
The Current Setup
I’ve been working ad hoc on a Smart Home Integration system for my house for about 7 years. The system consists of a few parts, including a Web UI, Chatbot, and API Server (I’ve documented it in detail previously). As the system has grown, I’ve neglected to really invest any time in the CI/CD side of things, opting to focus on new features and refactors over “Developer Experience” improvements.
As my role in my real job has grown, I realized just how important a good pipeline can be, to getting more time working on actual features — so I decided to do a bit of a technical spike this last winter, reworking the build system. The challenge is, I’m not at all a Platform Engineer — I’m a Lead API developer. Whilst there is some crossover, I know far more about writing integration code than I do about running it!
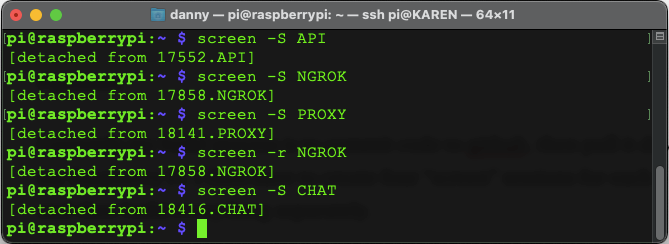
The system all runs on a small Raspberry Pi 3B+, so previously when I’ve wanted to “release” code, I’ve had to log in, pull down the code, edit all the environment variables to get reworking, and then run it using “screen” to ensure the session doesn’t die when I log off. Whilst this was fine when it was just an API — this just isn’t practical now having to run multiple screens for the Chatbot, API and Proxy server, and ngrok tunnel.

First Step: Shove it in a Monorepo
Part of the problem is that the system is all in separate repositories that all depend upon each other and change together. New features in the UI or Chatbot require API changes. I’ve often got two or three VS Codes running at once across desktops and it’s not productive. (It doesn’t help that my device is a 2014 Macbook Air on its last legs either!)
So I’ve migrated over to Turborepo. Instead of multiple repositories, I just have one now. The migration wasn’t too hard, I mostly followed the guide. I created a new “karen” repository and got it working with just the API initially. Once I was happy with that, I migrated the other packages. The example repository I used came with Monorepo-wide TSConfig and ESLint to reduce duplicate settings.
This has been a great experience so far as it’s a big bonus only having one set of settings and config. Given that I often don’t have a huge amount of time to work on this project, that sort of stuff often falls to the wayside — especially when I’m rapidly prototyping something new. Before long the “new” thing is a full part of the system but its entire config is a mess.
Additionally, some packages don’t get touched often — so fall behind. Overall I’m now on board with monorepos when they follow the key principle:
“Code that changes together should live together”.
Next up: Pipelines
Currently, my build process is to commit code to Github, then pull it down onto my Raspberry Pi. I then have to create four “screen” sessions for each product and then build everything separately.
The obvious solution for a long time has been to produce Docker images. Whilst the guiding principle is to keep as much as I can running locally, the convenience of using a cloud product for CI/CD was too alluring.
Given that I already use Azure Pipelines at work, I thought this was a good chance to use CircleCI instead and build up some skills. It also helped that it’s free.
Getting a pipeline building a Node.js project into a Docker image isn’t the cutting-edge story it was ten years ago — however, I did find it a bit of a challenge to get a Monorepo building individual repositories into individual containers.
Like all great developers, I stole some code instead of having to solve it myself. I found this incredible Bash script on Github that almost did everything I needed. It first runs a job to work out the delta between what’s been built previously and any new commits on the master. This job then spawns off a child job for each package which needs a new Docker image building. It will also check for any previously failed builds and retry those too.
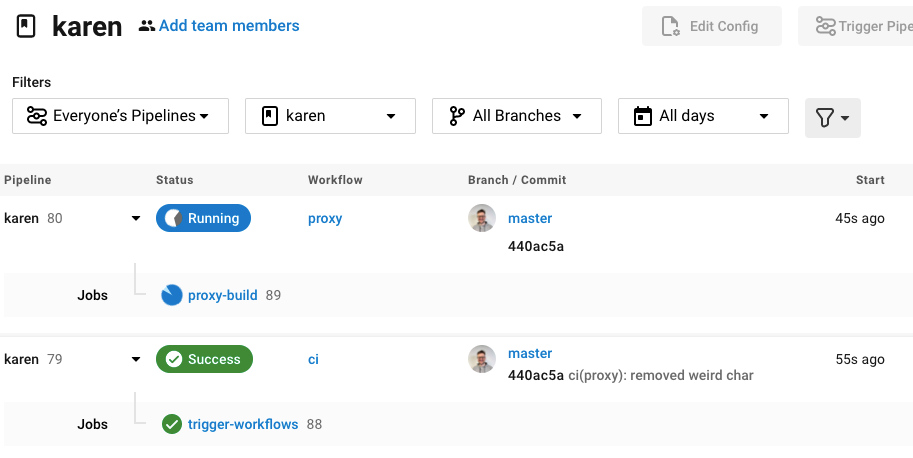
After a few issues (at one point I think Circle was hacked and they erased all the previous job history entirely — absolutely trashing the build system for a few days) I got it all building.
