
I learned three critical lessons using large language models (LLMs) during the summer of the generative AI hype. These lessons should be valuable for years to come.
1. “Prompting” means “auto-complete”
2. Define success
3. Experiment with rigor
Let’s dive into these in detail.
“Prompting” Means “Auto-Complete”
The Merriam-Webster definition of ‘prompt’ is instructive: “to assist (one acting or reciting) by suggesting or saying the next words of something forgotten or imperfectly learned: CUE.” Hold that thought.
The technique behind large language models is predicting the next series of words given a series they have just seen. More simply, most large language models are playing a giant game of auto-complete. The magic and the hype are largely around how much they can complete, i.e., the length of the auto-correct.

My historical experience with autocomplete includes the following:
· Words: My phone auto-corrects a misspelled word or auto-completes a word from a fragment (“I am glad to have this opportunity”)
· Sentences: My email application finishes my sentences (“We had a great time this weekend. Thank you for everything you did for us! We should get together soon.”)
· Paragraphs and more: Generative AI applications powered by LLMs can write entire emails, poems, blog posts, and more. (“Talk like a pirate. Jolly Roger, aaarr!”)
Notice the generated text (in italics) gets longer and longer. Thus, my mental model of this technology is “even bigger auto-complete.” (Remember: All models are wrong, but some are useful.)
Let’s parse a key statement: “Generative AI applications powered by LLMs.” We often conflate “generative AI applications” with LLMs. This leaves out an important context. LLMs are a low-level API compared to an easy-to-use application. We hear so much about prompting because prompts are how you talk to LLMs. Prompts are not necessarily how you talk to applications.
The most famous Generative AI application today is ChatGPT. ChatGPT is an application. The interface is a simple chat interface — you interact with a simple text box. You can fill the box with anything: a question, instruction, a statement, or more. ChatGPT responds like a chatbot that speaks in human-like responses. Try it: Give ChatGPT an instruction like “Tell me a joke about technology.”
Compare this to building chat from scratch using a large language model. You cannot just pass this simple instruction to an LLM text generation API.
I tried to, and this is what happened:
Tell me a joke about technology. The new wireless router is much faster than before.
I love my smartphone. I can use it to check my email, access the internet, take pictures, and even make phone calls. It’s so handy.
The generated text is coherent English, looks natural, and is on-topic about technology, but it misses the point — the response isn’t a joke!

A generative AI application can carefully craft the right prompts for an LLM to yield the desired output. A good prompt is not just an instruction. A prompt includes things like context, introduction, and cue. Here’s a prompt and response I got from a large language model API.
You are a humorous chatbot. The user will provide you with a topic. You should respond with a joke. Your joke should be based on a fact and stretched to absurdity.
Topic: technology
Joke: Technology is the art of making things that do not work to work.
This prompt is annotated in the next figure.

The low-level LLM API requires many more details than a generative AI application. You don’t need to tell ChatGPT that it is a chatbot, you don’t need to describe how chat works, and you don’t have to give it a cue to complete from. (It does this for you behind the scenes and includes other helpful contexts like your past conversational text.)
This is why prompt engineering is a growing field. It takes effort to generate a good prompt that cues the LLM to give you what you want. Applications like ChatGPT require less prompt engineering than the raw LLM APIs underneath them (even if you can “prompt engineer” ChatGPT itself).
The extra work can generate extra benefits. You can build a trusted Conversational Search pattern by engineering your prompt and application to answer a question from your documents. The following figure shows the difference between what the user sees in the generative AI application versus what the large language model receives. (This is often called “prompt templating.”)
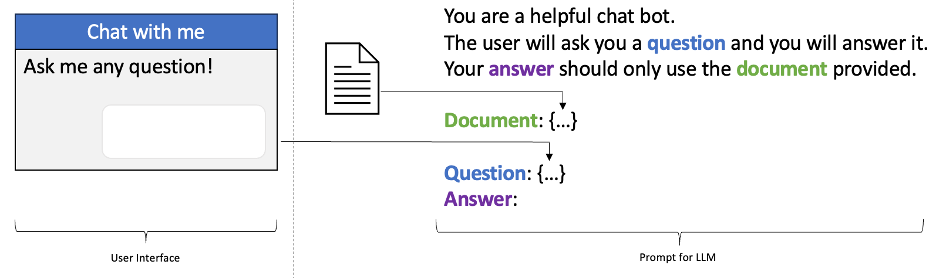
Generative AI applications are engineered to be good at doing what we want; large language models need to be prompted to produce good output.
Define Success
The possibilities seem endless. LLMs and Generative AI let us attempt things we’ve never tried before. But how do we know if they are performing well? We need to define what a successful response means to us. Success will be defined differently depending on the task you are trying to achieve.

