A practice to ingest the data in real-time from Kafka cluster to the Hadoop/HDFS platform

It is quite a common requirement to ingest the data from the microservice cluster to the big data platform for further analytics. Depending on the data platform architecture, it can ingest data to either the object store(s3) or Hadoop/HDFS
Data Architecture
Hadoop/HDFS based
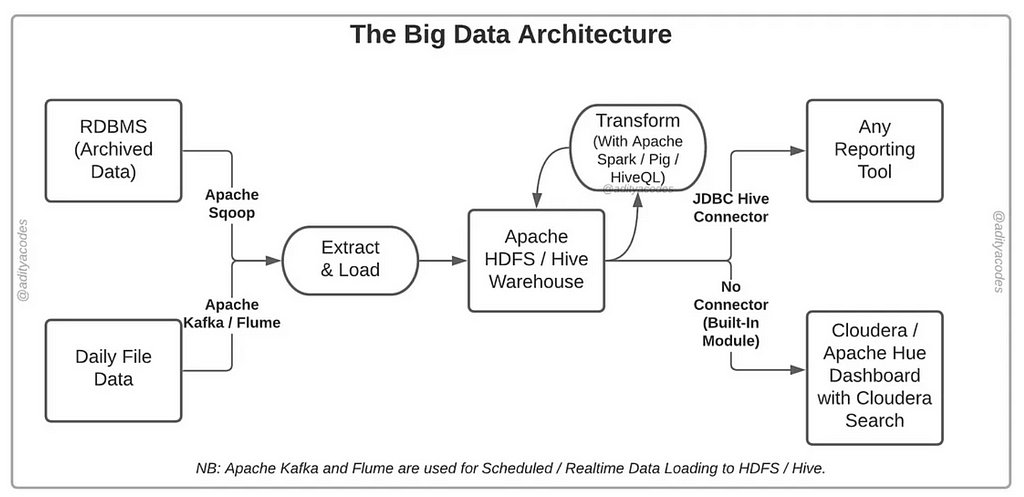
This tech stack is a bit outdated, but lots of companies are still using it nowadays.
Object Store(S3) based
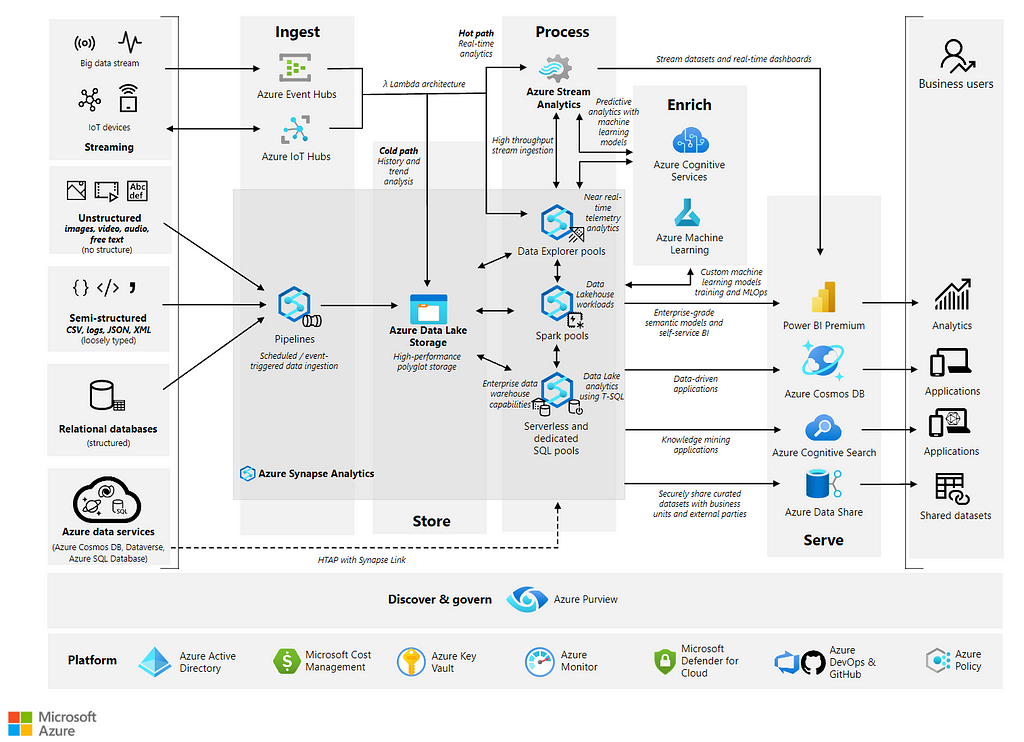
object store/s3 as data lake is more popular when the data platform is deployed on the public cloud. No matter which deployment, there is not much difference in the data-sink(ingestion to data platform) part. Both of them will use Kafka-Connect to ingest data to data platform. I will give an example based on the Hadoop solution.
