
In our last article, we dived deep into the internals of the guidance library. In this one, we will use the obtained knowledge to create a PR into the exllama repository, where we reproduce one of the functionalities of guidance.
The final idea of this study is to be able to integrate the exllama into the guidance library, and in the process, we can learn a lot about how these frameworks work. This will be a shorter article, but I think it may offer some interesting insights.
We’ll go over:
- Modifying the exllama repository to support a logit bias
- Creating the prototype/test case that uses the logit bias.
The full source code of this article is found in the original PR I raised (which is not merged, as of 01.07.2023).
Modifying the ExLLama repository
Note/Disclaimer: I’m adding links to my fork of exllama, just to avoid confusion in case of upcoming code changes. Remember the original code and the most up-to-date code is found here. All credits of the original code snippets are due to the original author(s).
This repository can be rather intimidating at first sight, since it contains many memory-optimized CUDA kernels, but we don’t need to dive into any of that for our required changes!
In fact, after looking at the first source code files I was surprised at how good the code quality of this repository is, it’s actually very easy to understand how to use the library.
The easiest way to start understanding it is by opening one of the example files. Let’s inspect the example_basic.py, which I’m modifying here to make clearer the parts that are more relevant to us:
from model import ExLlama, ExLlamaCache, ExLlamaConfig
from tokenizer import ExLlamaTokenizer
from generator import ExLlamaGenerator
# init the imported classes...
# (omitted code here...)
# the final interface we use is the generator
generator = ExLlamaGenerator(model, tokenizer, cache) # create generator
# Configure generator
# (omitted code here...)
# Produce a simple generation
prompt = "Once upon a time,"
print (prompt, end = "")
output = generator.generate_simple(prompt, max_new_tokens = 200)
print(output[len(prompt):])
That’s almost as simple as using a Hugging Face transformer! Kudos to the library developers. So the next step is inspecting the generate.py.
In this file, we’ll find many ways to generate tokens from the LLM (Large Language Model). Specifically, this one caught my attention, since it modifies the logits with a constraint:
def gen_single_token(self, constraints = None):
self.end_beam_search()
# Simple sampling case:
if self.sequence is not None:
logits = self.model.forward(self.sequence[:, -1:], self.cache, lora = self.lora)
cuda_ext.ext_apply_rep_penalty_mask_cpu(self.sequence,
self.settings.token_repetition_penalty_max,
self.settings.token_repetition_penalty_sustain,
self.settings.token_repetition_penalty_decay,
logits)
logits[:, :, self.tokenizer.bos_token_id] = -10000.0
if constraints is not None:
for c in constraints: logits[:, :, c] += 10000.0
logits[:, :, :] -= 10000.0
token, _ = self.batched_sample(logits,
self.settings.temperature,
self.settings.top_k,
self.settings.top_p,
self.settings.min_p + 0.01 if constraints is not None else 0.0,
self.settings.typical)
else:
# bos = torch.Tensor([[self.tokenizer.bos_token_id]]).long()
# logits = self.model.forward(bos, self.cache)
# self.cache.current_seq_len = 0
if constraints is not None:
token = constraints[0]
else:
token = torch.Tensor([[self.tokenizer.bos_token_id]]).long()
self.gen_accept_token(token)
return token
If you missed it, this is the relevant block:
logits[:, :, self.tokenizer.bos_token_id] = -10000.0
if constraints is not None:
for c in constraints: logits[:, :, c] += 10000.0
logits[:, :, :] -= 10000.0
So this is almost what we need from the library. The difference is that we want to allow the bias to be generated from the caller, e.g., ultimately from the guidance library. In a way, this is a way to bring ExLLama closer to the hugging face API, specifically this class.