There are three ways to evaluate responses from large language models. Here they are in order of complexity:
· Validate against the “one true answer”
· Quick/qualitative measurement
· Thorough/quantitative measurement
Validate Against the “One True Answer”
The simplest evaluation is when there is one correct response to the prompt. This is common in many classification tasks. For instance, the sentiment of “I am very upset with your service!” is “negative,” and “I could not be happier” is positive. These tasks are evaluated with metrics such as accuracy or F1 score — all based on counting the number of correct responses.
A slight variation on this approach is required in some question-and-answer scenarios. Consider the question, “Who is the author of this blog post?” According to Medium.com, the answer is “Andrew R. Freed,” but if your LLM said “Andrew Freed” or “Andrew Ronald Freed,” is that answer incorrect? According to absolute metrics like accuracy and F1, these answers are incorrect, but they are “good enough” for most tasks. When you have “one answer” but exact-match is not required, a metric like ROUGE is better.
If there is a correct answer, you can create an “answer key” (also called “ground truth”) and use it to validate LLM responses by exact-match or near-match.
This approach is useful in classification, entity extraction, and some question-and-answer tasks.
Quick/Qualitative Measurement
Some tasks have many possible good answers. Consider “Define generative AI” — there are hundreds of definitions. Some answers are better than others — is it important to grade the differences? The figure below shows two examples of qualitative metrics:

These metrics include a color component and a numerical component. The color component helps you capture your “feel” when evaluating responses. A visualization including colors is visually striking and tells a story faster than words will. A numerical component helps compare responses from multiple models. You can say, “model X performed 20% better than model Y according to my scale.” Please note the example colors and scores are illustrative — you can use whatever scale seems most useful to you.
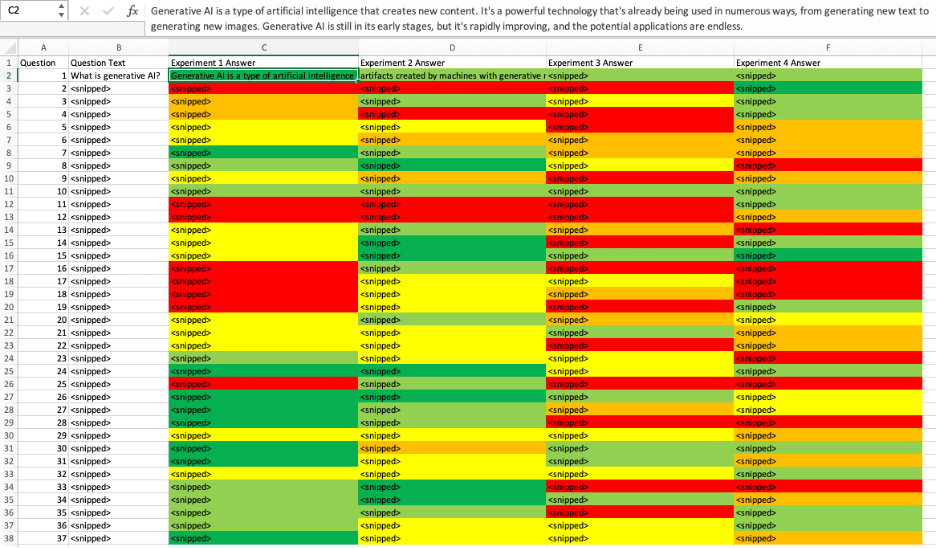
In this measurement style, you need agreement on the difference between the ratings. A simple scale makes agreement easier, and a more complex scale gives more information. I recommend not going higher than five dimensions for this quick evaluation, especially if multiple people are evaluating. Otherwise, it will be hard to be consistent. This measurement style is most useful for “at a glance” evaluation. It is useful in multiple patterns, including Conversational Search, Summarization, and many other generative tasks.
Thorough/Quantitative Measurement
If you need more information than “at a glance” can give you, you can move to a more complex scale. This is especially important in differentiating between “bad” answers. For instance, which model is worse if one model gives more terse responses and another gives more hallucinations? According to the “at a glance” metric, they may be equivalent. The figure below shows an example scale I used in evaluating Conversational Search experiments:

This rubric is significantly more complex. It requires buy-in from an entire team, which must agree on the following:
- What dimensions are important to us?
- How should we differentiate within those dimensions?
- Can we produce consistent evaluations of this rubric?
This approach requires a formal grading rubric with examples. Multiple team members must try it out, and you need to determine if different members give the same scores for the same answers. (This is called inter-annotator agreement.)
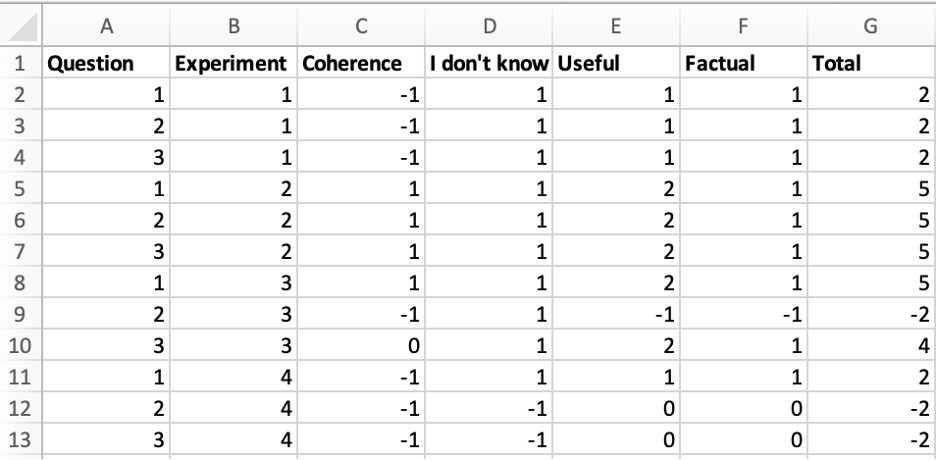
As you may expect, this approach takes much longer than the “quick evaluation.” However, it gives you much richer information. Now, you can make tradeoff decisions backed by data.
- Is a longer response okay if the structure is poor?
- Does the benefit of using outside contextual information outweigh the increased chances of hallucination?
- Do more expensive models justify their increased cost with more useful answers?
An example summarization is shown below. This format is easily sorted on whatever dimension is most important to you.
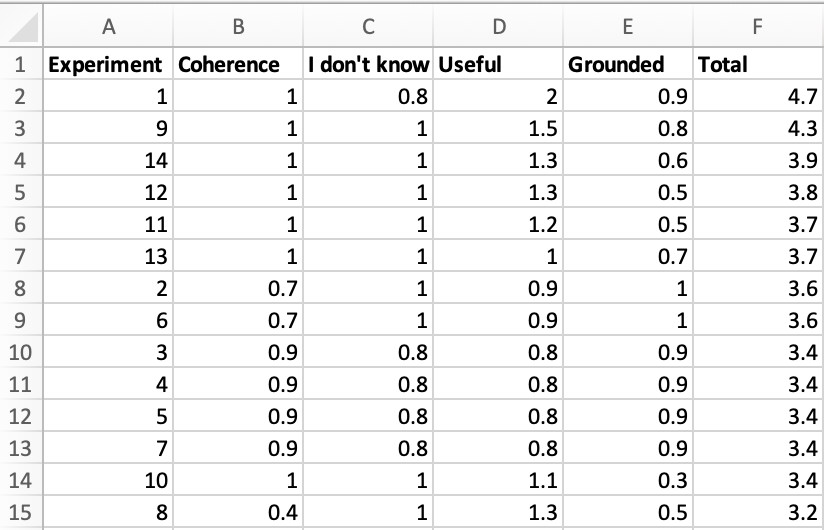
This measurement style is useful in Conversational Search, Summarization, and many other generative tasks.
Each of these evaluation methods demonstrated results across experiments. The latter evaluation methods hinted at the experiment’s setup. Let’s dive deeper into the experimentation process.
Experiment With Rigor
LLM providers often build a sample UI for you to try out their service. Often, it is a graphical interface with a text box for a prompt and maybe a few dropdowns or sliders to select models and configuration parameters. It’s quick and easy to try out a few examples, but it gets tedious after a handful of tests. Worse, tracking what you’ve done and how you felt about the results is hard.
For example:
- “I think I liked model X better at first, but now I think I like model Y.”
- “I know I tried changing the temperature, but I can’t remember how much of a difference it made.”
- “It seems like it depends on the question. Sometimes model X is better, and sometimes model Y.”
There’s no substitute for some experimental rigor. You must try multiple experiments before you can build certainty from your results. This includes trying multiple prompts, inputs, models, and/or parameters. One test is never enough. You will need to try variations.