Start the environment
I created a docker-compose file run Hadoop and Kafka. refer to
cp-all-in-one/cp-all-in-one-community at 7.5.0-post · confluentinc/cp-all-in-one
and https://github.com/big-data-europe/docker-hadoop
docker-compose.yaml
version: "3"
services:
namenode:
image: bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8
container_name: namenode
restart: always
ports:
- 9870:9870
- 9000:9000
volumes:
- hadoop_namenode:/hadoop/dfs/name
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
datanode:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
container_name: datanode
restart: always
volumes:
- hadoop_datanode:/hadoop/dfs/data
environment:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env
resourcemanager:
image: bde2020/hadoop-resourcemanager:2.0.0-hadoop3.2.1-java8
container_name: resourcemanager
restart: always
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864"
env_file:
- ./hadoop.env
nodemanager1:
image: bde2020/hadoop-nodemanager:2.0.0-hadoop3.2.1-java8
container_name: nodemanager
restart: always
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
env_file:
- ./hadoop.env
historyserver:
image: bde2020/hadoop-historyserver:2.0.0-hadoop3.2.1-java8
container_name: historyserver
restart: always
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
volumes:
- hadoop_historyserver:/hadoop/yarn/timeline
env_file:
- ./hadoop.env
zookeeper:
image: confluentinc/cp-zookeeper:7.5.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-server:7.5.0
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "9092:9092"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker:29092
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
schema-registry:
image: confluentinc/cp-schema-registry:7.5.0
hostname: schema-registry
container_name: schema-registry
depends_on:
- broker
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'broker:29092'
SCHEMA_REGISTRY_LISTENERS: http://0.0.0.0:8081
connect:
image: confluentinc/cp-kafka-connect:latest
hostname: connect
container_name: connect
depends_on:
- zookeeper
- broker
- schema-registry
ports:
- 8083:8083
environment:
CONNECT_BOOTSTRAP_SERVERS: 'broker:29092'
CONNECT_REST_ADVERTISED_HOST_NAME: connect
CONNECT_REST_PORT: 8083
CONNECT_GROUP_ID: compose-connect-group
CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000
CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_KEY_CONVERTER: io.confluent.connect.avro.AvroConverter
CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter
CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CLASSPATH: /usr/share/java/monitoring-interceptors/monitoring-interceptors-7.5.0.jar
CONNECT_PRODUCER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor"
