A steroid-filled intro to GPUs — for data scientists

As a data scientist who has traveled between research and industry, I’ve seen the wild west of GPU usage. No matter where you roam, it seems like we’re all making this more difficult than it needs to be. From manual memory allocation to GPU roulette, our current approach to GPU usage is unproductive, inefficient, and costly.
In this article series, I’ll share my observations and experiences, sprinkled with a dash of humor, providing a practical and informative guide for data scientists looking to get the most out of their GPUs. In this first article, I will explain why our current mindset is very problematic and limits our productivity within data science teams. In the next article, we will dive into some open-source tools you can use to take the next step to optimize them while uncomplicating your life.
This series will serve as a humorous diary of a data scientist who had to let out what she learned and vent. So, sit back, grab a snack, and prepare to laugh your GPUs off.
Why You Should Care About GPUs
You might be thinking, “Why should I care about GPUs?” Well, my friend, it’s simple: GPUs are the horsepower behind deep learning. Especially with the current trend of large language models with billions of parameters such as GPT-3, they become an essential component of deep learning, as they provide the computation power necessary to tackle complex tasks compared to CPUs.
As Professor Richard Sutton, a professor of computing science and research scientist at DeepMind, emphasized in his post, “The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective and by a large margin… Seeking an improvement that makes a difference in the shorter term, researchers seek to leverage their human knowledge of the domain, but the only thing that matters, in the long run, is the leveraging of computation” [1].
If you want to get ahead in the AI game, you need to leverage GPUs, and you need to know how to do that.
Disclaimer: Apart from GPUs, we also see TPU adoption in the field. Because GPUs are very abundant in many PCs and NVIDIA is the main player in this field, I will not cover TPUs in this series.
Why Having GPUs Is Not Enough
But it’s not all sunshine and rainbows in the GPU world. Utilizing GPUs effectively can be challenging, especially for data scientists with limited resources and time. For the projects I have worked on so far, I’ve been lucky enough to have a GPU or two at my disposal, but I always had the mindset that more is always better. Who says no to more resources?
But, I learned that utilizing those is a completely different story.
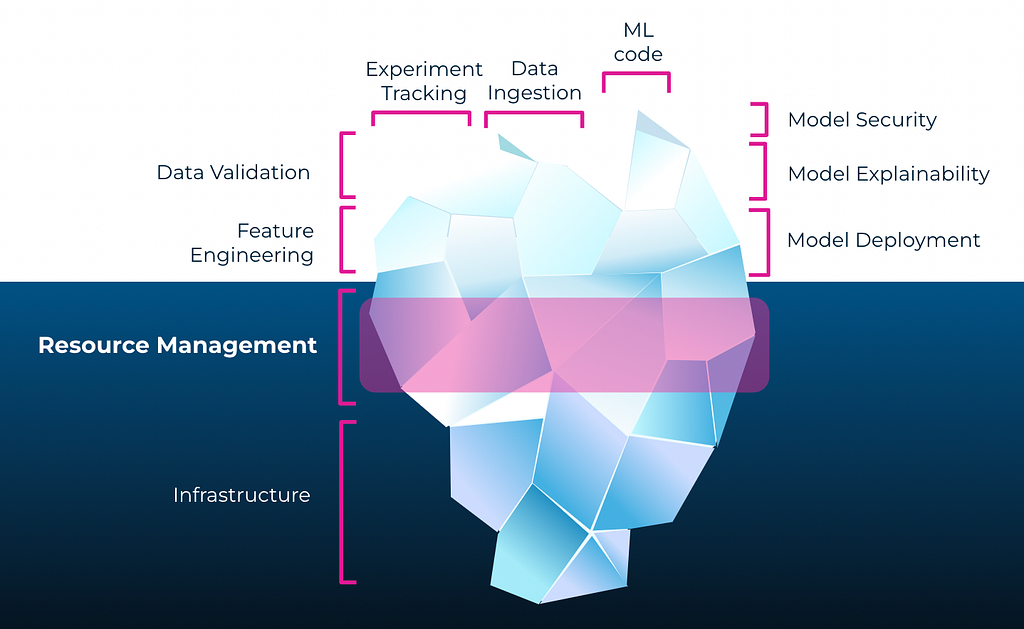
We call it resource management; you call it whatever you like — it is lying in the deep down of our AI iceberg. Out of sight, not caring too much, we are all concentrated on data cleaning, feature engineering, and model creation. But the bottom of the iceberg is the part that keeps the above nice and pointy.
