Vows, Rings, and Distributed Transactions: A Microservices Marriage Ceremony

Picture this: you’re piecing together a grand puzzle, where each piece is sourced from different places. Every piece is unique, important, and vital for the final image. But what happens if one piece doesn’t quite fit or goes missing? The entire masterpiece is compromised. Similarly, in microservices, each service is like a distinct piece of this puzzle, operating with its own datastore. The challenge?
Ensuring every piece fits seamlessly, especially when data flows between them. In a world promising flexibility and scalability, this decentralization can sometimes lead to potential disarray, especially during service failures. Join me as I delve into the intricate problem of ensuring data consistency in the microservice mosaic and highlight effective strategies to ensure every piece aligns perfectly.
Decoding the E-commerce Checkout: A Journey Through Microservices
Consider the intricate dance of an e-commerce checkout process. This choreography involves multiple actors:
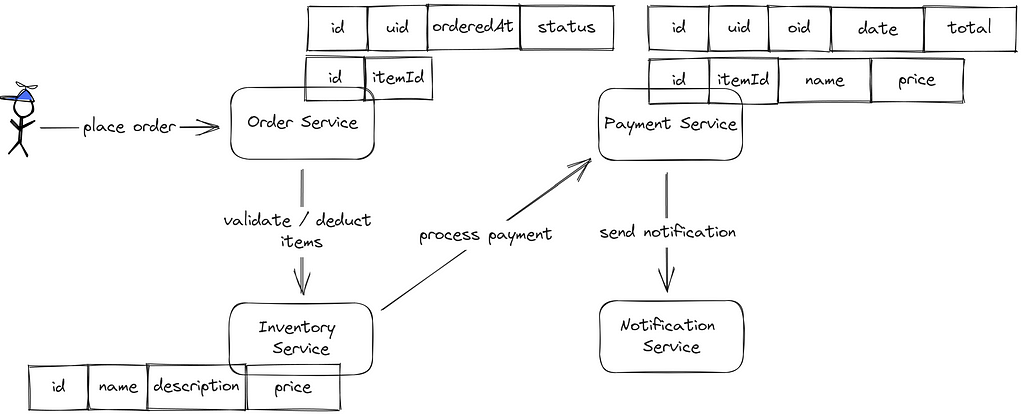
- Order Service: This service takes charge of the order data. It contains details such as order id, user id, timestamp of order, and its current status. Additionally, it holds the relationship between the order id and the items ordered.
- Inventory Service: The primary custodian of inventory-related data. It keeps track of details like item id, its name, description, and price.
- Payment Service: This powerhouse deals with payment data and often liaises with external payment gateways like Stripe or PayPal. The stored information includes payment id, total amount, user id, order id, and the payment date. For audit trails, it also notes the individual price and name of items in the order.
- Notification Service: The final touchpoint for the user, sending them notifications about their order status.
Now, let’s envision the sequence of this dance. The user initiates by placing an order through the Order Service. To ensure all items are available, the service cross-checks with the Inventory Service. Once validated, the order is captured in the system. The Inventory Service then updates its records, reducing the stock by the ordered quantity. Our Payment Service jumps in next, documenting the payment details for the order and orchestrating the actual payment through third-party platforms.
Once all the steps conclude successfully, the Notification Service rolls out the red carpet, emailing the user that their order is in motion.
Imagine the Payment Service hits a snag and can’t save the payment details. By this point, the order had already been recorded, and the inventory adjusted. This mishap necessitates a reversal of our previous actions. However, blindly reverting via direct service calls is fraught with pitfalls — network glitches, service outages, or unpredictable timeouts could further exacerbate the issue. An error during this critical rollback is something we can’t afford. So, where do we turn for a solution? Let’s draw inspiration from relational databases and their transactional systems.