CONNECT_CONSUMER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor"
CONNECT_LOG4J_ROOT_LOGLEVEL: "INFO"
CONNECT_LOG4J_LOGGERS: "org.apache.kafka.connect.runtime.rest=WARN,org.reflections=ERROR"
CONNECT_PLUGIN_PATH: '/usr/share/java,/usr/share/confluent-hub-components/,/connectors/'
command:
- sh
- -exc
- |
confluent-hub install --no-prompt --component-dir /usr/share/confluent-hub-components/ confluentinc/kafka-connect-hdfs:latest
confluent-hub install --no-prompt --component-dir /usr/share/confluent-hub-components/ confluentinc/kafka-connect-datagen:latest
exec /etc/confluent/docker/run
control-center:
image: confluentinc/cp-enterprise-control-center:7.5.0
hostname: control-center
container_name: control-center
depends_on:
- broker
- schema-registry
- connect
- ksqldb-server
ports:
- "9021:9021"
environment:
CONTROL_CENTER_BOOTSTRAP_SERVERS: 'broker:29092'
CONTROL_CENTER_CONNECT_CONNECT-DEFAULT_CLUSTER: 'connect:8083'
CONTROL_CENTER_KSQL_KSQLDB1_URL: "http://ksqldb-server:8088"
CONTROL_CENTER_KSQL_KSQLDB1_ADVERTISED_URL: "http://localhost:8088"
CONTROL_CENTER_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
CONTROL_CENTER_REPLICATION_FACTOR: 1
CONTROL_CENTER_INTERNAL_TOPICS_PARTITIONS: 1
CONTROL_CENTER_MONITORING_INTERCEPTOR_TOPIC_PARTITIONS: 1
CONFLUENT_METRICS_TOPIC_REPLICATION: 1
PORT: 9021
CONTROL_CENTER_CONNECT_HEALTHCHECK_ENDPOINT: '/connectors'
ksqldb-server:
image: confluentinc/cp-ksqldb-server:7.5.0
hostname: ksqldb-server
container_name: ksqldb-server
depends_on:
- broker
- connect
ports:
- "8088:8088"
environment:
KSQL_CONFIG_DIR: "/etc/ksql"
KSQL_BOOTSTRAP_SERVERS: "broker:29092"
KSQL_HOST_NAME: ksqldb-server
KSQL_LISTENERS: "http://0.0.0.0:8088"
KSQL_CACHE_MAX_BYTES_BUFFERING: 0
KSQL_KSQL_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
KSQL_PRODUCER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor"
KSQL_CONSUMER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor"
KSQL_KSQL_CONNECT_URL: "http://connect:8083"
KSQL_KSQL_LOGGING_PROCESSING_TOPIC_REPLICATION_FACTOR: 1
KSQL_KSQL_LOGGING_PROCESSING_TOPIC_AUTO_CREATE: 'true'
KSQL_KSQL_LOGGING_PROCESSING_STREAM_AUTO_CREATE: 'true'
ksqldb-cli:
image: confluentinc/cp-ksqldb-cli:7.5.0
container_name: ksqldb-cli
depends_on:
- broker
- connect
- ksqldb-server
entrypoint: /bin/sh
tty: true
ksql-datagen:
image: confluentinc/ksqldb-examples:7.5.0
hostname: ksql-datagen
container_name: ksql-datagen
depends_on:
- ksqldb-server
- broker
- schema-registry
- connect
command: "bash -c 'echo Waiting for Kafka to be ready... &&
cub kafka-ready -b broker:29092 1 40 &&
echo Waiting for Confluent Schema Registry to be ready... &&
cub sr-ready schema-registry 8081 40 &&
echo Waiting a few seconds for topic creation to finish... &&