I did make a few tweaks — mainly exceptions to not spawn a job for the ESlint, TSConfig, or Web packages (The Web app is built on Netlify and hosted there instead of locally). I also added quite a bit more logging, just to help me understand what was going on.
This left me with a “trigger-workflows” pipeline which would trigger the standard config.yml build script in the root of my Monorepo, with a Docker build job for each of my containers. When the parent job decided there needed to be a new container, it would make a REST API call to the CircleCI API, triggering that job.
Now the Deliverables: Docker Containers
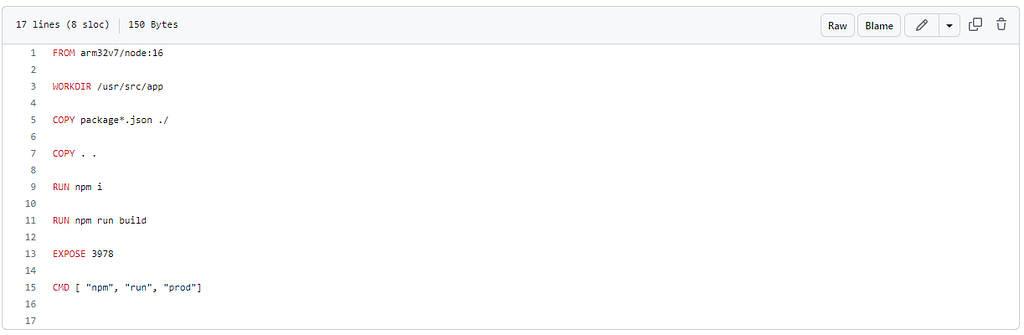
Now the pipelines were running and creating build jobs for my packages — they needed to actually build something. Currently, my Raspberry pi was running individual projects via git pull, npm build, and npm run prod — really grim stuff. I created an individual Dockerfile for each of the packages. These Docker images were really simple — in fact only a few lines. I’m not a platform specialist — as you can well see.
You might be thinking, how have you been working on this system for 7 years and only now building Docker images?! The answer is at the top of the piece — this is all running on a Raspberry Pi. About five years ago I did a similar spike to get Docker going — only to find that I couldn’t run most software on ARM architectures. It may have been possible but I wasn’t clever enough.
However, last year I came across something beautiful — arm32v7/node — a Docker image to get Node.js working on the Raspberry Pi’s architecture. Once I had this base image, all I needed to do was have the pipelines build containers and push them to a Container Registry.
It’s All Coming Together: Docker Compose
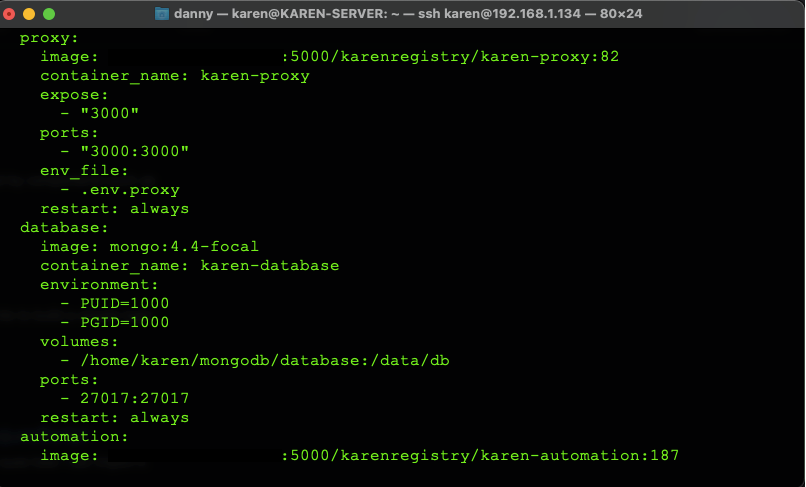
Now I had several different images sitting in a Container Registry (I used a free one: Canister). I didn’t want to go back to having to pull individual images down. Docker Compose is perfect for this. I created a really simple Docker compose file on the Raspberry Pi, with the “current” goal set up (i.e. the correct versions of each container).
Given that there is an insane amount of configuration for some of the containers (there are about 40 values for the API to allow it to connect to all the different APIs and products in the home!) I ended up creating individual .env files for each, and referencing them into the compose.yml file instead of a massive lump of a document. This worked really well as it focuses the file entirely on the actual versions running — and allows it to be committed into version control.
At some point, I’d like a webhook of some sort to pull the latest YAML file down, but for now, I just jump on the box and change one or two values to update it. Additionally, the containers all spin back up if the Raspberry Pi turns off for some reason — so it’s much more resilient.
This CI/CD pipeline has rapidly improved the overall development experience on the project (which is great since I’m the developer).
Additionally, I now get much more done in the time I am working on it all. I’ll admit it was frustrating not adding anything new for two months whilst I put this together. I’ve been able to spit out far more stuff this year!
How I Built the CI/CD Build Pipeline for My Smart Home was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.