
Hi, I’m Jakob, and I lead engineering at a new Enterprise AI company. We’ve been working with a range of experts across enterprises to understand what our customers need to use AI effectively in production environments. I want to share some of the learnings we have been hearing.
No one has all the answers (yet)
The space is new and still very much in flux. There are so many videos on Twitter about the next big AI application that people are cautious about what is real and what is vapourware.
“Demo fatigue” has firmly settled in while new paradigms have opened up. Everyone has FOMO and is trying to figure out how to put the latest research into practical use at a rapid pace.
Production engineering, not prompt engineering
Regardless of the end use case for AI, the fundamental problems with using it are very familiar to people who have worked through the “big data” or “cloud computing” platform shifts:
- How does my system run reliably at scale?
- Where does my data go and who has access to it?
- Is my architecture flexible enough to support the next 1–5 years of innovation?
For us, all of this falls under “Production Engineering”. It will be key for AI to make the leap from demo to production. Most companies are torn between building their own implementations or buying immature solutions that are not fit for business purposes.
To us, AI in production is more than LangChain + LLamaIndex + GPT-4 to enable Q&A on your company’s data. Companies are looking at how they can put AI at the very core of their business. These spaces don’t align with a chat-based approach and should not be allowed to send data to an external cloud system.
Where is your model at
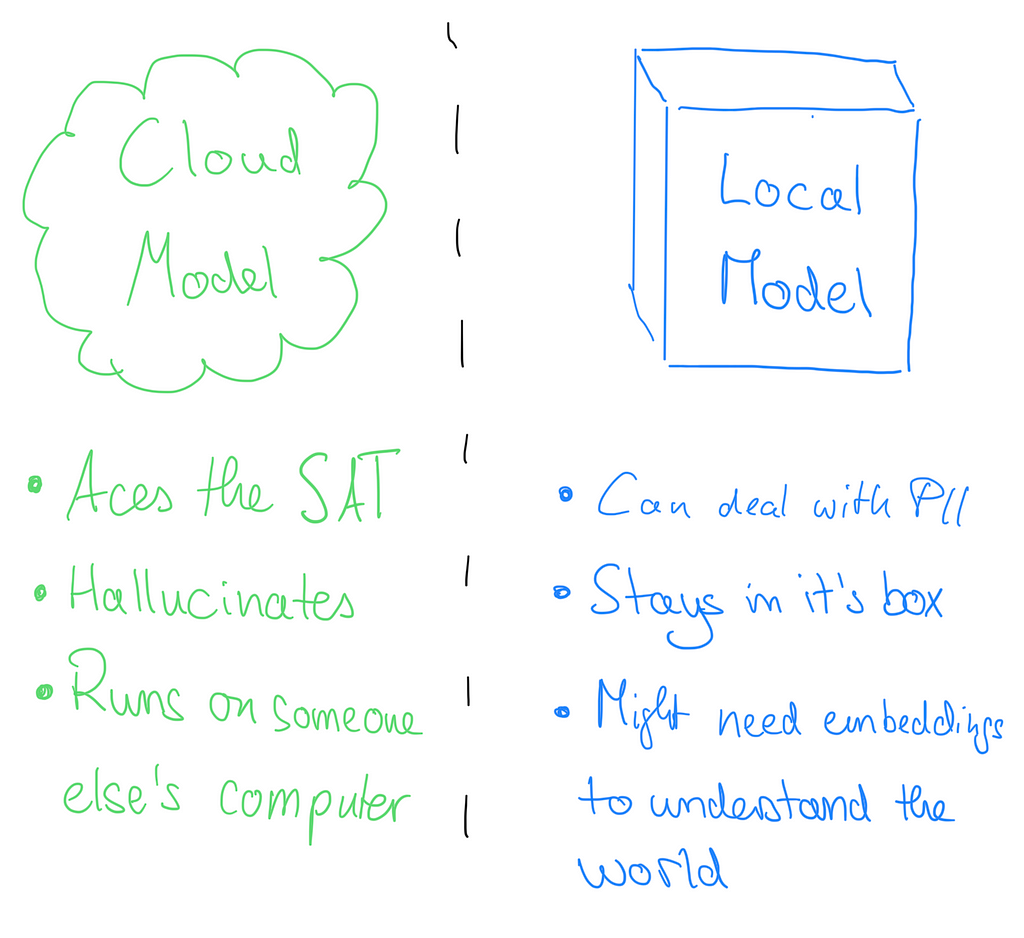
The single question we have heard the most is not what model(s) to run but where to run them. There is an apparent dichotomy between big, closed-source cloud models and small, open-source on-premise models. We feel this perspective is primarily a misunderstanding. Each option caters to different needs.
Cloud models currently have an edge in terms of raw capabilities and understanding of the natural world. It also makes them prone to mediocre performance for specific tasks and increases the risk of hallucinations. Using a cloud model can come with significant security risks — after all, you send critical data to an external system outside of your control.
Smaller models can pull 10x their weight

Smaller models can shine in their own right. For example, people have gotten fantastic mileage out of Together AI’s RedPajama series, which is one of the few models that are actually licensed for commercial use cases. The amount of people who never checked a model license when using it for company purposes is … concerning.
The trick was to deeply understand how the model was fine-tuned and leverage embeddings to ensure the model has the most relevant context (what the kids call RAG these days).
It is tempting to opt for the largest-available model and provision the best hardware, but that means more cost and often longer inference time. We’ve found that the “sweet spot” is models with between 7 to 15 billion parameters. They can parse natural language well and don’t need to have world knowledge that won’t be relevant in an enterprise context.
Some concrete examples we have seen in the field on how for example RedPajama Instruct can be put to good use are:
An American healthcare payments processor wants to ensure that any claim submitted has a high chance of being accepted. Their legacy approach was a combination of manual checks, regex and scripts. With a model running in their own certified system they can actually parse rejected claims and derive rules in a standard format. This in turn is used with the model and their legacy system to ensure claims are validated ahead of submission.
A neo-bank had hired a team of contractors to validate customer information based on utility bills. Small models provide an easy and robust way of turning PDF documents into structured data and automating this whole process when they are combined with new techniques such as JSONformer. OpenAI was off the table as utility bills are considered PII and didn’t give the necessary reliability when it comes to the output format.
A cyber security startup wanted to give their users a straightforward way of mitigating and remediating CVEs. Rather than having to scour a random collection of websites they summarize websites with a locally running model and then combine them into a standard format. That way users have a consistent experience but can also ask more questions of the remediation.
This list is by no means exhaustive and is meant to be an inspiration on how even models running locally can enable various kinds of use cases. People are learning in real time what is possible.
It’s important to avoid taking a one-size fits all approach. The reality is that most places look to use a mixture of small and large models that operate in conjunction across use cases and across cloud and in VPC. Sensitive data will run on smaller models in VPC while larger models deal with public data in the cloud.

We are thinking about this as “Federated Inference”. A network of models interlaced with the existing software stack: Software 1.0 and Software 2.0 working in tandem. The core to unlock it is the existing production engineering practice that already ensures operations at high scale.
In this way, AI is very much like databases in the 70s or cloud computing in the 2000s. The people we spoke with think we are far from the end of the innovation and AI will become a standard component of all new software. Most companies will interface with many different models that will all get smarter over time.
We want to help them get there and are excited about the imminent future.
Production Engineering and Generative AI was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.