sleep 11 &&
tail -f /dev/null'"
environment:
KSQL_CONFIG_DIR: "/etc/ksql"
STREAMS_BOOTSTRAP_SERVERS: broker:29092
STREAMS_SCHEMA_REGISTRY_HOST: schema-registry
STREAMS_SCHEMA_REGISTRY_PORT: 8081
rest-proxy:
image: confluentinc/cp-kafka-rest:7.5.0
depends_on:
- broker
- schema-registry
ports:
- 8082:8082
hostname: rest-proxy
container_name: rest-proxy
environment:
KAFKA_REST_HOST_NAME: rest-proxy
KAFKA_REST_BOOTSTRAP_SERVERS: 'broker:29092'
KAFKA_REST_LISTENERS: "http://0.0.0.0:8082"
KAFKA_REST_SCHEMA_REGISTRY_URL: 'http://schema-registry:8081'
volumes:
hadoop_namenode:
hadoop_datanode:
hadoop_historyserver:
hadoop.env
CORE_CONF_fs_defaultFS=hdfs://namenode:9000
CORE_CONF_hadoop_http_staticuser_user=root
CORE_CONF_hadoop_proxyuser_hue_hosts=*
CORE_CONF_hadoop_proxyuser_hue_groups=*
CORE_CONF_io_compression_codecs=org.apache.hadoop.io.compress.SnappyCodec
HDFS_CONF_dfs_webhdfs_enabled=true
HDFS_CONF_dfs_permissions_enabled=false
HDFS_CONF_dfs_namenode_datanode_registration_ip___hostname___check=false
YARN_CONF_yarn_log___aggregation___enable=true
YARN_CONF_yarn_log_server_url=http://historyserver:8188/applicationhistory/logs/
YARN_CONF_yarn_resourcemanager_recovery_enabled=true
YARN_CONF_yarn_resourcemanager_store_class=org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore
YARN_CONF_yarn_resourcemanager_scheduler_class=org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
YARN_CONF_yarn_scheduler_capacity_root_default_maximum___allocation___mb=8192
YARN_CONF_yarn_scheduler_capacity_root_default_maximum___allocation___vcores=4
YARN_CONF_yarn_resourcemanager_fs_state___store_uri=/rmstate
YARN_CONF_yarn_resourcemanager_system___metrics___publisher_enabled=true
YARN_CONF_yarn_resourcemanager_hostname=resourcemanager
YARN_CONF_yarn_resourcemanager_address=resourcemanager:8032
YARN_CONF_yarn_resourcemanager_scheduler_address=resourcemanager:8030
YARN_CONF_yarn_resourcemanager_resource__tracker_address=resourcemanager:8031
YARN_CONF_yarn_timeline___service_enabled=true
YARN_CONF_yarn_timeline___service_generic___application___history_enabled=true
YARN_CONF_yarn_timeline___service_hostname=historyserver
YARN_CONF_mapreduce_map_output_compress=true
YARN_CONF_mapred_map_output_compress_codec=org.apache.hadoop.io.compress.SnappyCodec
YARN_CONF_yarn_nodemanager_resource_memory___mb=16384
YARN_CONF_yarn_nodemanager_resource_cpu___vcores=8
YARN_CONF_yarn_nodemanager_disk___health___checker_max___disk___utilization___per___disk___percentage=98.5
YARN_CONF_yarn_nodemanager_remote___app___log___dir=/app-logs
YARN_CONF_yarn_nodemanager_aux___services=mapreduce_shuffle
MAPRED_CONF_mapreduce_framework_name=yarn
MAPRED_CONF_mapred_child_java_opts=-Xmx4096m
MAPRED_CONF_mapreduce_map_memory_mb=4096