Relational Databases and the Magic of Transactions: A Dive into ACID
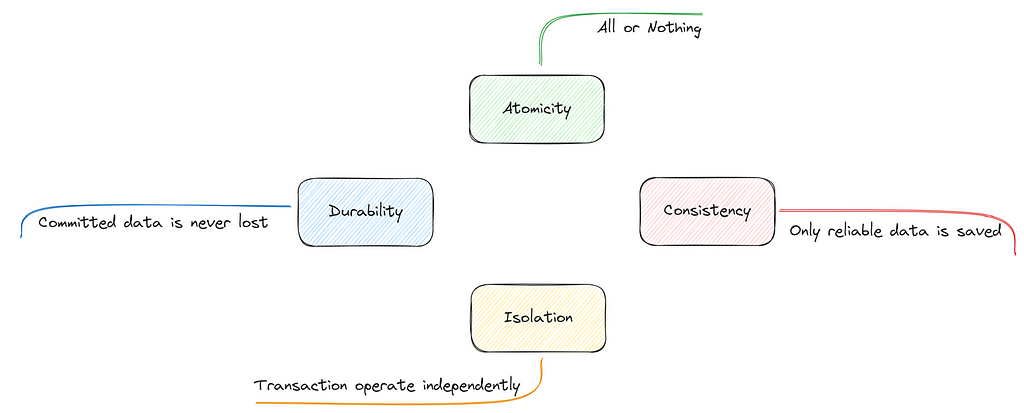
Relational databases boast a standout feature: transactions. These transactions are fortified with the ACID property, an acronym for Atomicity, Consistency, Isolation, and Durability.
Atomicity
This principle ensures that database operations are both indivisible and irreducible. Simply put, all steps within the transaction are executed, or none are. This binary approach eliminates the danger of partial database updates, which can introduce significant issues. The essence of atomicity lies in two primary mechanisms: rollback and commit.
When facing interruptions or errors, the rollback function reverts all changes, restoring the database to its prior state. On the other hand, commit solidifies all transaction operations to the database permanently once the transaction is successful.
Write-Ahead Logging (WAL)
Playing an instrumental role in ensuring both atomicity and durability, WAL logs proposed data changes even before these changes are actually made. These logs, meticulously recorded in stable storage, offer comprehensive information for either redoing or undoing the operations. In scenarios like power outages or system crashes, these logs become invaluable.
If a committed transaction’s effects weren’t saved pre-crash, the system uses the log to redo the operations. Conversely, for uncommitted transactions or those ongoing during the crash, the log aids in undoing changes, reinforcing atomicity. At its core, WAL prioritizes logging the intent to modify data before executing the change, providing a safety net against system failures and ensuring both atomicity and durability.
Consistency
At its core, within the ACID framework, consistency embodies the principle of maintaining integrity. Every transaction ensures the database transitions from one legitimate state to another, upholding the overarching equilibrium. Essentially, the ACID model of consistency vouches for adhering to our database’s set rules and constraints, acting as a shield against any potential inconsistencies.
Yet, the term “consistency” wears many hats. For instance:
- In the context of the CAP theorem, consistency is synonymous with linearizability.
- Under the umbrella of strong consistency, once a piece of data is verified as written, subsequent reads will consistently reflect this most recent data, irrespective of the read’s origin.
- Eventual consistency, conversely, promises that all data replicas will eventually concur. There might, however, be fleeting moments when discrepancies occur.
The role of the Transaction Manager in upholding ACID
The Transaction Manager plays a pivotal role in upholding the ACID properties in transactional databases. This component kickstarts a fresh transaction, lining up the requisite resources and contexts. When the transaction approaches its conclusion, the Transaction Manager determines the fate of the changes — either solidifying them permanently (commit) or retracting them (rollback).
One of the Transaction Manager’s prime responsibilities is ensuring that ongoing transactions remain isolated. This ensures that the maneuvers of a currently active transaction stay under wraps, hidden from other transactions until the green light of commitment is given.
The Transaction Manager provides tools to restore balance when the system encounters hiccups or outright failures. Utilizing logs and various recovery methodologies can either reverse actions of uncommitted transactions or push through the effects of those committed, ensuring the system’s integrity remains unscathed.
