The next evolution of Azure OpenAI GPT models: A guide to executing functions

The torrent of new large language model developments is seemingly never-ending.
One moment we’re creating cyberpunk tales in the style of Shakespeare, (“In the neon-glowing twilight of the city’s metal forest, steel-throated couriers of data didst flit like phantoms”), and the next, we’re automating entire workflows leveraging tools like LangChain.
I’m not crazy; you’re crazy!
It’s an amazing time to be alive and embedded in the technology landscape, but relying on LLMs to be consistent and accurate in the information it provides is still not without pitfalls.
You’ll hear the term ‘hallucination’ used when a large language model essentially ‘makes stuff up’ or seemingly gets confused by outputting information that sounds factual but isn’t, but that’s just a neatly anthropomorphic term for what’s happening under the hood.
In reality, each word prediction as part of an LLM response is made by calculating a probability distribution over the entire vocabulary of the model. The key word there is probability.
At the foundation of a large-language model are a number of probabilistic formulas which provide that human-like response and reasoning. In part, this is what gives models the ability to respond differently when asked the same question more than once. This is fantastic for creative work like fiction writing or poetry, but what if you need precision? What if you relying on whatever probability soup is cooked up at the time isn’t helpful? What you’re really looking for is a deterministic response. One that is rigidly controlled both in inputs and outputs.
After all, let’s say you wanted a chatbot interface to talk to your customers about the offers and rewards they get as a part of your loyalty program. This is not an area where you want a hallucination to cause your model to confidently tell a customer that they’re entitled to eleventy billion dollars in rewards.
Because you just know they’re going to take that to heart and turn up at your store ready to spend that bounty.
Functions to the rescue
Now in our loyalty chatbot example, it is possible to generate factually correct responses by feeding a bunch of context about your rewards program to the model during conversation, and hoping that the right answer will come back out, but it’s far from an exact science. You’re basically rolling digital dice every time and hoping for the best.
That isn’t a way to deal with precise information. What we need is a way to further control the way in which our model accepts information and produces results.
A perfect use case for function calling.
As of a July 20th update message from OpenAI, the news came out that the ‘Completions’ API (so beloved by developers around the world) now has an optional ability to accept ‘functions’ as a part of the conversational flow.
In essence, this means you can now pass not just conversations and context to your large language model implementation, but also pass instructions for the use of programming functions (methods) that can be executed as a part of the conversational flow.
This blows the range of use cases for a large language models wide open. Now, you can create a ‘send email’ function in Python for example, then ask your large language model to send an email to your friend to set up a coffee date at myfriend@friend-email.com.au. Because you’re also passing in the instructions to execute your ‘send email’ function, the model can actually compose the steps required to execute your code, determining not only the right function to call but also extracting the right parameters to use (in this case, the email address of your friend).

This ability to execute functions also allows you to ensure the accuracy and reliability of tasks that your large language model takes on as a part of the conversation. Because you write the function(s) you control the input parameters, the logic, and the output. Assuming the model correctly identifies your function as the one to execute based on the context, you can rest assured that the answers will be what you expect.
With that in mind, let’s think back to our example about the loyalty program. Instead of leaving it up to the LLM and raw information to provide the right responses to our customer queries, let’s instead create a Python function that calculates our rewards and gives back a consistent response every time and use that in our conversations!
Thanks to Microsoft’s brilliant implementation of the OpenAI models within the Azure AI Studio we can safely experiment with all these possibilities without having to expose our information outside the walls of our Azure tenancy, and that’s what we’re going to use in the following tutorial. The function calling feature is in Preview in Azure OpenAI as of a few days ago, so you should now have access to start playing around!
You can modify this example to utilise OpenAI services/APIs directly but to follow along verbatim, you’ll need the following:
- An Azure subscription
- An Azure OpenAI service created
- A deployed gpt-35-turbo model of version 0613* (see below)
- Access to a Jupyter notebook, either locally or via a service like Azure Machine Learning Studio or Google Colab.
*A note about version 0613
A ‘gotcha’ I encountered while constructing this piece, was that my existing Azure OpenAI studio didn’t seem to have version 0613 of the gpt-35-turbo model. Despite clicking around all the available UI buttons, I could only seem to deploy or utilise version 0301 of the model.
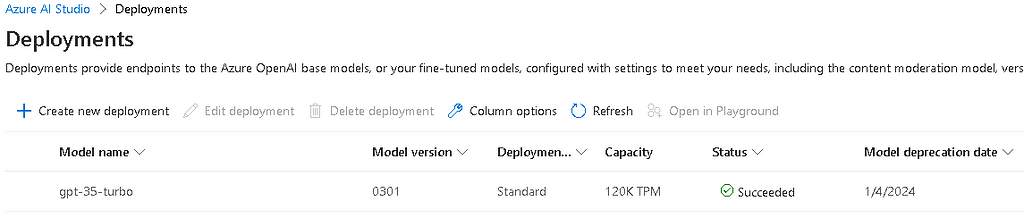
It turns out I’m not alone in this problem. I solved this by creating an entirely new OpenAI service in Azure, but this time instead of the South Central US region, I deployed my new service to the East US region. Once this was done, I could deploy version 0613 of the model which includes the optional functions… er… functionality.
