Platform as a Runtime (PaaR) — Beyond Platform Engineering
Exploring approaches to organizing work and achieving better velocity and quality
Platform engineering is something I’m personally very excited about, and we at Wix have been practicing it for over a decade (before the name “platform engineering” was coined). In this article, I’ll explain some of the things that our teams at Wix Engineering have already deployed and implemented in the past couple of years, taking platform engineering to the next level.
We’ll dive into some new platform projects we’ve been working on to give some insights into our vision for the future.
To provide some context, Wix is a leading website-building platform with over 240 million registered users (website builders) from 190 countries. Our platform is deployed in three regions and has 20 more points of presence globally. At Wix, we employ over 5,000 people, about half of whom are in R&D. So, it is safe to say that engineering is at the core of what we do and the core driver of our business value.
The Need for Speed
Successful software businesses deliver high-quality code fast. However, it comes with a lot of challenges related to size. As companies grow older and larger, the software development process becomes slower due to increased dependencies, legacy code, and complexity.
Since computer science and engineering existed, there have been multiple approaches to organizing work and finding ways to achieve better velocity and quality, where the latest trends are — Continuous Delivery, DevOps, and serverless.
As the popularity of methodologies changed, the tools we used also changed. These evolved to help companies deliver software faster — a push influenced much by the sheer number of tech startups and their growth. To support that growth, we saw the emergence of cloud hosting/computing providers enabling quick access to servers in vast data centers, thus reducing operational overhead and cost.
Then came the microservices philosophy, allowing companies to scale up even faster and maintain their software much “easier.” Finally, we have serverless, which takes away even more of the overhead and the need to maintain production servers. As the name implies, with serverless, you don’t need to deal with maintaining servers anymore. It removes the need to care about scaling, configuring servers, dealing with K8s, and more, thus leaving you with even less operational overhead.
How Microservices Affect Dev Velocity
If you’re just starting and you are building a single service (Monolith), things are fairly easy. You can use any framework of your choice and utilize all the tools at your disposal. You are able to go very quickly.
But as you scale, things tend to get more complicated quickly since you aren’t building just one service. You build something that integrates with other services and systems — and that thing now needs to connect to other services via RPC/REST, databases, message brokers, and so on. Now you have dependencies that you need to operate, test and maintain. You need to now build some framework around all of this.
And yet, with a handful of microservices, this is still a fairly simplistic architecture. As you continue to grow and succeed, you add more and more microservices and get to something like the image below. This is Wix’s microservices map; each rectangle is a microservice cluster, and the horizontal and vertical lines communicate between them.

As you can see, with many microservices, it also implies that many teams are working on them. Since all your microservices need to work in harmony, you need to think about the common concerns between them all — you need them to speak the same “language,” to have the same protocols and contracts. Like, how do I handle cookies and security? And how about the PRC calls, HTTP headers, and Logs?
Here’s a quick non-exhaustive list of the top things you may now have to worry about:

What do we do then? We create standards via a common framework, a common language, to make sense of it all. Otherwise, every developer must take care of all these cross-cutting concerns.
To make things worse, in a DevOps culture, you also expect the developers to be proficient in the following:
- maintaining the production environment
- taking care of provision machines
- looking after the databases and Kafka clusters, firewalls, and load balancers
- making sure autoscaling is properly configured
- building monitoring dashboards
- understanding distributed systems and request flows
- replicating data across regions, etc.
The Iceberg of Microservice Architecture
Let’s look at one example service and the layers it is built upon. At the basis of it, there’s computing power — a virtual machine. It is running inside a container, and sitting on top of it is the microservice/application framework — for instance, Spring in the JVM world, Express for NodeJS, or whatever you work with. And then, on top of that, you build your trusted environment framework — a layer that makes it possible for all of your underlying services to communicate in the same way.
Via the same protocols, using the same HTTP headers, working with the same encryption/decryption algorithms, etc. That way, they can be used and trusted by all of the other services on the network.

Now, after having all these layers, next comes the actual work required from software developers. At the very top of this pyramid, you build the service that brings business value that your company sells to customers.
For us engineers, this is just the tip of the iceberg. There’s the whole bottom part of it which we need to take care of before we can even deal with the top part, which is the business logic code. Unfortunately, the overhead does not end here. In addition to the product features you need to develop, developers also need to take care of regulations, and business and legal concerns like GDPR compliance, for instance. This is not something your company sells, but you are required to develop it with each new service you build.