Venturing from Singular Transactions to the World of Distributed Transactions
With an understanding of how individual transactions operate, it’s tempting to transpose this knowledge onto distributed scenarios. However, as we transition from singular system domains to the expansive universe of distributed services, a direct application of these concepts doesn’t fit perfectly, necessitating certain modifications.
Enter the two-phase commit
The two-phase commit (2PC) is a prominent technique to facilitate distributed transactions. Essentially, it’s a protocol designed to ensure that distributed transactions solidify uniformly across all associated parties (also known as cohorts or participants) or are collectively abandoned. It harmonizes distributed actions across diverse databases, applications, and systems.
Mirroring the functions of a transaction manager, the 2PC protocol leans on a specific component, termed the coordinator, to uphold atomicity amongst transaction participants.
Here’s a marriage analogy for 2PC:
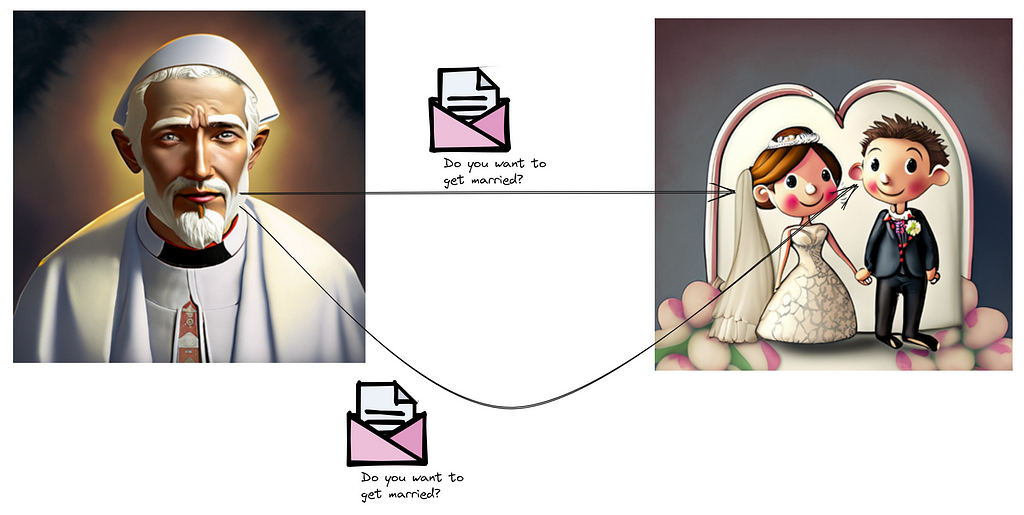
Visualize a wedding ceremony. As the climax approaches, the officiator (acting as the coordinator) questions the first individual (participant 1), “Do you wish to wed?” He might simultaneously pose the same query to the other individual (participant 2), marking the commencement of the ‘prepare phase.’
Here, the coordinator’s goal is to gauge the commitment readiness of each participant without them making a final commitment. If one party declines, the coordinator ensures the process is reversed.
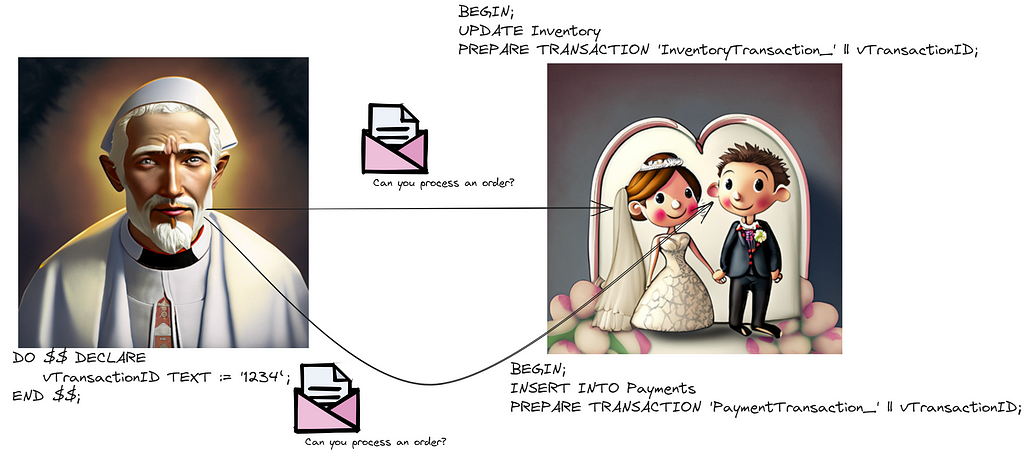
Drawing parallels to our e-commerce example, the coordinator spawns a unique transaction ID and then asks each service (the transaction’s participants) about their commitment potential. In a PostgreSQL environment, this can be triggered via the “prepare transaction” directive.
