Mistakes and learnings from choosing various databases

I’ve been developing an open-sourced VPN application for quite a while. The idea behind this app was for me to learn various new technologies in the world of Android development, so I gave myself a time period of 14 days to bring this idea into reality. And so at the end of July 2021, I made the code public and released the app on Google Play.
The launch was a success, I got a few hundred downloads without marketing (still hasn’t done it) but it gave me an opportunity to explore some new technologies in public. I still maintain this application to this day as for me it gave me a platform to experiment with new things.
To make this idea into reality I needed two things,
- A list of VPN configurations which is basically metadata about servers.
- A simple UI that makes use of this configuration to seamlessly authenticate and establish a VPN connection.
In this article, I’ll talk about the first problem. The code is public on GitHub so if anyone is interested they can check it out.
How it used to work
There are a lot of websites that serve OpenVPN configuration files. So my initial thought was to write a web scraper that parses these websites and extracts the metadata. Since I had a limited amount of time and also during those days I had very less hands-on experience in writing APIs I decided to write a scraper within the app. It used to run a background job periodically every 7 hours, scrap those websites & save the metadata into a local SQL database.
This worked fine but it had a few flaws, first the scraping logic is shipped with the app which means any external changes to those websites would break the scraper causing it to fail and would make the app unusable so the only way to fix it is to release an update with the fix. The other problems were the scrapper was extremely slow, there was no way to identify if those configurations are valid without establishing a connection to VPN server which itself is time-consuming, as it was a heavy network operation it used to consume a good amount of battery on low-end devices. These problems made the user experience not so good (I got low ratings on my app).
It was time to address these problems, but I’m not quite sure how? So like any engineer, I dropped this problem and started working on other projects.
Fast forward to 1 year, I got to work in a company where we were given an opportunity to closely work with all the systems that powered the working of the product. So I was learning many new skills (Backend, DevOps) which later helped me get this project back on track.
Why choose AWS?
At my current company, we use AWS and Kubernetes to deploy and manage multiple microservices. The process for provisioning is an IaC model, we write code to a repository (terraform, ansible) -> changes are detected by CD pipeline (Jenkins) -> does an automatic apply if the configuration is valid. This gave me enough idea to start something on my own, basically to migrate my VPN app’s scrapping logic to my own AWS infra and expose convenient APIs for the client.
The reason I went with cloud computing & not with any PaaS solutions like Heroku, Digital Ocean, Vultr, etc. is that I want complete control over my infra so I can efficiently manage the cost, deployments, any downtimes due to maintenance, plus such cloud computing providers (AWS, GCP, Azure) offers many services that has seamless integration with each other to build a scalable application. However, one downside to this approach is you get yourself “vendor lock” to a single provider. Having prior experience with AWS and also I got some free credits from them made me choose AWS to deploy my microservice(s) for my application.
The current setup uses 2 EC2 machines (t2.micro & t2.small, now t3 family), both these machines have the service running on port 8081 which is then exposed outside VPC (to the internet) via an Application Load Balancer.
Choosing DynamoDB
There is one cronjob (script) in one of those EC2 machines which runs periodically that scraps those websites and dumps the metadata into a database and my service just serves the data to the client whenever requested. This model prevents the service from performing any time taking business logic & also a good practice to keep such logic isolated for any future modification.
Since the data I handle is unstructured I decided to go with a NoSQL database. At first, I thought I should go for MongoDB through their Atlas program, a fully managed service for MongoDB, but their free plan (M0 cluster) does not provide AWS VPC peering. This is needed so that database connections can only be established by trustworthy IPs (eg: my Machine on AWS).
There is something that AWS offers as an alternative to Mongo Atlas called DocumentDB, however, the pricing is too much. A single on-demand t3.medium machine costs around $0.078 per hour i.e $58 per month. Since I’m in the free tier (as well as having some free credits) I should not be spending or wasting my credit on something which is not scalable for the long term.
I then came to know about another OLTP NoSQL database called DynamoDB. DynamoDB is a serverless NoSQL KV (key-value) store database designed for high performance. In DynamoDB there is something called as Capacity Units (CU) for reads and writes, so if you read one row/document it will consume 1 CU & same for writes. It is free for 25GB per month of storage and offers 25 free provisioned read/write capacity units which means I can read 25 documents at a time.
Anytime I go over this limit I will be charged. One way to solve this is to limit the max capacity units which could slow down your SCAN operation anytime you cross these limits. There are other charges like $1.25 per million write and $0.25 per million reads. Overall, DynamoDB is pretty affordable.
Why migrate to MySQL (bad idea)?
The setup was simple, a cronjob will dump VPN configurations metadata to the database and the service will serve this metadata from the DynamoDB database. The performance started to degrade for unbounded queries, basically scanning & returning data from the entire table started exceeding the max capacity units limit resulting in slow response (the max capacity was set to 25 but the table had ~50 items).
The client UI displays all servers grouped by country, so implementing pagination was not a solution hence the unbounded queries. Since the cronjob runs every 5 hours, I started sending HTTP Cache-Control headers with a TTL of 2 hours. Any HTTP client (whether in browser or mobile) will respect this TTL and will try to serve a cached response until it becomes stale. Doing so I was able to reduce latency but the problem of slow response was still there.