That was a long intro, but it explains the magnitude of developing large systems. Now, let’s take a breath and let’s talk about…
Platform as a Runtime (PaaR)
Usually, when building a microservice, you use your internal frameworks and libraries that are compiled with your code, giving you most of the common functionality like gRPC, Kafka client, connection pools, A/B testing, etc. However, with this approach, you end up with a distributed common framework, where you often need to update all the microservices to have (close) version parity across all your services.
It is a real challenge to update all your services to the latest framework constantly — or have semantic versioning — which brings its own set of issues (out of scope in this article).
So, what can we do about this dependency overhead?
One solution is to change the framework’s dependency from build time to runtime dependency. But at Wix, we have taken it a step further. There are other concerns when building an internal framework besides communication protocols and contracts, as we mentioned before. These other concerns are common business flows, common legal concerns (GDPR, PII, etc.), common tenancy models, permissions, identity management, etc.
So, we took all these business concerns and flows and added them as runtime dependencies, ending up with a Platform as a Runtime (PaaR).
Let me explain what it means by adding them to the PaaR.
It means that now every microservice that is running in the PaaR gets these concerns handled automatically for them, without any development needed to be done in each service. For instance with GDPR, all services automatically handle GDPR requests to get my data and “forget me,” saving precious development time in each service.
How did we do it?
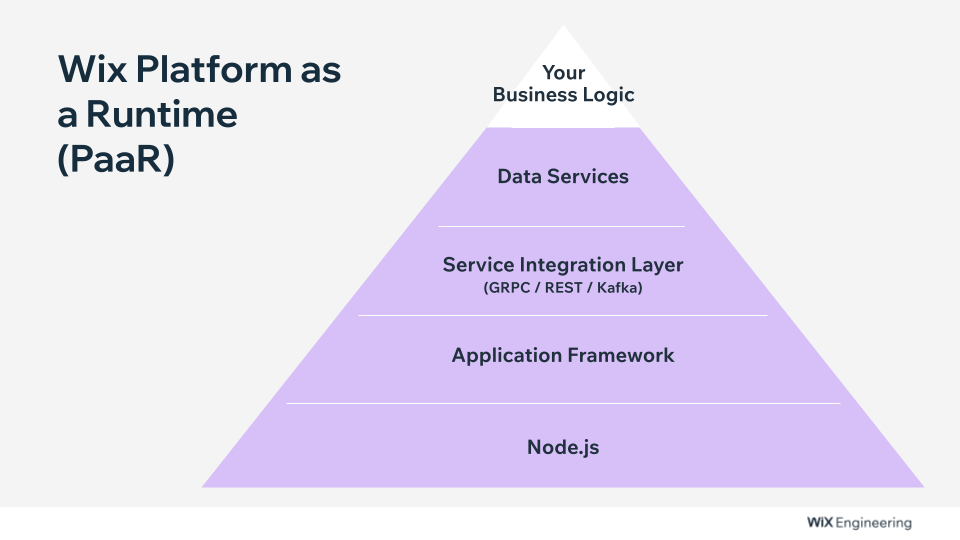
We started with our very own serverless platform. At its core lies NodeJS, supporting the entirety of the application framework. Why Node.js? It is lightweight, supports dynamic code loading, and is easy to learn.
Step one: We took that and coded our entire framework into the Node.js server with an integration layer with GRPC / REST / Kafka (including a discovery service) and made it the “runtime server.”
So, now we have a cluster of identical “runtime” servers that have the same functionality (the frameworks).
Step two: We added another layer for data services, allowing developers to easily and quickly connect with databases (the runtime handles all the connection strings, connection pools, JDBC, etc.)
We ended up with a “smart” container that can handle ingress traffic and have all the common concerns embedded into it without much business logic.
What happens now is that developers can build the business logic using the runtime dependency (serverless) while not having the framework compiled and packaged with their code since it is provided to you as you deploy your code into the running process.
As developers work on the code locally, a time comes when it is ready to be deployed. In the serverless ecosystem, you don’t need to worry about Node.js or containers. You deploy your TypeScript file(if it is a single function) or bundle, and that file gets dynamically loaded into the platform’s runtime!