Next, the ‘commit phase’ ensues. Here, the officiator proclaims, “Now, you’re wedded,” contingent on both parties’ affirmation in the prior phase. Post the ‘prepare’ phase, there’s no retracting. Should any participant dissent during the initial phase, it’s the coordinator’s onus to mandate every participant to revert their modifications.
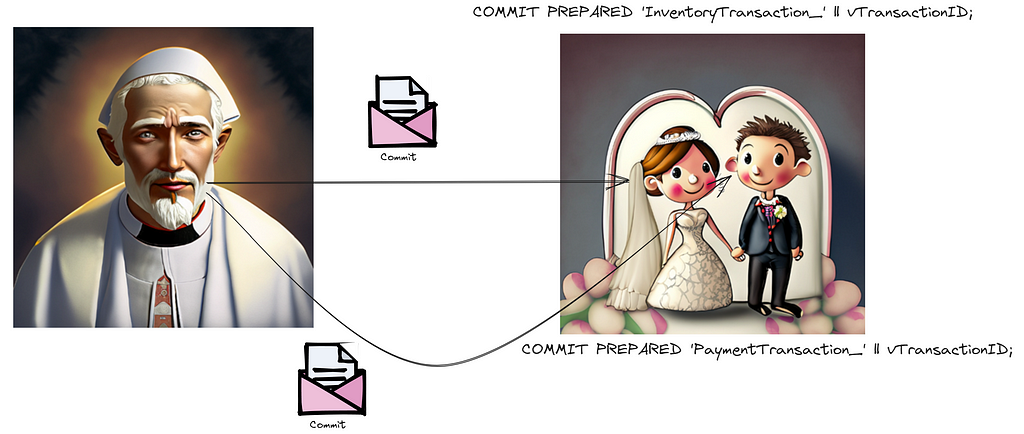
In PostgreSQL parlance, this would involve the coordinator dispatching a “commit prepared” instruction to all participants.
However, despite addressing atomicity and consistency hurdles within our microservices, the 2PC technique isn’t without its share of drawbacks:
- Performance dips: Given its synchronous nature, 2PC demands that participants retain resources (e.g., locks) until the transaction concludes, potentially spurring resource clashes and hindering performance.
- Latency concerns: Given the iterative dialogues between the coordinator and participants, latency can spike, especially in systems dispersed over vast regions.
- Potential stalling: A terminal failure of the coordinator during a transaction might leave “yes”-voting participants in limbo, torn between committing or aborting.
- Reliability issues: The coordinator could become a system’s Achilles’ heel. While there are countermeasures like backup systems, this bottleneck remains an issue.
- Implementation challenges: Architecting a flawless 2PC isn’t straightforward. Addressing every possible hiccup and anomaly can embed intricate layers in the system’s design.
Sagas: A distributed transaction alternative
Crafting distributed transactional protocols is undeniably intricate. In its mission to embed the Two-Phase Commit protocol within Spanner, their globally distributed relational database system, Google embarked on a series of technological feats.
They introduced an avant-garde time synchronization technique called TrueTime, employed atomic clocks with cesium-based timekeeping within their infrastructure, and rolled out a consensus algorithm inspired by Paxos among their replica nodes. This technological cocktail ensures uninterrupted operation and resilience, even when certain replica nodes are non-functional or unreachable.
