An open-source prototype application for using GPT functions on entire documents

Introduction
The user interface of ChatGPT is a clever and compelling innovation that has opened access to using Generative Pre-training Transformer (GPT) technology for many people. However, the interface does have limitations. For example, a friend of mine who is passionate about working on problems of Climate Change wanted to use ChatGPT to summarize the Climate Action Plan published by his local city in order to help communicate and explain the plans to a wide audience. The plan was long and detailed, and producing a summary to tell the story might be a great use case for Chat GPT. However, he found that he couldn’t just put a large document into Chat GPT. Copy and paste worked on parts of the document, but there was no way that he could find to summarize the entire document.
Chat GTP has been trained on a vast amount of material and excels at summarizing and explaining published works, but as of this writing, it can’t yet easily process and analyze individual documents of non-trivial size. Plug-in functions might become available to cover this use case. But until then, there may be a need for this. Perhaps we could build a tool that would make it easy for people to work with, analyze, understand, and summarize full documents. We built a prototype tool, and in this article, we share what we learned in doing so.
Vision
The basic GPT function to be used for this case is a ‘Completion’. At a high level, we feed text input into the GPT model, and generated text is returned. We guide the generated results by including a prompt such as ‘Summarize’, ‘Explain’, etc. Because the maximum combined size of the input and output of GTP models is limited, we usually can’t feed an entire document at once as input.
A well-known approach to address this limitation is to summarize long documents piecewise and construct a full summary recursively. The document is broken into multiple parts for individual processing, the results are combined for further processing, and the process repeats. See OpenAI’s “Summarizing books with human feedback” for background information.
We would also like to support a set of predefined prompts that have been created to be effective at working on documents, and also to allow users to experiment with custom prompts. Because the iterative process of generating a single result creates a large amount of information in the form of intermediate results, we would like to allow a user to explore the intermediate steps if desired. This can help show how the result was generated and may be useful in understanding or explaining a complex document.
