NBA Games Outcome Project — Data Development
Part 2 of 3

Hello! This is part two of a series where I build an end-to-end application that mainly aims to predict the game outcome between two chosen teams in a pool of 30 NBA professional teams. I’m doing this series mainly to show the key aspects of what helped me in creating this project, as I learned a lot in the process, and I believe that knowledge should always be shared.
Objective
This article shows the most important aspects I used to prepare the data through exploration and manipulation. Later, it will be ready to train a machine-learning model. Data will not be available in the traditional way — input features in the trained model will output a prediction. We can’t do that directly because, as you might have guessed, the input features for future games that we wanna predict will exist after the game! So, we will need to come up with a solution for that, and I consider the process to achieve this the main takeaway of this article.
The methods
As we have a complete SQL database of games stats per team stored, we will read it to a Pandas data frame using SQLalquemy to create an SQL engine.

Data exploration and cleaning time with Pandas! Note that as the dataset is highly dimensional, with hundreds of features, we will not do a feature-by-feature analysis right now, so the process is simplified. We first drop any duplicated rows and redundant columns like opponent_mp, which stands for minutes played by the opponent team, then check for missing values and the feature mp, which stands for minutes played. This is because some games go overtime (e.g., those not within the 240 regular minutes per team), causing some stats to be higher than usual.
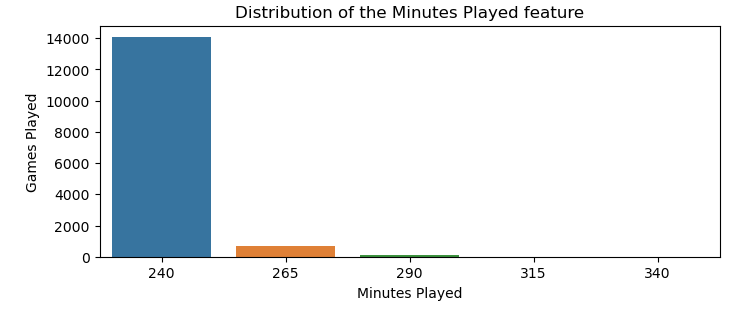
Making the math, the number of games that go overtime is about 5% over the thousands of games we have stored from actual and past seasons, as we can see with the help of Seaborn and Matplotlib visuals. As a rule of thumb, if the number of overtime games is at most 15% of all games, we can safely cut it out of our dataset.
With this step, the dataset here will be considered clean, and we can store it in a pickle file, which we will call production_df.pkl, as it is ready to be used to feed a machine-learning model and make some new predictions in production mode when the project ends.
Here is my thought process about new predictions: Say we want to predict the match result between team A and team B. With this first input, we will consult our production_df, get the mean stats of the last n games of team A, then the mean stats last n games for team B, and finally, concatenate this in a single row. This will be our input to feed an ML model, so we get our prediction results! Of course, this is still not perfect as a traditional dataset, as the stats of a game could be very different from the estimates for some games, but overall it seems to be a reliable strategy.
OK, now it’s time to transform this dataset, so it can be used to train an ML model. The training data has to match our idea of how our model will make future predictions. So, each row will be the mean of the last few games for each team, using the ‘rolling function’ of pandas, which I found to be very handy in these situations! This is the link to the function documentation if you want to know the details. Note that as we are taking the last n games per team, considering the season and home stats, will lose some information in this way.
If we roll with the n games window, only the information with n+1 appears as a row. It means we lose 2*n rows per team, as each team is grouped by home or away also. Maybe it can sound a bit confusing when hearing for the first time the way I said, so here goes an example with the code below:
- For n = 6 games, with a season having 30 teams, we lose 2 * 6* 30 = 360 rows per season because each row only computes if there are at least six games prior. But, as we have almost 2,500 games in a regular season, it is still worth trying numbers like 5 < n < 15 and seeing what works better for you. At the moment of this publication, six games worked best for me, as I didn’t lose so many games and also captured how the team was performing in the recent games with enough information.
def team_avg(grouped_df, last_n_games=6):
""" Info:
This function calculates the rolling average of
the features of the team
Input:
last_n_games: number of games a team played to calculate
the rolling average
grouped_df: dataframe grouped by team, season, and home status
Output:
rolling: dataframe with the rolling average of the features """
rolling = grouped_df.rolling(last_n_games).mean()
return rolling
# creating our list of feature cols for ML
info_cols = ['date', 'Team', 'opponent_Team', 'season', 'home', 'WIN']
model_cols = df.columns[~df.columns.isin(info_cols)] # Training features
#df for rolling is the df with the top valuable features for training plus
#the columns that we need for the group by.