For a sniff test, you may test five input variations. For more significant results, you will want to test ten or more. (You likely need more stringent tests, checks, and balances to satisfy regulatory or compliance concerns. There is a tradeoff in time spent evaluating versus the marginal information gain, but you don’t want to make a hasty choice based on one or two tests.
Write everything down! There is so much information you will want to track; you will never remember it all.
For instance, in a Conversational Search evaluation, I tracked and created a static test set of 37 questions. For each question, I tracked the following:
- ID: An auto-numbered identifier
- Text: The literal text of the question
- Category: The source of the question. (I pulled questions from Slack verbatim and reworded them, plus I created my own questions.)
I also tracked my Conversational Search experiments. Every time I wanted to make a change in my Conversational Search solution, I tracked the following experimental settings:
- ID: An auto-numbered identifier
- Prompt: The file name of the prompt. (I used prompt template files stored in GitHub)
- Model: Name of the model
- Context Source: The search methodology, as well as any search parameters
- LLM parameters: Minimum/maximum output tokens, temperature, repetition penalty, stopping criteria
The figure below shows how I tracked the experiments:
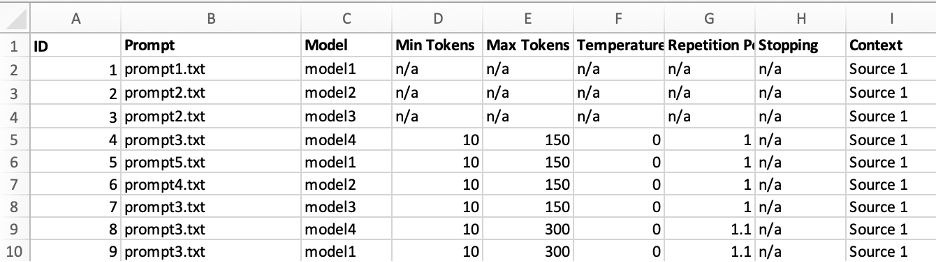
With the experiment details in hand, I could build scoring sheets to share with my team. The team could see the questions and associated answers and then fill in the scoring guide. An example scoring sheet is shown below:
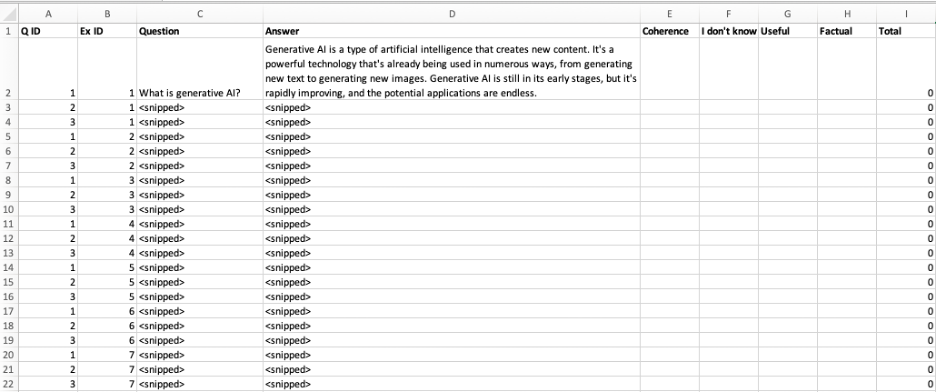
Note that I did not include the experimental details on the sheet for the scorers — only the experiment identifier. This was done to avoid biasing the experimenters, so they could not implicitly prefer a specific model name or prompt style.
Conclusion
This article shared my mental model of large language models — how to use them to get what you want and how to evaluate what they’ve done. There are new advances in the field every day, but these fundamentals will be useful. Prompting may get easier over time and, in some cases, may get invisible, but we will always need to evaluate generative AI output in a structured way.

Thanks to Stefan van der Stockt for reviewing this article!
Generative AI Mindset was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.