So, you need some resources to run your experiments — trivial. But how do you manage them? For a very long time, this has also been a part that I didn’t even know that it exists or matters. After talking with many data scientists, I concluded that GPUs often fall by the wayside in our daily routine as we focus on other aspects of our projects, such as data cleaning and experimentation.
Why We Need To Change the Way We Work With GPUs
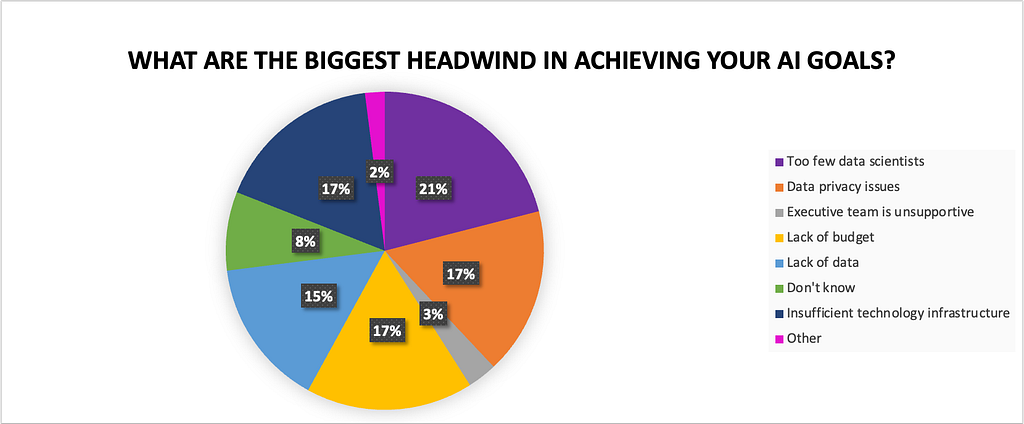
Now that we see that GPUs are important, and using many GPUs enables us to do even more, why is it the case that this infrastructure is seen as a major hindrance for organizations’ AI goals with almost 20% of IT/technology, engineering/research, and data science participants reporting? [2]
So, it is not just about buying them (expensive, but not the problem), but rather that most teams cannot leverage them properly. Even if it seems like the infrastructure is insufficient, there is a bigger problem lying down at the bottom.
After observing the GPU utilization of data science teams, we always see the same picture; the average utilization is much less than 20%. This means you are not actually out of resources.
This problem is getting more and more attention also in bigger cooperations. When John Carmack, the executive consultant for VR at Meta, announced his resignation with a Facebook post, he also explained his exhaustion about the inefficiencies he witnessed with the following words:
“The issue is our efficiency. Some will ask why shouuld I care how the progress is happening, as long as it is happening? If I am trying to sway others, I would say that an org that has only known inefficiency is ill prepared for the inevitable competition and/or belt tightening, but really, it is the more personal pain of seeing a 5% GPU utilization number in production. I am offended by it.
We have a ridiculous amount of people and resources, but we constantly self-sabotage and squander effort. (…) There is no way to sugar coat this; I think our organization is operating at half the effectiveness that would make me happy.”
However, this is not something you can’t fix — but it will happen step by step. You need some tips and tricks to avoid these pitfalls in front of your AI journey. So, let’s rev up those GPUs and get ready for an optimization rodeo!