So what do we need to modify here? Let’s extend the optional parameters and add a small block of code:
def gen_single_token(self, constraints = None, logit_bias = None):
# (omitted code ...)
if constraints is not None:
for c in constraints: logits[:, :, c] += 10000.0
logits[:, :, :] -= 10000.0
# New code
if logit_bias is not None:
logits = logits + logit_bias
Alright, we added 2 lines of code here, plus a new optional parameter. Now let’s create a top level wrapper so it’s easier to call this externally. But first, recall first the example_basic.py, there was a generate_simple method, what does it look like? First, let’s see how the generate_simple that is used in the first example we saw works:
def generate_simple(self, prompt, max_new_tokens = 128):
self.end_beam_search()
ids = self.tokenizer.encode(prompt)
self.gen_begin(ids)
max_new_tokens = min(max_new_tokens, self.model.config.max_seq_len - ids.shape[1])
eos = torch.zeros((ids.shape[0],), dtype = torch.bool)
for i in range(max_new_tokens):
token = self.gen_single_token()
for j in range(token.shape[0]):
if token[j, 0].item() == self.tokenizer.eos_token_id: eos[j] = True
if eos.all(): break
text = self.tokenizer.decode(self.sequence[0] if self.sequence.shape[0] == 1 else self.sequence)
return text
So it’s a rather simple loop that uses the function gen_single_function we just modified! It’s no coincidence, we want to use the same internal function in our new wrapper.
We can just copy this generate_simple method, remove the for loop, change the accepted parameters, and make sure the logit_bias is passed through:
def generate_token_with_bias(self, prefix, logit_bias, decode=True):
self.end_beam_search()
ids = self.tokenizer.encode(prefix)
self.gen_begin(ids)
token = self.gen_single_token(logit_bias=logit_bias)
if decode:
text = self.tokenizer.decode(token)
return text[0]
else:
return token
Now, I have no idea how the self.end_beam_search() works internally, but I just kept it here for compatibility reason. I’d assume it’s just to avoid conflicting with the beam_search sampling mode.
In any case, this function is really simple: we just tokenize our input, and then generate a new token using our logits bias.
Great, so that’s all we needed to modify in ExLLama for our prototype. Let’s jump to the next section.
Creating the prototype / test case that uses the logit bias
OK, so the final result you can find it here.
In the new example_bias.py, we’ll start from the example_basic.py, but reproduce the logic from guidance, using a Trie data structure to manage our token prefixes and apply a bias.
To make it easier, let’s always assume our Trie will always store characters, so our token prefixes we’ll be managed character by character.
We could make it smarter by using the tokens ids directly, and as far as I understood, that’s how the guidance library works. It does add extra effort, as you have to map tokens ids back and forth between prefixes. We don’t need a full-fledged implementation, however, this is just a prototype/toy implementation.
So let’s add some code to populate our Trie. We want a prompt that gives three options to the LLM to choose from, and each prefix path is pushed into the Trie:
import pygtrie
tree = pygtrie.CharTrie()
options = ["rogue", "wizard", "warrior"]
# Fill tree with options paths
for option in options:
for idx in range(len(option)):
key = option[:idx]
if tree.has_key(key):
tree[key].append(option[idx:])
else:
tree[key] = [option[idx:]]
If we visualize how we populate our Trie, it would look somewhat like this:
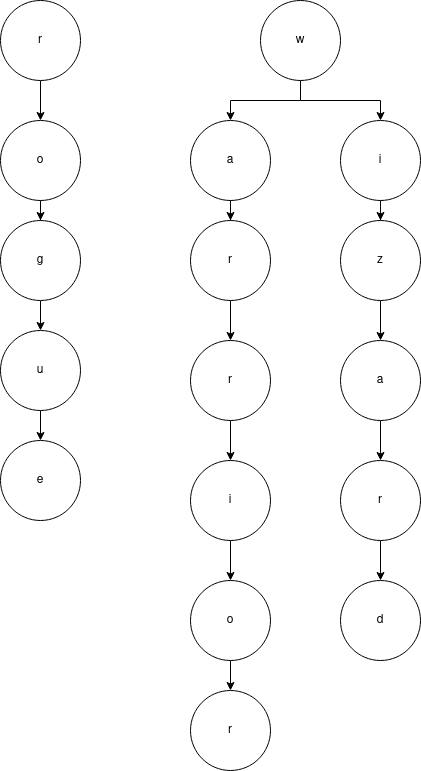
We’ll then take the first char of each prefix path. At first, this is just the first character of each option, which here would correspond to (r and w):
first_char_options = []
for option in options:
first_char_options.append(option[0])
And then generate a bias for each option. Let’s wrap this in a function:
def generate_bias_from_valid_characters(model_config, chars):
encoded_tokens = []
for char in list(set(chars)):
encoded_tokens.append(tokenizer.encode(char))
(...)
