Efficiently Monitor RAM and GPU VRAM simultaneously with a single powerful function Decorator!

1. Why profile memory usage?
Introduction
While the specific motivations for memory profiling in your code application may vary, the ultimate goal is always to enhance its speed and robustness. Here are some memory patterns that are useful to detect:
- Memory Leak:
The memory consumption is growing over time, which makes the application slow down and eventually crash. It often comes from an improper memory management that fails to de-allocate memory that was dynamically allocated. - Unwanted Memory Allocation:
A given function is allocating a lot of memory even-though it shouldn’t. For instance, this can happen if you inadvertently use the copy constructor instead of the move constructor without realizing it. - Memory Peak:
This is the maximum memory consumption that was required during the runtime. In resource-constrained environments, the available memory ceiling is often restricted and might fall short of meeting your application’s requirements.
Don’t forget the GPU
When discussing memory constraints in a runtime application, it’s essential to distinguish between two specific types of memory:
- RAM (Random Access Memory):
This is the general-purpose system memory of a computer, used to temporarily store data and program instructions for fast access by the CPU during computing tasks. - VRAM (Video Random Access Memory):
This is the memory used by Graphics Processing Units (GPUs) to efficiently manage and process graphical data, playing a pivotal role in accelerating tasks such as deep learning, gaming, and multimedia applications.
Resource-constrained environments
In Computer Vision projects, the risk of running out of memory is prevalent due to the memory-intensive nature of image and video processing. The complex algorithms and deep learning models, along with large datasets, can overload the memory. Effective memory management and hardware configurations are crucial to prevent such issues.
The screenshot below shows the memory consumption (RAM) when an application ran out of of memory and got killed. This is precisely the scenario we aim to prevent when conducting memory profiling.
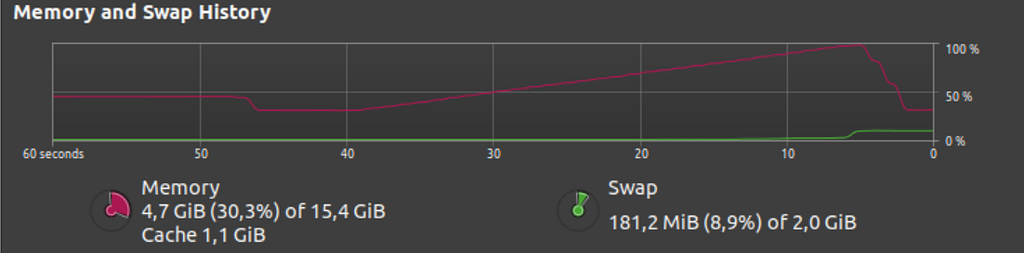
Here are possible causes of an Out-Of-Memory error:
- Too many memory-intensive threads launched simultaneously.
Have you ever tried compiling with “make -j,” using all the available threads? You’ll often witness your PC freeze due to memory depletion. - Heavy Deep Learning Model that doesn’t fit in the VRAM.
- The entire dataset is loaded in memory, instead of processing it in batches.
- Memory is never de-allocated.

2. Choose the tool’s purpose
Goal
There isn’t a one-size-fits-all memory profiling tool. The choice depends on what you want to observe, as explained in the previous section.
In my case, I have a pipeline made of algorithmic blocks and I’d like to know the memory peak of each block in terms of RAM and VRAM.
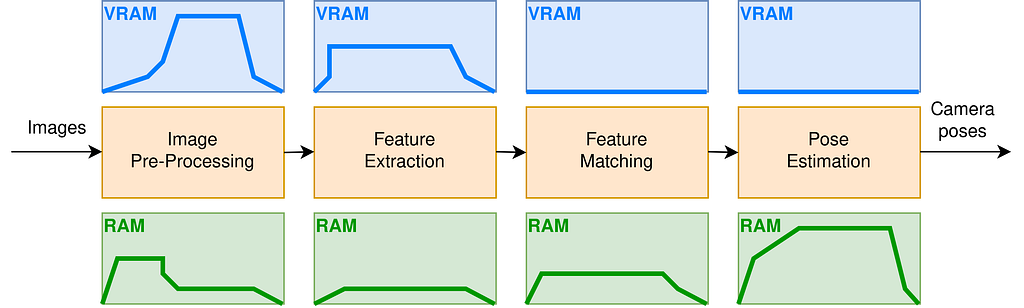
For instance, taking into consideration the peak RAM and VRAM consumption of your pipeline is essential when choosing an Amazon EC2 instance. It ensures that you can align your application’s memory needs with the available resources of the selected EC2 instance, resulting in a well-balanced and cost-effective computing environment.
Existing memory profiling tools
There are amazing memory profiling tools available for free, like the two below:
- KDE heaptrack: An open-source memory profiler designed for tracking heap memory allocations and de-allocations in Linux-based software development.
- memory-profiler: A Python module for monitoring memory consumption of a process as well as line-by-line analysis.
Data collected by heaptrack might be too low-level in my case, since I’ve already identified in my pipeline the scopes that I want to profile.
The memory-profiler library provides an easy-to-use @profile decorator. Even though it profiles only RAM, we will draw inspiration from its logic to develop our own version that also monitors VRAM.
Let’s see how to implement our custom profiling decorator that tracks the peak RAM and VRAM consumption of a given function. (This will be a nice addition to the time profiling introduced in a previous Medium article Profiling and Multiprocessing in Python )