Problem #1: The Way We Utilize GPUs
All AI workloads are equal, but some of them are more equal than others
Even if we are talking about deep learning and how crucial it is to have a GPU, many usage patterns are underutilizing the GPU by definition. While writing our code on VS Code or Pycharm, building our models interactively on Jupyter Notebook, debugging your code, etc., we don’t use the whole capacity of the GPU. Some GPU workloads have CPU or IO tasks, which leads to underutilized GPUs that can be leveraged by others in the team for GPU-heavy training tasks.
Problem #2: The Way We Assign GPUs
Static GPU assignments are not efficient
Have you ever been in a situation where you were waiting for a GPU to become available while it was unused by someone else? This is a common problem many organizations face that assigns either one GPU or one GPU machine per person or a specific number of GPUs per project. It is called static GPU assignment. Despite its initial appeal, this method leads to bottlenecks, delays, and inefficiencies in practice.
The 2023 State of AI Infrastructure Survey revealed that only 28% of the practitioners had on-demand access to GPUs. 51% of the rest are going through a ticketing system, while 31% are getting access to resources statically for users/jobs.
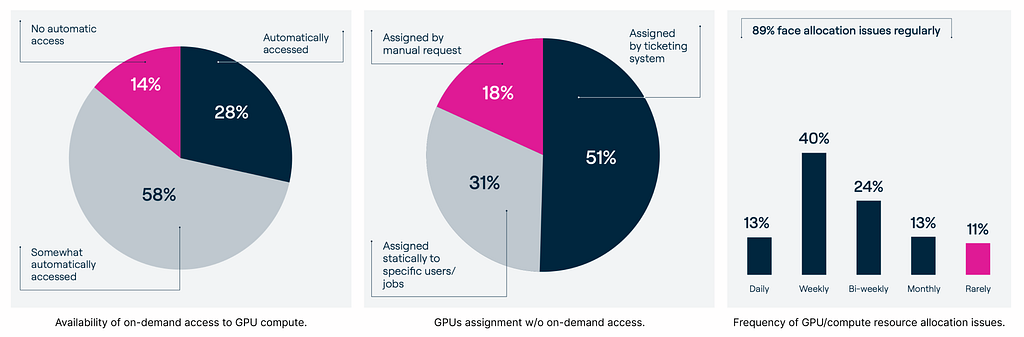
When asked how frequently they face resource allocation issues, only 11% stated a rarely occurring issue. 40% face weekly, and 13% face daily issues. In total, 89% reported regularly faced allocation issues [3].
That means 89% of the data scientists, ML engineers, and data engineers must go through a painful process of managing the resources between team members and other teams on top of their job duties. Let that sink in.
Problem #3: The Way We Share GPUs Within the Team
Spreadsheets and whiteboards are time-consuming
When sharing GPUs between teammates assigned to your team, the static go-to option becomes the old-school Excel sheets or whiteboards — you write your name to the days/time slots you plan to use GPUs and others not using those machines on those days. At first sight, it seems like a good idea, but in reality, this can lead to the following:
- Over-estimation of needed GPUs and/or required time for your project. This ends up with GPUs being unused while your teammates are waiting for resources.
- Forgotten reservation times were scheduled weeks ago (it happens; we are all human). The workflows of the teammates halted again.
Doing nothing is not an option
As data scientists, we all went through the ‘doing nothing’ path. We’ve all been there, eagerly setting up our virtual environment and firing up our experiments, only to be met with a harsh reality: ‘RuntimeError: CUDA Out of memory’ But wait, it gets even better.
I’ve heard rumors of many sneaky data scientists using dummy scripts to hijack GPUs overnight, leaving the rest of us with no chance of running our experiments the next day. If you are one of those, get ready — I will dedicate a whole article on shameful-data-scientist stories so that your coworkers can know what you are up to 😛.

