Human Pose Estimation — 2023 guide
Let’s dive into this challenging but interesting field widely used in sports and gaming

What is Human Pose Estimation?
Human pose estimation is a popular computer vision task with more than 20 years of history. This domain focuses on localizing human body joints (e.g., knees and wrists), also known as key points, in images or videos.
The entire human body can be represented with three different types of approaches:
- skeleton-based model (also called a kinematic model)
- contour-based model (also called a planar model)
- volume-based model (also called a volumetric model)
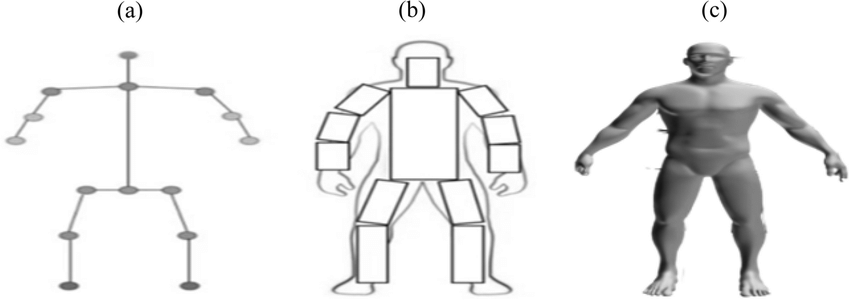
The human pose estimation task aims first to form a skeleton-based representation and then process it according to the needs of the final application. From now on, we will discuss skeleton-based datasets, metrics, and solutions. We will focus here on 2D human pose estimation because 3D often uses 2D algorithms initially and then regresses them to three-dimensional space.
Why Is It Hard?
The main problems in Human Pose Estimation circle around:
- occlusions
- unusual poses of humans (check the images below)
- missing key points
- changes in lightning and clothing
To mitigate this issue, practitioners try to either develop new methods or make challenging datasets to create robust models for such problems. Later, we will explore some solutions that try to solve these problems via more elaborate architectural designs.

Use Cases
AI-powered personal trainers
With the latest developments in computer vision and closed gyms for multiple months, the popularity of applications that assisted people in their home workouts increased. In the background, each of these applications uses the Human Pose Estimation model to track human movement and the number of reps and suggest improvements to your technique.

Augmented reality and CGI
As collecting data for augmented reality and CGI is expensive and time-consuming (i.e., using motion capture technology), human pose estimation models are often used to get cheaper yet still accurate avatars for movies or augmented reality applications. Disney Research is exploring avatar generation from Human Pose Estimation for a more lifelike experience in AR applications.

Interactive Gaming Experience
To make the gaming experience more immersive, various body-tracking cameras were proposed. Behind the scenes, Microsoft Kinect uses 3D human pose estimation to track human movements for rendering the actions of a hero in the game. In the picture below, you can see a small toddler playing a bird-flying game.

Cashier-Less Shops
The rise in cashier-less shops like Amazon GO is thanks to advancements in Human Pose Estimation. Analyzing and tracking customers makes it possible to detect which product and its amount was put into the client’s basket. When they are done, they can leave the shop without spending a long time waiting in line to pay.

{kind=link}
Monitoring Aggressive Behaviours
Thanks to Human Pose Estimation, it is possible to detect violent and dangerous acts in the cities. The cooperation between the Karlsruhe Institute of Technology and Mannheim Police Headquarters will result in real-life tests in 2023.

Datasets
MPII
MPII dataset consists of 40k person instances, each labelled with 16 joints. The train set and validation set contain 22k and 3k person instances.
COCO
The COCO dataset consists of 200k images with 250k person instances labelled with 17 key points.
The difference between the labelling of body joints for MPII and COCO is presented below:

OCHuman
This dataset focused on hard and occluded examples and was introduced in 2019 with the paper “Pose2Seg: Detection Free Human Instance Segmentation”. It consists of 5,081 images with 10,375 person instances, where each is suffering from heavy occlusion (MaxIOU >0.5).
Metrics
PCK — Percentage of Correct Keypoints
This metric is used in the MPII dataset, where the detected joint is considered correct when the distance between the predicted and true locations is within a certain threshold. To make the threshold relative to body size, it is often defined by a fraction of head segment length. In the MPII dataset primarily used metric is PCK@0.5, only joints within a distance of 0.5 ∗ ℎ𝑒𝑎𝑑_𝑏𝑜𝑛𝑒_𝑙𝑒𝑛gth are considered correctly detected.
OKS — Object Keypoint Similarity

OKS is the main metric of COCO dataset, where the folowing is true:
- d is the distance between the predicted and true location of the key point
- v_i is the visibility flag of the key point i
- s is the object scale
- k_i is per key point constant to control falloff (calculated by COCO dataset researchers).
In simple words, OKS acts as a similarity metric to IOU in object detection for image segmentation. Typically, this metric is analyzed via Average Precision (AP@50, AP@75, average across ten steps between @50 and @95) and average recall (same steps as for AP).
Deep Learning models
Throughout the history of Human Pose Estimation, there were multiple solutions based on classical computer vision, focusing on parts and changes in colours and contrast. In the past few years, this area has been dominated by deep learning solutions, so in the following part, we will focus on them.
Deep learning solutions can be distinguished into two branches:
- Top-down: performs person detection first, then regresses key points within the chosen bounding box.
- Bottom-up: localizes identity-free key points and groups them into person instances.
Top-Down Approaches
Hourglass [paper, code]
As stated before, within the top-down approaches, there are multiple examples with favourable results. All of them are learning using not the position of key points but heatmaps of their location. This solution proved to result in a significantly better and more robust outcome. In this blog post, we will limit ourselves to the three most influential pose estimation architectures, which shaped the landscape of this branch of approaches.