Other models have been proposed, given the inherent challenges in crafting distributed transactions. Drawing parallels with the Write-Ahead Logging system, which archives every operation in a log for potential future reference or reversion, a similar pattern emerges in distributed systems, known as the Saga.
At its core, a Saga is a chain of isolated transactional operations, each paired with a designated counteraction. Should an operation falter due to unforeseen events, such as a database glitch or constraint breach, the Saga pattern activates the affiliated counteractions to restore system equilibrium. This design allows for prolonged transactions without global locks or centralized oversight.
Echoing the Write-Ahead Logging principle, the traditional database checkpoint analogously translates to a message queue within the Saga pattern. This queue is pivotal, bolstering robust repetition functionalities and ensuring message transmission to the right microservices. Acting as a buffer, it abstracts the communication between services, fortifying the system against potential failures.
Here’s what the Saga methodology looks like in our e-commerce context:
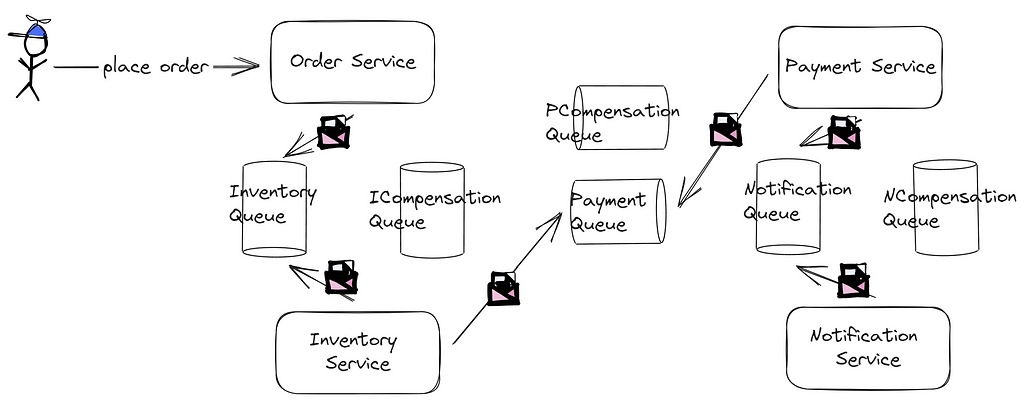
Initially, the order service inscribes an order entry in the database. Upon successful registration, it transmits a message to the inventory queue. Subsequently, the inventory service processes this message, adjusting the stock levels. Once this step culminates, a message is channeled to the payment queue, and the payment service takes the baton from there.
However, let’s imagine a hitch — the payment service falters in its database inscription.
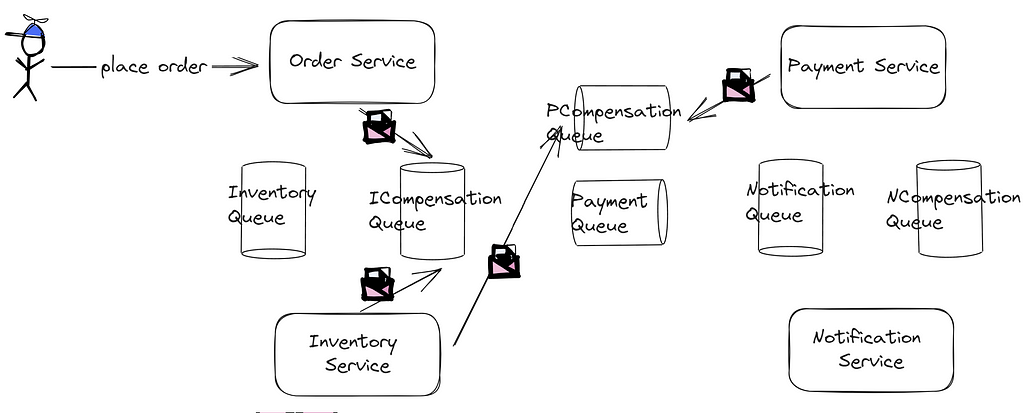
In this scenario, the payment service dispatches a message to a compensatory payment queue. Picking up from here, the inventory service processes this message, restoring the stock figures. This service then relays a message to the inventory counteraction queue, which the order service interprets and labels the order as ‘failed.’