Since we already have the service integration layer in the runtime, you don’t need to do lookup/discovery when you need to call another service. You declare what you need, and the platform provides the right client to connect to your dependent service.
Since all the integrations are done via the “runtime,” it also saves you the integration tests since the integration is done via the “runtime,” and you get a client library to use in your code.

A major benefit is that you deploy just the code you need, without having to bundle it with common libraries and node.js runtime, which makes deployables extremely small, because it only contains the actual business logic you write (usually less than 100Kb in size).
Separating project structure from deployable topology
Up until now, what I have described resembles standard lambda functions (however, with Lambda functions, you need to bundle your framework with your deployable). But what happens when you want to add another function? Well, with lambda, you would need to have another instance of the whole setup or package the two together, but since we are running on a trusted environment, we can run multiple functions inside the same process.
Basically, we can develop as independent microservices or even nano services (functions) but deploy all the functions to run as a monolith into the same process. However, we can also split the functions deployments to different PaaR (Platform as a Runtime) hosts, mimicking microservices, instead.
We can also do it the other way around. Develop the software as a microservice or a monolith, but deploy parts of the service to different PaaR hosts.
A classic example is when you have a service that has two endpoints. One is an RPC endpoint that needs to react to a user’s request, and another that listens to Kafka topics. We can develop the two functions in the same project so that the developer thinks about these endpoints together as part of the same “logical” service but deploy the RPC function to one host and the Kafka listener to a different host.
This will result in enabling different scaling strategies. We could autoscale the “customer-facing” RPC function differently than the Kafka service without the developer having to handle the cognitive load of separating these into two different services with all the framework overhead that comes with it.
At Wix, we built the system so that deploying a function is very fast and easy. After a developer pushes their function to a GitHub repository, it takes about a minute for that code to deploy to and run on production since it is only a small portion of the code (only the business logic, without boilerplate and bundled common libraries)
Platform Engineering Mindset
What did we achieve by doing this?
- Integrations became very easy — a developer can declare which functions/microservices they want to call, and they “automagically” get a client library to work with it.
- There is less code to test — no integration tests for glue code are needed.
- Developers can write and deploy very small functions focused on the essence of their business logic.
- The deployment is fast — the code is small, and no framework/common libraries packaging is required.
- There is zero boilerplate — all integrations are preconfigured and provided for a developer to use by declaration only.
Vision for the Future