MAPRED_CONF_mapreduce_reduce_memory_mb=8192
MAPRED_CONF_mapreduce_map_java_opts=-Xmx3072m
MAPRED_CONF_mapreduce_reduce_java_opts=-Xmx6144m
MAPRED_CONF_yarn_app_mapreduce_am_env=HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/
MAPRED_CONF_mapreduce_map_env=HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/
MAPRED_CONF_mapreduce_reduce_env=HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/
Configuration steps
Create a Kafka topic
open localhost:9021 , Click Add topic
create topic data-sink-hdfs
Add a connector
open localhost:9021 then goto HOME/Connect-Cluster/Connectors
add a new connector
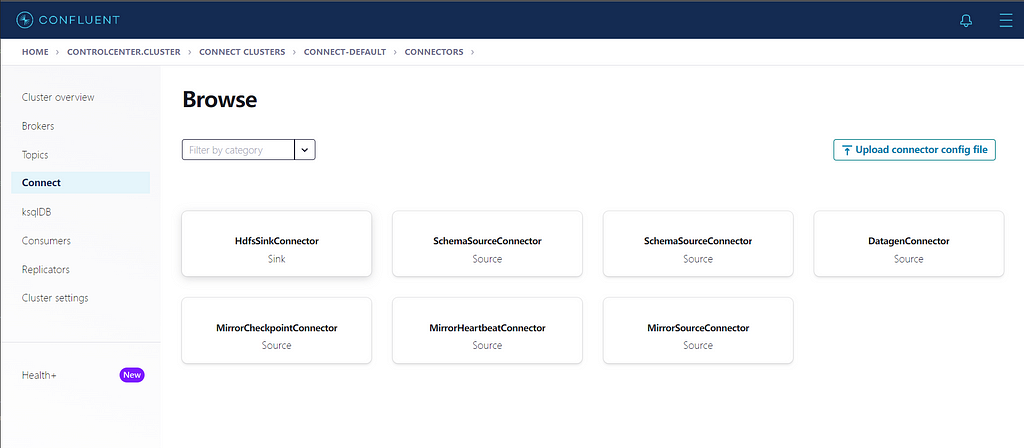
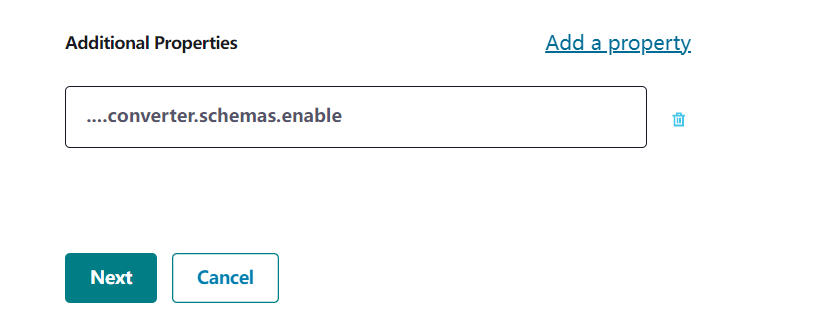
in this case we choose HdfsSinkConnector, and configure the connector as below. “key.converter.schemas.enable” and “value.converter.schemas.enable” are additional property that needs to be added at the bottom of the page
{
"name": "HdfsSinkConnectorConnector_0",
"config": {
"key.converter.schemas.enable": "false",
"value.converter.schemas.enable": "false",
"name": "HdfsSinkConnectorConnector_0",
"connector.class": "io.confluent.connect.hdfs.HdfsSinkConnector",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"topics": "data-sink-hdfs",
"hdfs.url": "hdfs://namenode:9000", # hostname, see docker-compose.yaml
"flush.size": "1"
}
}
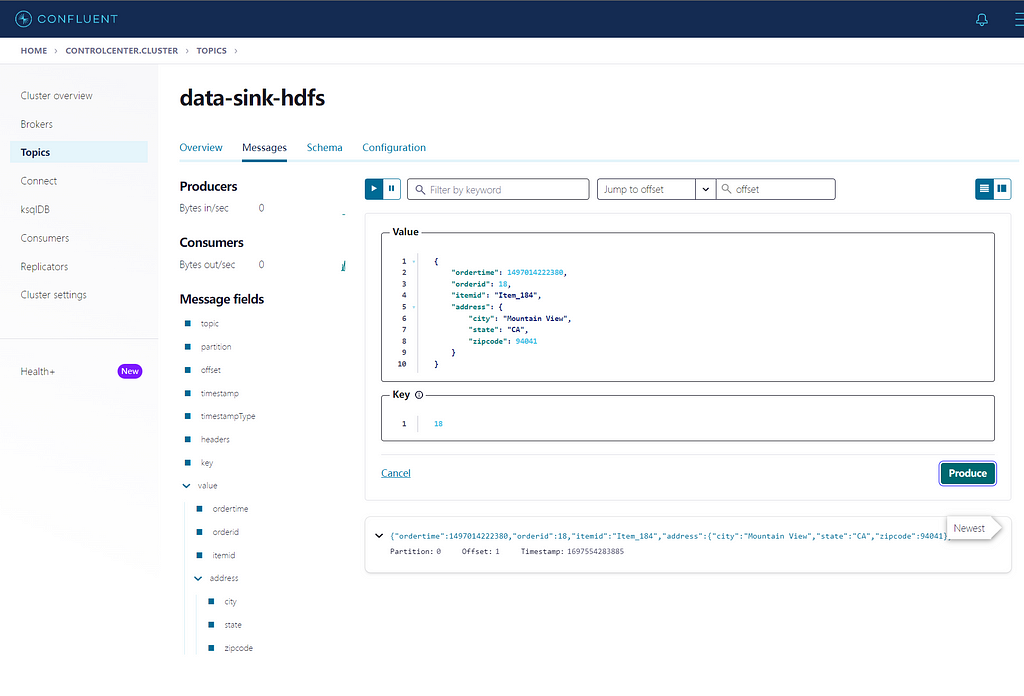
Test
produce a message
docker attach to namenode then check
docker exec -it namenode bash
root@f3ab6c37360e:/# hadoop fs -ls /
Found 3 items
drwxr-xr-x - appuser supergroup 0 2023-10-17 14:51 /logs
drwxr-xr-x - root supergroup 0 2023-10-16 15:42 /rmstate
drwxr-xr-x - appuser supergroup 0 2023-10-17 14:51 /topics
# /topics is the default destination
hadoop fs -ls /topics/data-sink-hdfs/partition=0
Found 3 items
-rw-r--r-- 3 appuser supergroup 1048 2023-10-17 14:51 /topics/data-sink-hdfs/partition=0/data-sink-hdfs+0+0000000000+0000000000.avro
-rw-r--r-- 3 appuser supergroup 1048 2023-10-17 14:51 /topics/data-sink-hdfs/partition=0/data-sink-hdfs+0+0000000001+0000000001.avro
-rw-r--r-- 3 appuser supergroup 1046 2023-10-17 15:06 /topics/data-sink-hdfs/partition=0/data-sink-hdfs+0+0000000002+0000000002.avro
# we produce 3 messages
In the next article, I will explore how to save the message in parquet format and use data visualization tools to query on parquet file.
reference
- for hadoop docker, refer to this https://github.com/big-data-europe/docker-hadoop
- for kafka docker yaml, refer to https://github.com/confluentinc/cp-all-in-one/tree/7.5.0-post/cp-all-in-one-community
- All the files I used are here
Happy Coding!
Real-Time Message Ingestion to Big Data Platform was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.