From here on, it’s time to jump into a Jupyter Notebook and follow along in Python code. Are you ready? Great! If you want to, feel free to grab the complete notebook from my GitHub repository (you’ll need to supply your own service details though).
Defining our functions
To start with, let’s set up our environment. Ensure we have the latest version of our libraries and set up the configuration of our Azure OpenAI endpoint/deployment.
# grab the latest openai libraries
%pip install --upgrade openai
import openai
## Set up our Azure OpenAI service
deployment_id = "shiny-new-model"
openai.api_type = "azure"
openai.api_key = "<Your key here>"
openai.api_base = "https://<Your endpoint here>.openai.azure.com/"
openai.api_version = "2023-07-01-preview"
In our use case, we’re operating a special loyalty program for OpenAI users called OpenAI Bucks. Essentially, you’ll earn a bunch of points for interacting with OpenAI services, and depending on your tier, those points will be converted to a certain amount of cold hard OpenAI bucks.
Obviously, we want our large language model to be able to provide accurate and specific information to our customers about how much money they’ll get for having different amounts of points. To do this, we’ll create a function that will provide this information:
# Lets create our function to use with OpenAI. In our use case, we want the model to be able to accurately calculate
# how many open ai bucks a customer is entitled to based on their loyalty tier.
def calculate_openai_bucks(tier, points) -> str:
# defining the conversion rates for each tier
tiers = {
"bronze": 1,
"silver": 2,
"gold": 5
}
if tier.lower() not in tiers:
return "Invalid tier. Please provide a valid tier: bronze, silver, or gold."
if int(points) < 0:
return "Invalid points. Please provide a positive number of points."
openai_bucks = tiers[tier.lower()] * int(points)
return "${:.2f}".format(openai_bucks)
# Let's also create a second function just to show that the model will choose the right function from those available
# based on the context provided in the conversation
def reverse_string(s):
return s[::-1]
You’ll notice I’ve created two functions. One handles our loyalty ‘bucks’ calculation and the other reverses a string. This is to show that we can pass multiple function definitions to our model, and if all goes well, it will identify the right function to use based on the context of the conversation. Here’s a quick test of our functions:
# lets test our functions first
display(calculate_openai_bucks("silver",100))
display(reverse_string("Show me the moeny!"))
$200.00
!yneom eht em wohS
OK, looking good! But how do we get a function executed?
It’s important to note that working with functions in your large language model doesn’t actually mean the model executes your functions. Your code is never run by the model, instead, it’s run locally, and the job of the model is to help find the right function to be run with the right parameters and finally ‘humanise’ the output from the execution of that function.
To do that, the normal completions workflow of ‘here’s a message with context’ and ‘here’s the response’ is actually broken up into two distinct completions workflows.
Let’s have a look at how that works:
The two-stage function calling workflow
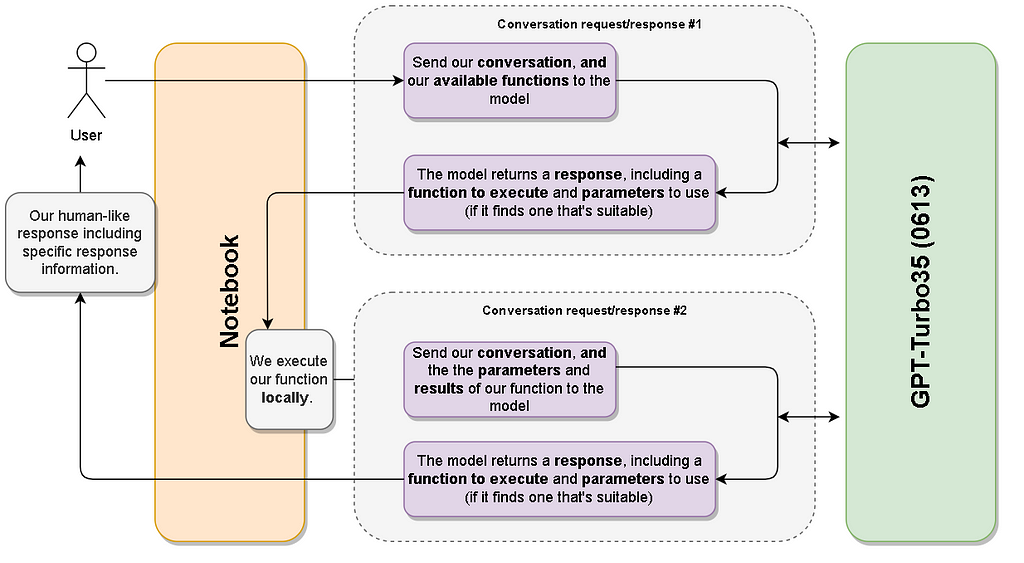
As you can see, the first sequence is the model working out the right function to call and sending that back along with any inputs to the caller. Your code then executes, and a second sequence takes the results of the function execution and passes that to the model to produce a final conversational output.