The hourglass approach does multiple modules with the very same structure. Each module consists of upsampling and downsampling (looks like an hourglass). Such an architecture allows you to grab local context (e.g., where is the wrist) and global context (e.g., what is the body’s orientation). To make the learning process more successful, intermediate supervision after each module is performed, comparing the prediction of heatmaps to their true position.
HRNet [paper, code]
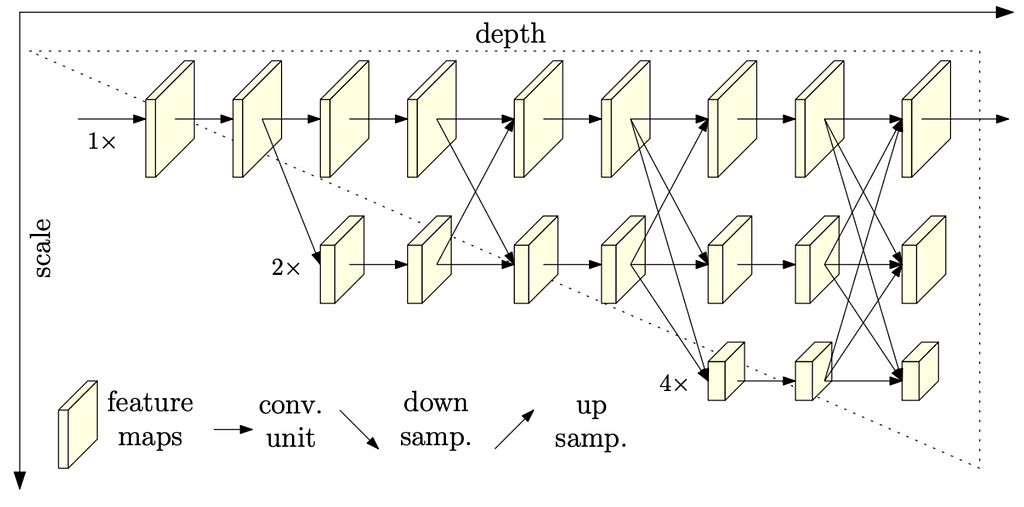
Previous solutions used to go from high->low-> high resolution, while this architecture is trying to maintain high resolution throughout the whole process, as you can see above. Initially, it starts with high resolution, but with each depth step, it builds up more simultaneous scales, which receive information from higher, same, or lower resolutions of previous steps. With access to high-resolution features on each step, HRNet managed to stay on top of most HPE leaderboards.
VITPose [paper, code]
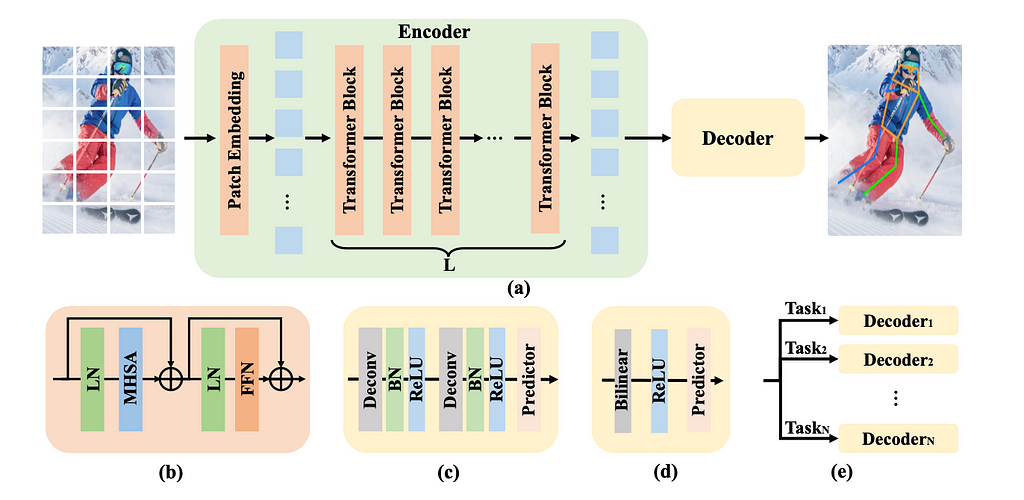
With the advent of vision transformers and their increased popularity in computer vision, it was a matter of time before the “Transformer for Pose Estimation” was proposed. The structure of this solution consists of a collection of TransformerBlocks (each is a combination of Layer Normalization, Multi Headed Self Attention, and Feed Forward Network) and a decoder module.
After extracting features in the encoder, quite a simple decoder is used (The deconvolution layer, followed by the batch normalization and Relu, and then the predictor linear layer are run twice). This network is quite simple to scale and does not require careful construction of convolutional layers with a calculated number of parameters — but it still produces powerful results.
This solution also works well for multi-person pose estimation tasks with severe occlusions (current leader of the OCHuman dataset).
Top-Down Approaches
As mentioned before, bottom-up approaches produce multiple skeletons at once. Hence, they are often faster and more suitable for real-time solutions and perform better in crowd scenes for multi-person pose estimation.
Open-Pose [paper, code]
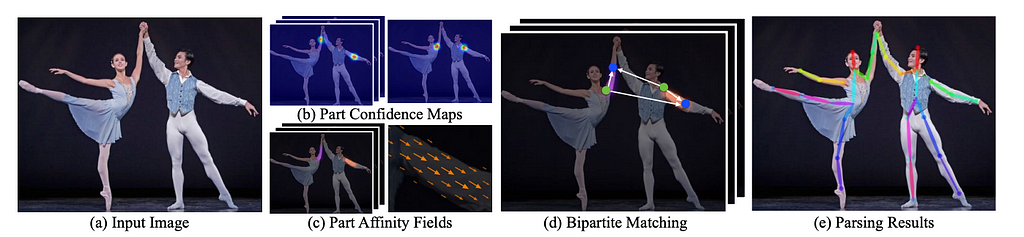
OpenPose is the most popular bottom-up approach model there is, as it was released in the form of an open-source library in 2018. Its popularity is also because it was one of the first real-time solutions with reliable and widespread human pose estimation.
The architecture works as follows:
- Features are initially pulled out of the first few layers
- Then there are two branches of convolutional layers, first one consists of 18 confidence maps, representing each specific part of the human pose skeleton, and the second one has 38 Part Affinity Fields (PAFs), representing a level of association between parts (bipartite graph with keypoint to keypoint connections).
- Prune keypoint to keypoint connections that have low confidence: Thanks to PAFs, it is possible to discard connections between keypoints with a low probability of coming from the very same person instance.
- After the pruning step, multiple human poses are regressed.
The characteristic of this solution makes it suitable for real-time multi-person pose estimation.
Omnipose [paper, code]
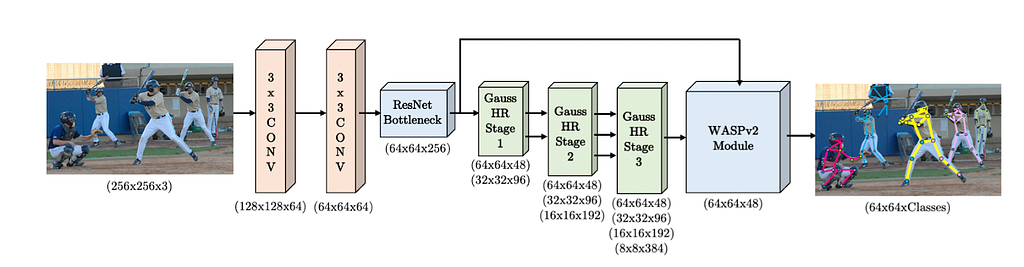
Omnipose is currently the best-performing bottom-up approach architecture, with quite a simple structure. It initially starts with two 3×3 convolutions followed by a ResnetBottleneck block. After that, 3 HRNet blocks follow, each with Gaussian heatmap modulation enrichment (proposed in Dark paper).
This improvement essentially transforms the way the direct keypoint location is done, not looking for maximum value (previous solutions) but assuming that the heatmap of a certain keypoint follows Gaussian distribution and tries to find the center of that distribution.
The main contribution of this Omnipose architecture is the Waterfall Atrous Spatial Pyramid module (WASPv2), which can be seen below:

This module was partly inspired by the WASPv1 module (originally proposed in the Unipose paper) but with the idea of combining backbone features with low-level features. Thanks to all these improvements, this architecture is one of the best-performing architectures.
MoveNet [paper, code]

MoveNet is a popular bottom-up approach model that uses heatmaps to localize human key points accurately. The architecture consists of:
- Feature extractor — essentially MobileNetV2 with feature pyramid network (FPN)
- Set of prediction heads — following a CenterNet-inspired scheme with small adjustments to improve speed and accuracy.
There are four prediction heads:
- person center heatmap
- keypoint regression field, which predicts keypoints for a person
- person key point heatmap, which predicts all keypoints regardless of which person instance they belong to
- 2D per-keypoint offset field, predicting offset from each output feature map pixel to location of each keypoint

This architecture was trained with CocoDataset enriched with Google’s private dataset — Activity — which specializes in challenging fitness and yoga poses. This solution is quite stable to occlusions and unfamiliar poses thanks to novel architecture and robust training dataset. It was released as an out-of-the-box solution with tf-js by the Google team. The model itself was released in two formats: “lightning” with a focus on speed and “thunder,” aiming for higher accuracy (while still maintaining 30+FPS). You can explore the live demo on their website.
Model Suggestions
As you can see, there are multiple solutions available to choose from. From our side, we can suggest the following:
- If you have a lot of data and can operate in an offline fashion, VIT, Omnipose, or HRNet should be your go-to model
- When working on real-time or crowd applications, consider either MoveNet or OpenPose.
- For data-deficient scenarios, probably smaller models will perform better (e.g., MoveNet “lightning,” HRNet-32, or OmniPose-Lite) or larger versions with careful and extensive augmentations.
Summary
The Human Pose Estimation task is a challenging but interesting field, widely used in sports and gaming. In this article, we have covered a wide variety of information — from basic definitions and difficulties through some use cases, metrics, and datasets to evaluate models and most influential top-down and bottom-up approaches, including the ones which are current SOTA.
Originally published at https://www.reasonfieldlab.com.
Human Pose Estimation — 2023 guide was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.