Since I had ~50 items with 25 max capacity units, it use to take twice the amount of time to query the whole table. Increasing the max capacity unit would be a temporary solution as the number of table items can increase anytime. It seems for my case (unbounded queries) DynamoDB was never a solution. It is performant if your query acts on a specific index (primary or secondary) which would be blazingly fast. Also, DX for writing queries for DynamoDB is not very intuitive (but that is okay) for eg, taking a look at an update query.
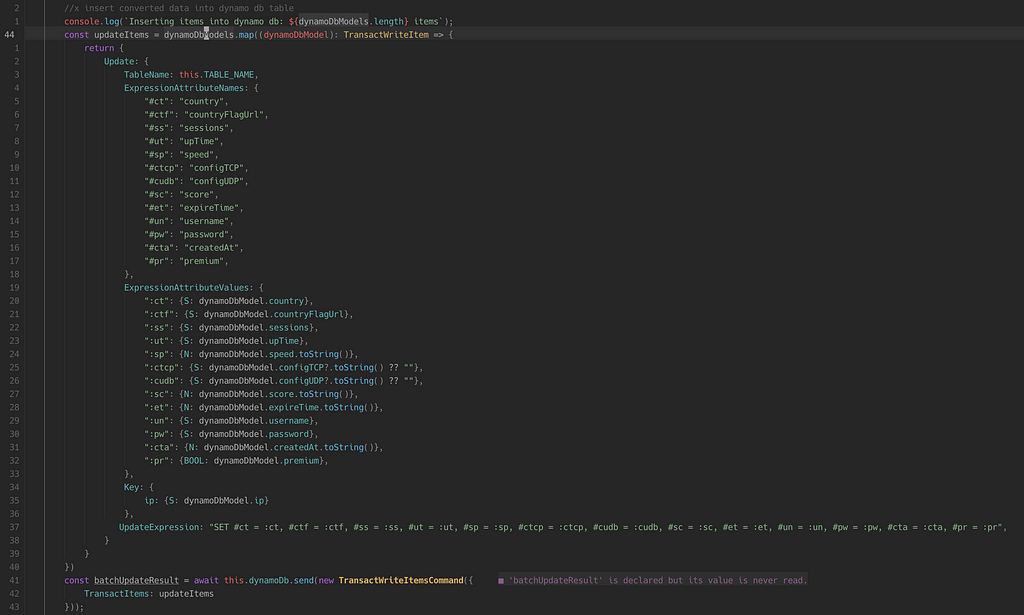
It was time to go for SQL, any unstructured data will be stored as raw JSON/bytes. Also, the pricing for RDS is $0.016 per hour for t3.micro (2vCPU, 1GB RAM) i.e $11 per month. Though it looked like 1GB RAM was enough for my use case, it was really not. During migration, I started sending production traffic from DynamoDB to MySQL and the results were promising, there was a decrease in latency so I end up sending the entire traffic to MySQL after a couple of days.
Things were looking great for some weeks (sending Cache-Control headers was also helping) until I made the API public. Yes, I thought it would be a great idea to make the API public and monetize it. Suddenly after a few days, I started seeing spikes in the Database Connection, and now the latency is high again. My app has 100+ DAU, and though it seemed like MySQL worked well, it really did not. The only optimization that was helping me till now was sending Cache-Control headers.
When the API was made public I got an unknown amount of traffic directly hitting the database, eg: when you test API (on Postman) you generally ignore these headers resulting in a slow response.
Also, for unbounded queries, the response was over 1.5 MB i.e. each record was of size 30–40 KB so if there is enough traffic 1GB RAM machine may not be performant in scanning all those records from disk. Upgrading RAM to 2 GB basically doubles the cost ($22) which was something I did not see as an option.
Moving to an In-memory database
Now, I have my goals clear. I need something which has low latency, high throughput & also cheaper. Databases that serve data from disk would not be suitable at least considering my budget. I would need something that is fast so my natural choice was to go with managed Redis service. Moving to AWS ElasticCache would not be cheaper, so I started looking for 3rd party managed service & I stumbled upon Aiven. Aiven is another PaaS tool but for databases. Luckily, they have a free plan for managed Redis that gives 1GB RAM of the machine, also I can whitelist IPs so only machines from my AWS account can access the database. It is a manual process (since they don’t provide Network peering for free plan), I can live with it.
At the time of writing this article, it’s been 3 days since the migration. Since it is a 3rd party service & I’m using a free plan there is nothing like Cloudwatch alarms which would notify me when the memory threshold is reached. So, for now, I implemented a basic health check in my service that continuously pings Redis every 10 seconds and if there are more than 3 consecutive failures the service fallbacks to the MySQL database and sends a Discord message.
Conclusion
In the future, I’ll move from MySQL to a NoSQL solution as a fallback database, might as well give DynamoDB another try, and would think of ways to improve the SCAN operation.
I hope this article is interesting for the reader. Anyways, if you’ve any questions feel free to message me.
PS: I’m also on Twitter 🙂
Migrating From DynamoDB to MySQL to Redis was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.