# Note that these are columns from the information cols.
df_to_roll = df[list(model_cols) + ['Team','season', 'home']]
df_rolling = df_to_roll.groupby(['Team','season', 'home'], group_keys=False)
.apply(team_avg)
When we transform the data as we did, it’s important to leave the columns concerning identification, like the team column, so we group by these columns, then merge them with the original dataset and have a new data frame as we planned. This will create a row of a game that happened but with the stats of the n games before that game.
The image below illustrates the result of this combination, where the columns represent the date the game happened, if the team played at home or not, and the season ID. The rolling_pts, rolling_opponent_pts are two of hundreds of training features that do not represent the points made on that day but the mean of prior games. The game’s outcome is the only training feature representing the actual day stat. Our target column, WIN, where one represents that the team won.
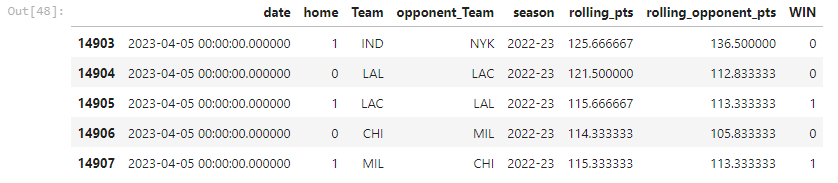
After cleaning the N/A rows left by the rolling function we just used, we need to combine the columns from the home and away teams that played each other, so it results in exactly the same row that an ML model would be fed when the project is done. We mostly use the prefix home and away to differentiate the teams, using the home feature and concatenating.
Results
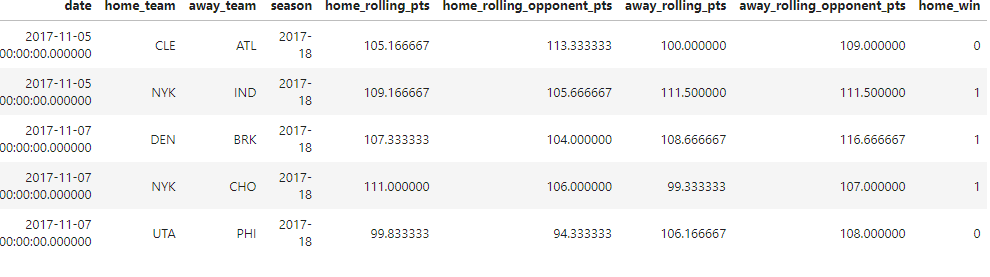
The image above is representative of our full dataframe used for training, which has 269 features. To explain what is happening, let’s see what’s going on in the first row. We have Cleveland Cavaliers (CLE) that played at home, versus Atlanta Hawks (ATL), in 2017–11–05. In the last n games of the CLE at home, say n = 6, their mean scoring points were about 105. ATL scored 100 points on average in the last six games playing away from home.
The opponents that CLE played against in these last games were about 113, while the opponents of ATL scored 109 on average. The actual game between CLE and ATL ended with a victory for ATL, given that our target home_win = 0.
Final Thoughts
It took some planning and reflection to do what would become a training dataset that matches our idea of prediction, given that we do not have the actual stats of the game we want to predict, but we did it! This data can fully train a classification ML model as we wanted. If you find yourself curious about the details, all the code for this step can be found in the notebook I uploaded to my GitHub. I hope you enjoyed reading it.
Next on the menu will be that juicy ML development, so stay tuned for the next series chapter!
Want to Connect?
If you have any feedback, don't be afraid to contact me through LinkedIn.
NBA Games Outcome Project — Data Development was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.