Next, how can we use what we have so far and build on top of that? Say we want to give separate teams the responsibility of managing their own runtimes. We can do that by cloning the setup I described above so that, for example, ecom and blog teams could each have their own cluster of runtimes to work with. That way, if needed, code from different teams isn’t pushed to the same runtime. All the while, you are still able to call functions between runtimes.
In this context, one thing we want to have at some point is to optimize the affinity of a given function based on its runtime. What do I mean by that? Let’s say we have the following two runtimes, each containing several functions:
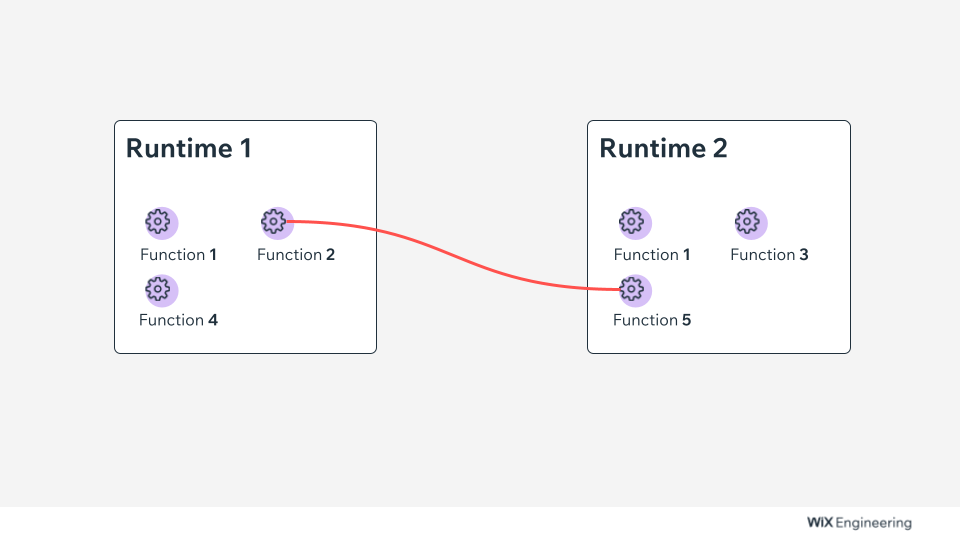
As you can see from the diagram above, Function 2 and Function 5 frequently interact. But since they are deployed on different runtimes, the network calls are slowing down. What if we could have the system automatically deploy Function 5 to the first runtime and Function 2 to the second one so that, in the end, we would get a picture like this:
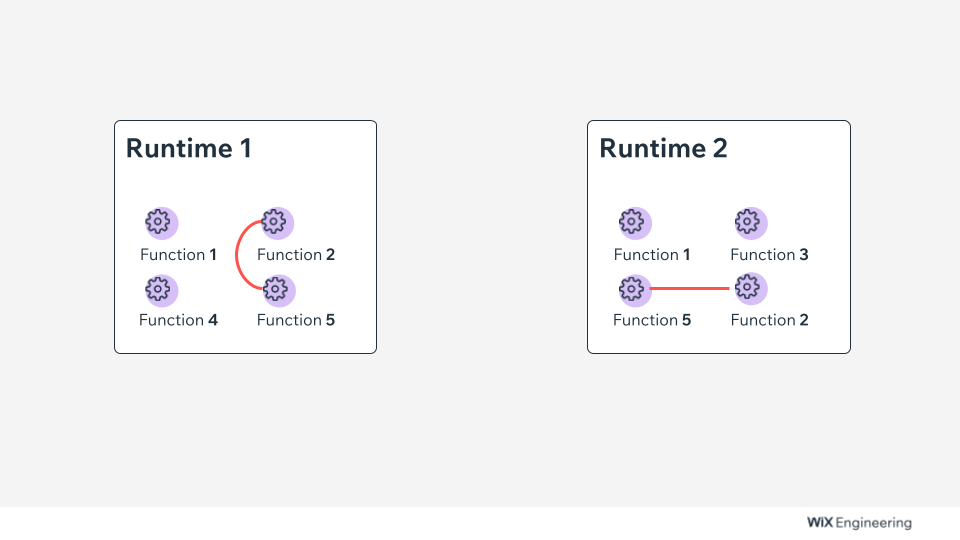
This way, by organizing and optimizing the functions in runtime instead of build time, we can have a highly optimized runtime environment with minimal network calls between microservices. This contrasts today, where we couple the domain design and the development environment with the runtime topology.
The Future Is Here With “Single Runtime”
Another future development we are excited about is expanding into other programming languages.
In my opinion, this would require a paradigm shift, though — to not build a polyglot system and not to build the same framework as many times for as many tech stacks you support in your company. But instead, use a single runtime that would actually support any language.
We work on achieving that by splitting the “Iceberg” in two, separating the single runtime framework, service integration, and the data services layers on the one hand. We call this the “Host.” Integration layer to the host + business logic as the “Guest.” The idea is to be able to develop the application framework only once instead of constantly trying to achieve feature parity between frameworks in different programming languages. An obvious advantage to this approach is running framework updates only on the host, not duplicating the framework/runtime for every language/dev stack you support, and only having to do it once.
The disadvantage is that we will not run the actual business logic (guest) in-process, but the host and guest communicate out of the process (on the same localhost). We are still experimenting with GraalVM to see if we can run multiple Guests (different languages) in-process with the host, but for now, we had an easier time and an actual working system by having two different processes.

The Road So Far
The success of this approach is evident in how much our developers love it. At the core, there is the platform engineering mindset, where we took a lot of complex concerns and made them easy. Wix developers can now develop things in a matter of hours that used to take them days and even weeks.
We took platform engineering from a low-level developer’s portal to a full-blown PaaR, along with a lot of the cognitive load of production low-level maintenance. Stay tuned for more as we detail the Wix “Single Runtime” project.
To learn even more, watch “Beyond Serverless and DevOps”:
Original Article: https://www.aviransplace.com/post/platform-as-a-runtime-paar-beyond-platform-engineering
Platform as a Runtime (PaaR) — Beyond Platform Engineering was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.