{kind=link}
So, let’s go back to our story — after seeing this GPU is not available, naturally, you SSH to every single machine, give nvidia-smi a try on the terminal, and hope to find an available (or not-hijacked) machine during the day. If you are lucky, you find it quickly. If not, tomorrow is a bright new day — one step closer to your deadline, though…
So, you don’t know when the experiments will end. There are two options:
- You either need to SSH to the machines regularly to make sure you allocate one today
- You will ask around to see who is running what, when their deadline is, when it will end, and when you can take over
Conclusion: These Methods Are Financially and Motivationally Not Sustainable
Doing all this manual work is possible but time-consuming for the team and expensive for the companies.
As data scientists, ML engineers, and data engineers, we already have a lot of things to do, from experimenting with HPO to data cleaning, feature engineering, and many more. We all know that the more experimentation and exploration time we have with our data, the better the results. Managing and trying to get access to the resources only to start working should not be a challenge — it is demotivating in the long term. See the resignation post of John Carmack again.
Apart from that, as data scientists, ML engineers, and data engineers, our salaries are among the highest in the job market. If managers don’t make it easier for us to use the expensive GPUs and talent they’ve acquired, there’s room for improvement.
What Is the Optimal Setup?
To solve these productivity and financial issues, we need to change how we work with GPUs. We need a systematic way to do the following:
- Allow everyone to access GPUs dynamically, whenever they need them
- Automatically understand the workload and make dynamic decisions (assigning multiple GPUs for heavy training jobs, moving interactive sessions to CPU or a fraction of a GPU, prioritizing inference servers, etc.)
- Offer a pool of resources that can be shared and utilized to their full potential
- Let us allocate only a fraction of the GPU for interactive sessions in Jupyter Notebooks, so others can use the rest for lightweight jobs.
With this kind of infrastructure in place, resources will be used to their fullest potential, freeing up time and effort for data scientists, ML engineers, and data engineers to focus on their work. And the good news is that the first step is not far off in the future — easy-to-use tools are already available for data scientists. We’ll dive into these tools in detail in the next articles.
Final Thoughts
For data scientists, managing infrastructure and sharing resources can be a real headache. But, GPU orchestration and allocation are keys to the success of AI projects and should not be neglected. The current trend of large language models and datasets requires a change in the old-school way of using GPUs and a departure from traditional methods to utilize resources efficiently. Getting stuck in old and outdated methods means limiting your potential.
As a data scientist, you already know the building blocks of your ML system, but the infrastructure is where it gets tricky.
Chip Huyen, the author of “Designing Machine Learning Systems,” emphasizes the significance of infrastructure in the following manner: “ML systems are complex. (…) Infrastructure (…) can help automate processes, reducing the need for specialized knowledge and engineering time. This, in turn, can speed up the development and delivery of ML applications, reduce the surface area for bugs, and enable new use cases. When set up wrong, however, infrastructure is painful to use” [4].
In the next article, I will show you the best practices to boost productivity in data science teams while keeping this tricky part as simple as possible. I will not only introduce you to the open-source project “genv” but also demonstrate how to change ‘the way you GPU’ and make the most out of your resources in a smarter way. And, of course, I will do all this without getting bogged down in the technicalities of the GPU world. Get ready for some smart, efficient, and fun ML work!
Want to Connect?
So if you're looking for someone to geek about data science and
pesky infrastructural bottlenecks, ping me on LinkedIn or on
Discord (AI Infrastructure Club).
References
[1] R. Sutton, “The Bitter Lesson,” March 13, 2019
[2] Weka.io, “The State of AI and Analytics Infrastructure 2021,” February, 2021
[3] Run:ai, “The 2023 State of AI Infrastructure Survey,” February, 2023
[4] C. Huyen, “Designing Machine Learning Systems,” May, 2022
[5] T. Brown, B. Mann, N. Ryder, M. Subbiah, J.D. Kaplan, P. Dhariwal, … & D. Amodei, Language models are few-shot learners. (2020). Advances in neural information processing systems, 33, 1877–1901.
[6] N. Romm, R. Rotenberg, “Are You Really Out of GPUs? How to Better Understand Your GPU Utilization,” October, 2022
How To Not Use GPUs was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.