes a Response
Sending a reply to a client contains three logical parts:
- Redis adds a client to a server.clients_pending_write list
- Then, it constructs a reply in a specific format
- This reply is stored in a client structure
- In the subsequent event loop iteration, each pending reply is written asynchronously in a connection socket.
Now, let’s consider each part in more detail.
Redis reply is constructed
Reply formatting is implemented in an addReply* set of procedures located in networking.c file. It could be an addReplyBulk procedure, for instance. First, a reply length is added. It’s followed by a response body, and finally, by a new line.
For example, if a key a equals 12345, when a client gets it, the reply looks like that:
$5
123456
// this is a new line
Redis reply is stored in a client
Internally, this reply can be stored in a fixed-size buffer and, if it doesn’t fit there entirely, in a reply list. If a reply length is under 16 kB so that it fits in a reply buffer, it’s stored only in a buf field of a client struct. Otherwise, the remaining part is stored in a reply field. It is a linked list. If its current tail has some spare space, reply is appended to its buffer. After that, the remaining part is stored in a new list item which becomes the new tail. Its minimal size is 16 kB, and the maximum size is unbounded.
Why does Redis need this mechanism? Why can’t everything be stored in a dynamic-sized buffer? Its size can be increased and decreased with each new reply indeed. Well, I’m not a systems developer, but I can think of the following reasons:
- Memory reallocation is not cheap, especially when applied on the Redis scale. For instance, you can have thousands of clients receiving responses at about the same time. It’s thousands of realloc-like procedures in a single event loop iteration. Given a very rough estimate of a single event loop iteration is about one millisecond (in reality, it can be two or even three orders of magnitude less), this can add up to millions of memory reallocations per second. This can affect Redis’ performance.
- Frequent memory reallocations lead to memory fragmentation. Although Redis has a built-in way to mitigate it, it’s better to avoid it altogether.
- Memory allocation and its subsequent freeing is cheaper than two reallocation calls. Each reallocation involves copying the existing data to a new memory block of a different size, which can have a time complexity of O(n), where n is the size of the data being reallocated. Meanwhile, free() procedure has a constant time complexity, typically O(1). It only releases the memory without any additional CPU or memory overhead.
So that’s why Redis uses a fixed-size 16 kB buffer which, on the one hand, is enough for most replies and, on the other, is not too much of an overhead.
Redis adds a client to a clients_pending_write list
Before setting a reply, Redis makes sure that a client is in a server.clients_pending_write list. This behavior is implemented in a prepareClientToWrite() procedure. Besides a few cases, Redis checks whether a client doesn’t have a stored reply (if it does, it means that this client is already in a pending write list), and it is currently not in an IO thread. If those two conditions are satisfied, putClientInPendingWriteQueue() is executed, which finally adds a client wrapped into a listNode in a server.clients_pending_write list.
Short recap
I think now it’s a good time to remind you of what a higher-level command execution looks like:
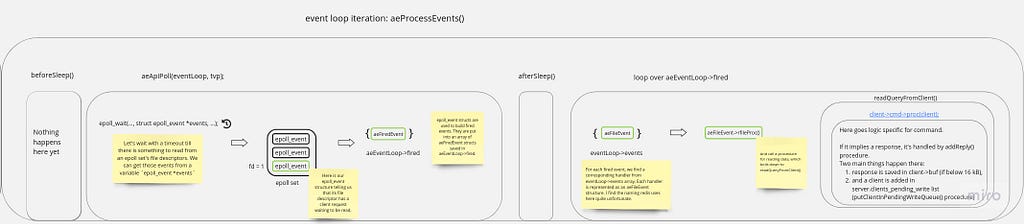
First, new events are received through epoll_wait() procedure. Then, they are looped through, and for each read event, a command is parsed, executed, and a reply is built. Note that it’s not yet sent to a client — it occurs on the subsequent event loop iteration in beforeSleep() procedure. Let’s get right into it.