Understanding the intricacies and approaches of implementing Saga patterns in microservices
By now, a few points might stand out to you. Firstly, the saga pattern doesn’t exactly embody a true distributed transaction. It lacks atomicity, as we process each local transaction sequentially, not simultaneously. Instead of reverting, we execute an additional compensatory transaction when something goes awry.
Additionally, implementing the saga effectively isn’t straightforward. Guaranteeing idempotency in each local transaction is essential for a couple of reasons. First, message delivery assurance isn’t foolproof. Although message brokers usually offer three delivery guarantee levels — at least once, at most once, and exactly once — it’s crucial to tread cautiously with the “exactly once” claim.
Existing proofs argue against its feasibility. Secondly, while a local transaction might process successfully, acknowledging the message broker might falter, leading to message redelivery. Hence, the significance of crafting idempotent local transactions.
Another observation revolves around microservice communication. In our prior configuration, each microservice had to be privy to the subsequent service’s queue, complicating modifications. Ideally, our microservices should function with maximum independence. Fortunately, we have methods to counteract this challenge.
One strategy involves leveraging a configuration management tool, like Zookeeper. Before a microservice dispatches a message to a queue, it queries Zookeeper for the appropriate destination.
Yet, deploying another tool solely for managing communication might be excessive. An alternative method is orchestration. Here, a centralized service (or coordinator) dictates the saga’s overarching logic, instructing other services accordingly. Services revert with confirmations or errors. For our e-commerce scenario:
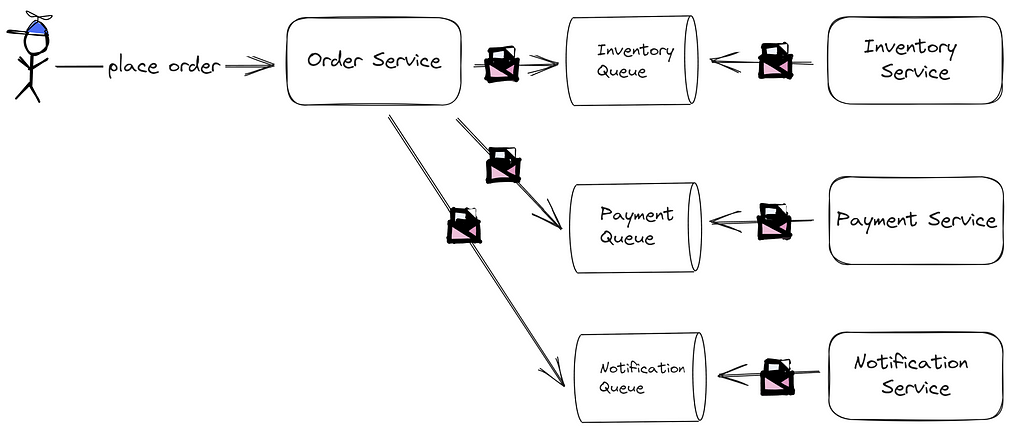
While centralized orchestration simplifies understanding and management, it risks the orchestrator becoming a bottleneck or singular failure point and might inadvertently tighten service interdependence.