Note that we explicitly de-duplicate repeated prefixes by using list(set(chars)) to avoid adding bias twice to the same character.
And then we use the model config to generate a bias array initialized to 0. For each of the encoded tokens, we apply the positive bias:
# (...still inside generate_bias_from_valid_characters)
import torch
logit_bias = torch.zeros([1, 1, config.vocab_size])
for encoded_token in encoded_tokens:
logit_bias[:, :, encoded_token] += 1000.0
return logit_bias
Now, let’s write a prompt:
prompt="""Description: You're stealthy and like to steal. You hide well. You walk in the shadows.
You pickpocket.
You are a """
And then do our generation logic that uses the Trie and the bias generation:
logit_bias = generate_bias_from_valid_characters(config, first_char_options)
prefix = ""
option_fulfilled = False
max_tokens = 10
i = 0
while not option_fulfilled and i < max_tokens:
# Generate the next token with prefix and bias
prefix += generator.generate_token_with_bias(prompt + prefix, logit_bias=logit_bias)
# Look for paths in the tree
suffixes_to_explore = tree[prefix]
# If only see one path, we can end the search and return it
# This is what happens the LLM generates first a 'r'
if len(suffixes_to_explore) == 1:
prefix += suffixes_to_explore[0]
option_fulfilled = True
# Otherwise, we need to re-generate a new bias
# for the next character in each prefix path available
# This is triggered when the LLM chooses a 'w'
else:
valid_chars = []
for suffix in suffixes_to_explore:
valid_chars.append(suffix[0])
logit_bias = generate_bias_from_valid_characters(config, valid_chars)
i += 1
print(prefix)
If everything went correct, this would output rogue!
In a different prompt, we would hope that the LLM would generate first a w, and then we need to explore the other paths:
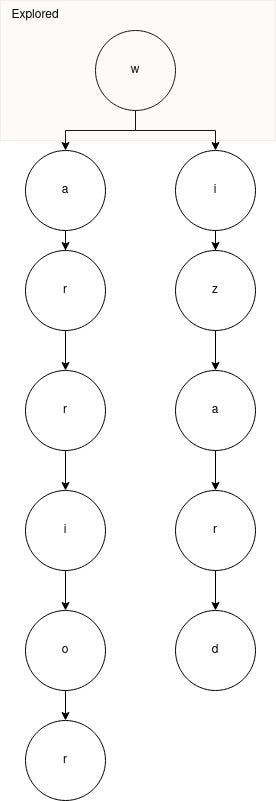
This would correspond to the else block:
else:
valid_chars = []
for suffix in suffixes_to_explore:
valid_chars.append(suffix[0])
logit_bias = generate_bias_from_valid_characters(config, valid_chars)
That is, now we would have to generate bias for the characters a and i, and repeat the process.
Conclusion
Note that this doesn’t always work super well, depending on the prompt, sometimes the LLM insists the one that hides in the shadows is a fighter or a wizard!
But I believe that’s more related to the quality of the LLM generation. Or, alternatively, it could be that generating relying on specific characters rather than token ids degrades significantly the quality of the output.
Nonetheless, since this is a prototype code, we don’t need great quality. The idea is ultimately to let the guidance library do the heavy lifting with the bias generation, and there it will do the proper token id mapping.
As the next step, we’d have to dive again into guidance and glue it back with our new generation method. It’s very likely that in the process we find more features to extend the Exllama library. But one step at a time.
I hope you enjoyed this article and until the next one!
Prototyping a Small Guidance Select Clone With ExLLama Logits Bias was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.