3. Basic Memory utilities
Psutil
The Python library psutil (process and system utilities) is used to retrieve information on running processes and system utilization.
The code below illustrates how to use it to retrieve (in bytes):
- The total RAM available, i.e. the memory ceiling
- The RAM used by the entire platform
- The RAM is used by the current process only. The resident set size (RSS) is the portion of memory occupied by a process that is held in RAM
Nvidia-smi
If you’ve had prior experience with a GPU, you’ve certainly encountered the challenge of installing the right Nvidia drivers. Once everything is correctly set up, the nvidia-smi command-line tool provides real-time monitoring and management of Nvidia GPU devices.
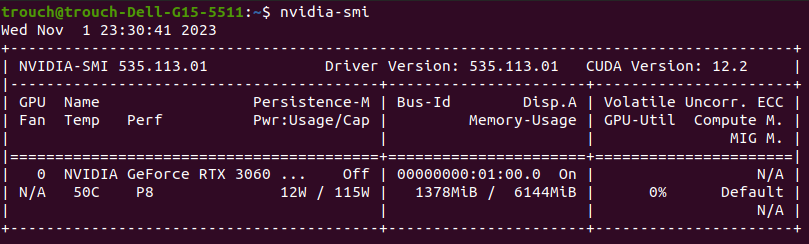
Python bindings for the Nvidia Management Library can be installed via pip3 install nvidia-ml-py3 .
Just like our approach with psutil, we can also obtain information about the used and total VRAM.
It makes sense to check beforehand whether or not the GPU is available so that the profiling decorator doesn’t raise an exception and just skips the VRAM profiling. Caching with the @lru_cache decorator prevents unnecessary calls to ‘nvidia-smi’.
I omitted it here for the sake of readability, but feel free to modify the upcoming functions in the following sections to incorporate a mechanism for bypassing VRAM-related tasks in case a GPU is unavailable.
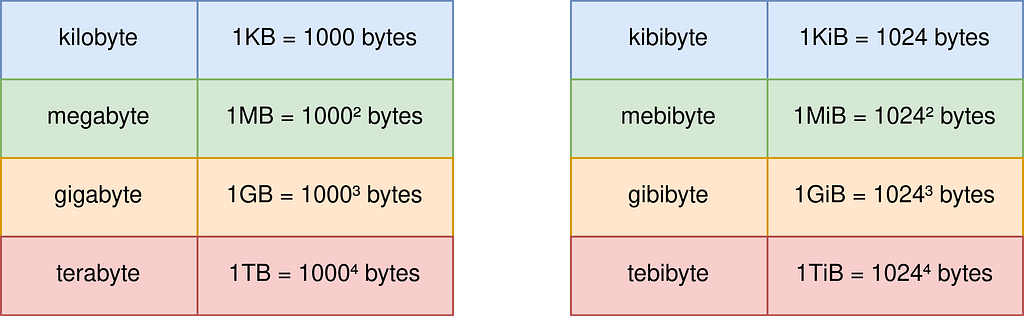
Kilobytes or Kibibytes?
Now that we’ve figured out how to check the RAM and VRAM memory status, let’s talk about the units they use. They’re usually in bytes, which are quite small. We’re more familiar with kilobytes (kB), megabytes (MB), or gigabytes (GB).
But sometimes, in tools like the Ubuntu System Monitor or nvidia-smi, you’ll see ‘i’ added to the units, like GiB or MiB. These stand for Mebibytes and Gibibytes, not the same as Megabytes and Gigabytes. So, it’s important not to mix them up.

As explained in the tables below, Kilobytes use a decimal unit system, whereas kibibytes operate on a binary unit system.
The psutil library already provides a bytes2human method that converts a number of bytes into a human-readable string. However, I don’t like the fact that you can’t choose between the decimal or binary systems, so here’s my version. We compute the number of bytes corresponding to each symbol, e.g. K, M, or G, and then generate a string with the more appropriate unit to express the input memory quantity.

4. Implement a RAM+VRAM profiling decorator
Context Manager
Using the utility tools defined in the previous section, we can now implement a single-function decorator for memory profiling.
As said earlier, we will draw inspiration from the logic of the @profile decorator of the memory-profiler library. The idea is quite simple: we launch a parallel process alongside the target function, periodically monitoring memory status until the function completes.
The class defined below is a context manager that implements the mechanism we’ve just described. When entering the context, the __enter__ method is called to launch a memory monitoring process (The definition of the _memory_monitor function comes right after), while the __exit__ method sends an event to stop the monitoring process. Finally, the memory peak is displayed in the console.
Core memory profiling function
As described earlier, the _memory_monitor function is pretty straight-forward and merely calls nvidia-smi and psutil at regular time intervals to keep track of the RAM/VRAM memory peak.
Function Decorator
Once we have the context manager, we can implement a function decorator at no cost. We just need to infer a pretty function name.
Conclusion
I hope you enjoyed reading this article and that it gave you more insights on how to monitor your code!
See more of my code on GitHub.
RAM and VRAM Profiling in Python was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.