Another remedy is choreography. Here, no singular entity drives the overarching logic. Services send messages to a topic — a specified channel for message exchange. Every saga-involved service subscribes to this topic, executing their respective local transactions. To put it in the context of our e-commerce case:
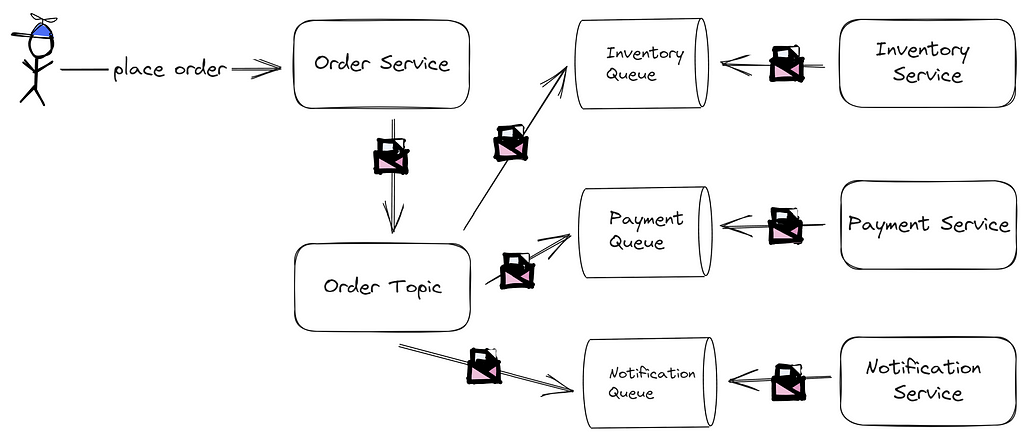
Choreography offers a decentralized, scalable approach, with each service retaining autonomy, ensuring flexibility. However, the lack of central control can make visualizing the whole process challenging, and troubleshooting might prove intricate. Hence, robust logging or tracing systems are essential.
Ensuring consistent database writes and message publishing in a microservice
You may have deduced that the saga operates smoothly once a message enters the queue. It benefits from the message broker’s retry mechanisms and can revert transactions using compensatory measures. However, the initial service, which sends a message to the queue, encounters a familiar issue. To illustrate, let’s examine the order service:
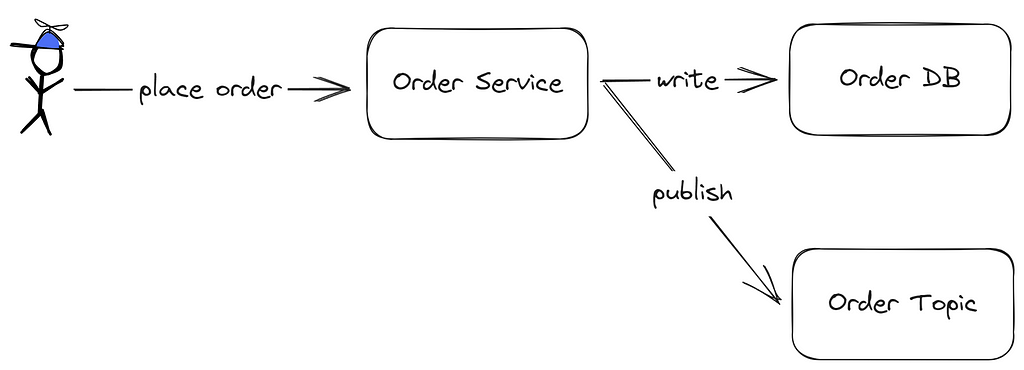
Initially, the order service attempts to record data in the order database. If this is successful, it then endeavors to dispatch a message to the order topic. If both actions are successful, the client receives a confirmation. But complications arise during failures. If the database commit fails, the client is alerted.
Things become more convoluted when the database commit succeeds, but the order topic dispatching fails. This scenario can result in a database entry lacking subsequent processing, especially if any compensating action on the database falters. Reversing the sequence of actions, i.e., publishing to the order topic before database recording, doesn’t resolve the issue. A dependable method is essential to ensure both database recording and topic publishing occur atomically.
One viable strategy is the transactional outbox pattern. If there’s difficulty in committing to the database and concurrently executing additional microservice operations, why not also record the publishing action in the database? This concept is foundational to the pattern.