But how does the model pick the right function? How does it even know how to pick the right function? To do that, we need to provide a description of our functions to our model.
Straight from the Microsoft documentation, we learn that a function has three main parameters: name, description, and parameters. The description parameter is used by the model to determine when and how to call the function, so it’s important to give a meaningful description of what the function does.
parameters is a JSON schema object that describes the parameters that the function accepts.
This means we need to explain our function to the model using some JSON-structured text. Let’s go ahead and do that for our two functions:
# We need to create a description of our functions, a bit like a blueprint so that the model understands how to use them
functions=[
{
"name": "calculate_openai_bucks",
"description": "Calculate the number of openai bucks a customer is entitled to based on their loyalty tier and the number of points they have",
"parameters": {
"type": "object",
"properties": {
"tier": {
"type": "string",
"enum": [
"bronze",
"silver",
"gold"
],
"description": "The loyalty tier of the customer"
},
"points": {
"type": "string",
"description": "The number of points the customer has"
}
},
"required": [
"tier",
"points"
]
}
},
{
"name": "reverse_string",
"description": "Takes a string and reverses all the characters, then returns the new reversed string",
"parameters": {
"type": "object",
"properties": {
"s": {
"type": "string",
"description": "The string to be reversed"
}
},
"required": [
"s"
]
}
}
]
available_functions = {
"calculate_openai_bucks": calculate_openai_bucks,
"reverse_string": reverse_string
}
We’ve defined both our functions above, including a meaningful description (which helps the model choose) and a definition of the attributes that must be provided (which helps the model extract those attributes from the initial conversation).
We’ve also created an available_functions object that we’ll pass in our conversation method so we can check that the chosen function is actually from a set of functions we’re happy to execute.
We’ll also create a bit of a sanity check function to make sure the right arguments are being provided in a response. Why do we do this? Because despite function calling being about ensuring a deterministic and expected response the fact remains that even the model’s response about what function to call and what attributes to use is subject to probability. In essence, it’s still possible for the model to hallucinate its way out of providing useful information, so we need something to counter that.
I’m using the helper method sourced from the Azure samples repository.
# Sourced from https://github.com/Azure-Samples/openai/blob/main/Basic_Samples/Functions/working_with_functions.ipynb
# a helper method just to make sure that the functions are being used correctly
import inspect
# helper method used to check if the correct arguments are provided to a function
def check_args(function, args):
sig = inspect.signature(function)
params = sig.parameters
# Check if there are extra arguments
for name in args:
if name not in params:
return False
# Check if the required arguments are provided
for name, param in params.items():
if param.default is param.empty and name not in args:
return False
return True
Lastly, let’s bring all of our work together into a method we can use to initiate the conversational exchange between the user and the model and get back the final response:
from openai.api_resources import model
import json # needed for this function
def process_chat_with_function_calls(messages, functions, available_functions, deployment_id):
try:
response = openai.ChatCompletion.create(
deployment_id=deployment_id,
messages=messages,
functions=functions,
function_call="auto"
)
response_message = response["choices"][0]["message"]
function_call = response_message.get("function_call")
if function_call:
print(f"Recommended Function call:n{function_call}n")
function_name = function_call["name"]
if function_name not in available_functions:
return f"Function {function_name} does not exist"
function_to_call = available_functions[function_name]
function_args = json.loads(function_call["arguments"])
if not check_args(function_to_call, function_args):
return f"Invalid number of arguments for function: {function_name}"
function_response = function_to_call(**function_args)
print(f"Output of function call:n{function_response}n")
messages.extend([
{"role": response_message["role"], "name": function_name, "content": str(function_args)}, # we convert to string because we have a dictionary of args, not just one.
{"role": "function", "name": function_name, "content": function_response},
])
print("Messages in second request:")
for message in messages:
print(message)
print()
second_response = openai.ChatCompletion.create(
messages=messages,
deployment_id=deployment_id
)
return second_response
except Exception as e:
print(e)
Remember we talked about the two-stage process? You can see that clearly in the code above. There’s the first ‘response,’ then the ‘second_response.’ The first is hopefully the right function to execute and the parameters to provide, then the second response utilises the results of our code to create the final output.