Redis reply is sent to a client
This logic consists of two logical parts. The first one is where Redis sends a response. The second one is where Redis registers a connection socket for write events. This is needed when a response was sent only partially. It can occur when, for instance, a socket is blocked for writing because its send buffer is full.
This logic is implemented in a handleClientsWithPendingWritesUsingThreads() procedure. The name might trick you into thinking that IO threads are involved somehow; actually, this is not necessarily a case. IO threads machinery runs only if this behavior is enabled in settings and if Redis considers this whole enterprise worthwhile. If either of those conditions fail, responses are delivered in a the main thread. This logic is implemented in a handleClientsWithPendingWrites() procedure. Its implementation is quite straightforward. Redis takes all the clients with pending writes (as I’ve written above, they are stored in a server.clients_pending_write list) and calls writeToClient() for each one. As you can guess, this is a procedure that sends a response to a client.
Redis sends a response
writeToClient has a limit of how much data Redis can write to a socket. Why? There are specific scenarios where the likelihood of connection socket blocking is lower than the average. In such cases, Redis can spend too much time serving a response to a single client. Think of a user who connects to Redis through a loopback interface locally. I can hardly imagine network congestion there. Besides, the bandwidth is extremely high.
Another example might be when a client skips the TCP stack altogether and connects to Redis with Unix Domain Sockets. Despite their buffer capacity is generally lower, the data written in them is copied between processes. Thus, in both scenarios, it might take a while for connection sockets to block. Hence, Redis serves no more than NET_MAX_WRITES_PER_EVENT bytes for a client in each event loop iteration.
There are two procedures used for actual data writing. Ordinary write() is used for data stored in a c->buf buffer. It’s a contiguous block of memory, and the write procedure works with exactly this kind of data.
But for a reply list, writev() is used. Why? Because linked list occupies a non-contiguous memory region. And that’s exactly what writev is used for. Thus, Redis iterates through each item and constructs an array of scattered iovec structs. Then, it’s written atomically in a connection socket. So, if Redis had used a write procedure, it would have had two options. The first one is issuing several write calls, which is costly: generally, the fewer system calls, the better. The second option is to copy all reply list items’ contents into a single contiguous memory block and issue a single write. I don’t think the second option is subpar to a writev approach, though.
Each of those write procedures returns several bytes written, and if it’s zero, an errno is filled with an error code explaining what happened. Some of them indicate a permanent error; others are retryable. EAGAIN is among the latter. It means a connection socket’s send buffer is full, and writing gets blocked. In other words, as the comment goes, it’s Try again.
Redis subscribes to write events in a connection socket
Finally, Redis checks whether there is some data left for a current client to be sent. As I’ve already mentioned, there are at least two scenarios when this can occur. The first one is hitting a NET_MAX_WRITES_PER_EVENT limit, and the second one is an error code returned from a write procedure — most notably, an EAGAIN. In either case, Redis registers a connection socket for write events. It means that when it becomes writable, Redis will figure that out with an epoll_wait procedure and send the remaining part of a response with a previously set write handler.
It’s represented with a sendReplyToClient procedure. It boils down to simply calling a writeToClient() — an exact same procedure that was issued during the first attempt, in a handleClientsWithPendingWrites. The only difference is that the write handler is installed, as implied by the second argument. In this case, when all the data is finally sent, Redis unsubscribes from write events for a current connection socket.
Here is how response sending looks like when it can’t get sent in a single write call:

This is a very high-level view. Check out this Miro board for details.
In Closing
In short, an entire command execution flow looks like that. In the first event loop iteration, a command is parsed, executed, and a response is saved. In the subsequent iteration’s beforeSleep procedure, Redis sends this response to a client. If it’s sent only partially for some reason, Redis registers a current client’s connection socket for write events. When it fires, a socket becomes writable, and Redis writes the remaining part of a response. This process is repeated until an entire response is sent. When it’s done, Redis unsubscribes from write events.
Stay tuned. The next article is about how IO threads work.
Redis Internals: Client Sends a Command and Receives a Response was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.