When a service aims to dispatch an event or message, instead of directly forwarding it to a message broker, it archives the message in an “outbox” table within its database. Another distinct process, commonly termed a “poller” or “publisher,” periodically scans this outbox table, transferring messages to the message broker. After successful message dispatch, the relevant entry in the outbox table is deleted or flagged as dispatched.
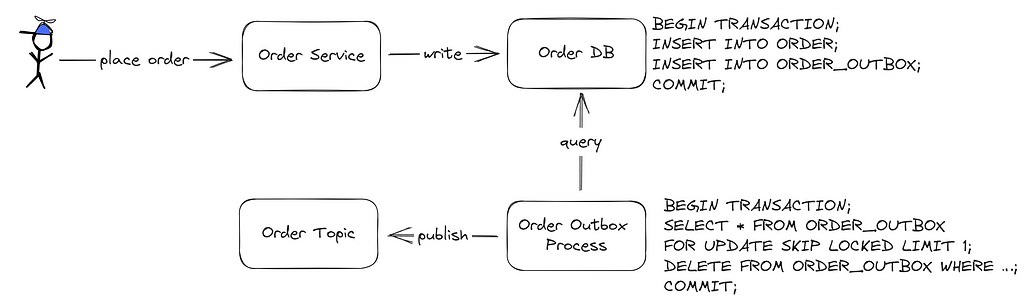
This pattern upholds atomicity by employing local transactions for both application state updates and outbox entry archiving. Should the application unexpectedly terminate post-transaction, the message remains preserved. This ensures eventual consistency in distributed setups. Even if immediate message transmission is hindered (perhaps due to network glitches), future retries by the background process ensure eventual dispatch.
However, as with most solutions, there are considerations. Owing to its asynchronous design, a lag exists between the event’s archival in the outbox and the message’s actual dispatch. This delay might be unsuitable for real-time communication requirements. The background process might strain the system, particularly if it continually scans the database.
If the poller dispatches a message but crashes before flagging it as dispatched, it might resend the same message. Hence, message recipients should either be idempotent or the system should provide deduplication capabilities. Careless implementations might lead to potential database locking challenges, especially in high-traffic conditions.
Further Work
You might want to explore additional patterns, such as the three-phase commit (3PC). This protocol expands upon the two-phase commit (2PC) and seeks to mitigate its primary shortcoming — the potential for system blocking. When a 2PC’s coordinator or participant encounters a crash, it might leave the system in limbo, resulting in participants waiting indefinitely for a resolution. By introducing an extra phase, 3PC minimizes the probability of such blockages.
It’s also beneficial to familiarize oneself with consensus algorithms such as Raft and Paxos. As the Spanner example hints, consensus algorithms like Paxos play an integral role. Raft and Paxos provide a robust mechanism to reach consensus across system nodes regarding a specific value or series of events.
This consensus ensures a cohesive view of a transaction’s results across all nodes within distributed transaction scenarios. These algorithms possess the resilience to accommodate the malfunction of a few nodes while maintaining the overall system’s consensus. This resilience confirms that a distributed transaction remains consistently committed or reverted even amidst sporadic node failures.
In the era of microservices architectures, many tools and platforms have sprouted to simplify the implementation of the Saga Pattern. Here are some noteworthy mentions:
- Temporal (formerly Cadence by Uber): An orchestration platform for microservices, Temporal is tailored for persistent, long-term processes, making it apt for sagas. It boasts fault tolerance, scalability, multi-language support, and preserving application states amidst server downtimes.
- Camunda: While fundamentally a BPMN platform for modeling and executing business processes, Camunda is not restricted to sagas but can effectively handle their modeling and execution. It comes equipped with visual tools for workflow and decision automation, is geared towards cloud-native microservices, and offers comprehensive metrics alongside monitoring functions.
- Eventuate: Geared towards sculpting applications as a microservices suite, Eventuate aids in maintaining data consistency via sagas. It’s agnostic to specific frameworks, champions event-driven microservice designs, and rolls out sagas through event sequences or the Command Query Responsibility Segregation (CQRS) approach.
Ensuring Data Consistency Across Microservices: Challenges and Solutions was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.