The test!
Let’s try it and see if our model can now confidently calculate how many OpenAI ‘bucks’ we’ll get!
messages = [{"role": "user", "content": "I'm a bronze loyalty member with 8 points. How much value do I get??"}]
assistant_response = process_chat_with_function_calls(messages, functions, available_functions, deployment_id)
print(assistant_response)
So we’re asking how many bucks we get as a bronze member with eight points. Let’s check our response data:
Recommended Function call:
{
"name": "calculate_openai_bucks",
"arguments": "{n "tier": "bronze",n "points": "8"n}"
}
Output of function call:
$8.00
Messages in second request:
{'role': 'user', 'content': "I'm a bronze loyalty member with 8 points. How much value do I get??"}
{'role': 'assistant', 'name': 'calculate_openai_bucks', 'content': "{'tier': 'bronze', 'points': '8'}"}
{'role': 'function', 'name': 'calculate_openai_bucks', 'content': '$8.00'}
{
"id": "chatcmpl-7fKBzrQO1xN96h8GpJvbAO596zTCq",
"object": "chat.completion",
"created": 1690083423,
"model": "gpt-35-turbo-16k",
"prompt_annotations": [
{
"prompt_index": 0,
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
}
}
],
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "As a bronze loyalty member with 8 points, you would have a value of $8.00."
},
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
}
}
],
"usage": {
"completion_tokens": 21,
"prompt_tokens": 60,
"total_tokens": 81
}
}
Breaking it down, we can see our initial question has been processed by the Completions API and the model has recommended the execution of the calculate_openai_bucks method, with the valid parameters to pass (and has ignored our other method for reversing strings).
{
"name": "calculate_openai_bucks",
"arguments": "{n "tier": "bronze",n "points": "8"n}"
}
That code ran locally and correctly showed the value as $8.00. This information is then passed back to the Completions API:
{'role': 'user', 'content': "I'm a bronze loyalty member with 8 points. How much value do I get??"}
{'role': 'assistant', 'name': 'calculate_openai_bucks', 'content': "{'tier': 'bronze', 'points': '8'}"}
{'role': 'function', 'name': 'calculate_openai_bucks', 'content': '$8.00'}
which can provide the final awesome output: “As a bronze loyalty member with eight points, you would have a value of $8.00.”
Fantastic!
We can even throw in slightly more complex examples like:
messages = [{“role”: “user”, “content”: “I’m a silver member, and I have 1200 points. Also, I got that bonus 800 points in the mail last week. How many bucks do I have to spend, please? “}]
And get back the following:
Recommended Function call:
{
"name": "calculate_openai_bucks",
"arguments": "{n "tier": "silver",n "points": "2000"n}"
}
Output of function call:
$4000.00
Messages in second request:
{'role': 'user', 'content': "I'm a silver member and I have 1200 points. Also I got that bonus 800 points in the mail last week. How many bucks do I have to spend please? "}
{'role': 'assistant', 'name': 'calculate_openai_bucks', 'content': "{'tier': 'silver', 'points': '2000'}"}
{'role': 'function', 'name': 'calculate_openai_bucks', 'content': '$4000.00'}
{
"id": "chatcmpl-7fMfMEbPVQtP6uqrOLMHTUh3eQbZX",
"object": "chat.completion",
"created": 1690092932,
"model": "gpt-35-turbo-16k",
"prompt_annotations": [
{
"prompt_index": 0,
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
}
}
],
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "As a silver member, you have accumulated 1200 points and received a bonus of 800 points, totaling 2000 points. Assuming each point is equivalent to $2, you would have $4000 in OpenAI Bucks to spend."
},
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
}
}
],
"usage": {
"completion_tokens": 49,
"prompt_tokens": 81,
"total_tokens": 130
}
}
We can see here that the model has first added the bonus points to the other points, before passing the final value back as an attribute with the recommended function to execute. The function has run, and we get back our final output of:
“As a silver member, you have accumulated 1200 points and received a bonus of 800 points, totaling 2000 points. Assuming each point is equivalent to $2, you would have $4000 in OpenAI Bucks to spend.”
So many bucks, where to spend first?
Hopefully, you’ve enjoyed this simple introduction to the why and how of function calling with large language models. This is very much a ‘scratch the surface’ example of what’s possible, and without a doubt, we’re going to see some fantastic and creative ways to combine natural language and function calling to produce incredible applications and interfaces.
If you’re interested in the official Microsoft documentation for how to use function calls, you can follow along at: https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/function-calling#defining-functions
As always, if you’ve enjoyed this article, please feel free to reach out with any comments or questions, and I’d be happy to help out.
How to Execute Your Own Code With Large Language Models (LLMs) was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.