Such a tool may be complex but could be quite flexible for people working with documents. For example, a user may want to try to use the GTP functions to create specific explanations of the individual sections of the document, and then use an entirely different prompt to create a summary of the previously generated explanations. Could this be useful? Would it be any better than the existing Chat GPT interface?
Experiment
In an attempt to answer these questions and to support the initial use case of summarizing and explaining a City Climate Action Plan, we built DocWorker. DocWorker is an open-source prototype application built on top of OpenAI’s ChatCompletion API. It is designed to enable users to apply ChatGPT-style functionality over a full document with the goal of making it easy to understand, explain, and extract information from a specific document.
Being an experiment, the ability to iterate and make changes quickly was important. Because of this, we chose to use Flask to build a web application, and to go with a simple HTML interface.
Main Interface
At a high level, the basic use case is simple. A user needs to be able to do three things:
- Upload a document
- Enter a prompt
- View the results
We support these three activities in a single simple web page and provide links to access additional functionality if desired. The initial view allows a user to select and load a document, and enter a prompt for the GPT:
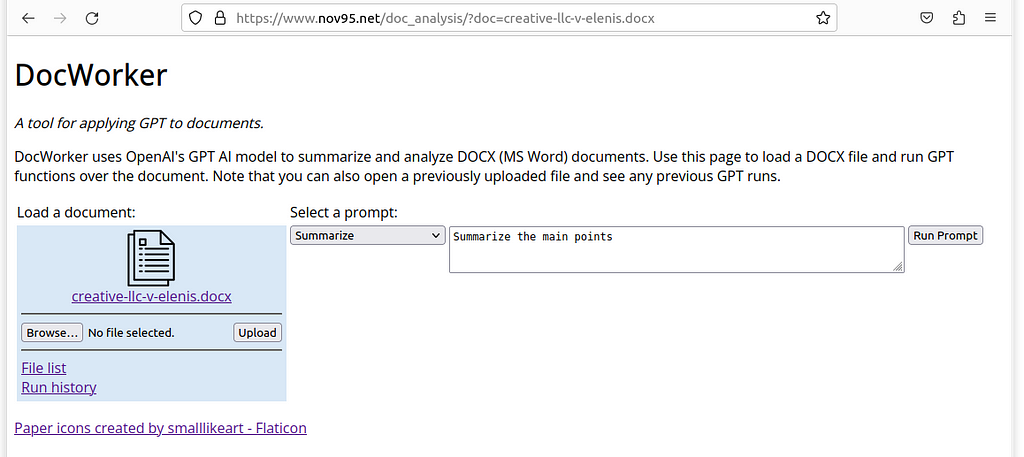
The process of running the prompt over the full document can take some time. During the run, the user is kept up to date on the activity and progress:
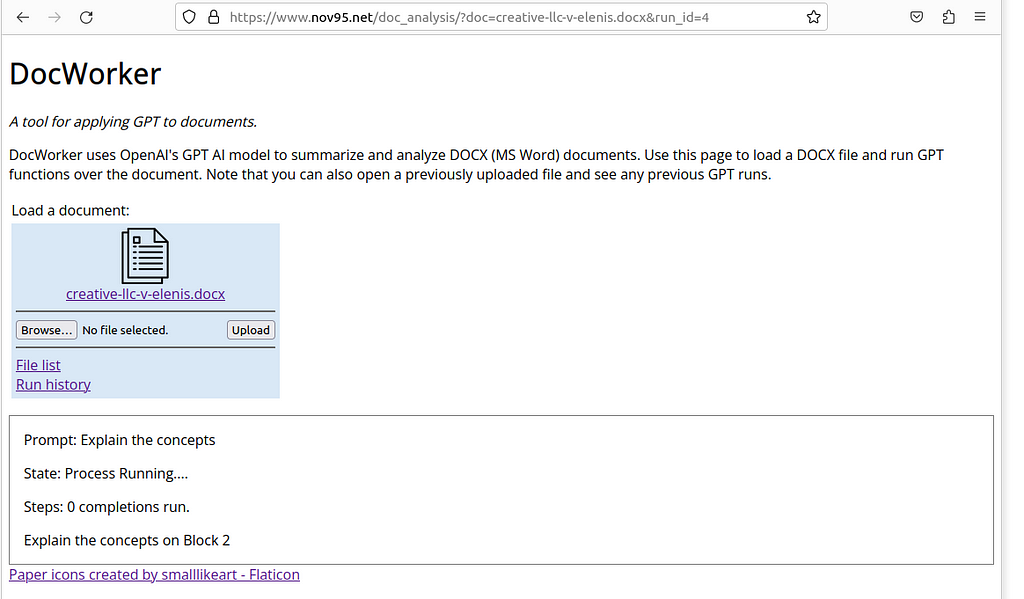
And, when the process is complete, the final generated results are displayed:

This covers the basic use case. But it is interesting to understand what is going on behind this to deliver the results.
Document Processing
When a user enters a prompt and starts the generation process, a background thread is created to run the GTP completions to produce a final result. As mentioned previously, unless a document is relatively short (about 1500 words for the GTP model we have selected), it will be broken up into appropriately sized chunks for individual processing.
We use the OpenAI gpt-3.5-turbo model for its combination of power, speed, and low cost. For this model, the total combined size of the input and output of a GTP completion can not exceed 4096 ‘tokens’. (A ‘token’ averages out to about ¾ of a word. Thus a 3000-word document is about 4000 tokens). When running a GTP completion, if the input plus output size exceeds the limit, the generation will stop, typically leaving a sentence incomplete. We chose to limit the input size to 2000 in order to leave plenty of room for output, though this could probably be increased.
Algorithm: As previously described, our strategy to produce a single final result is to run GPT completions on the individual chunks of the original document and then combine the results from the completions up to the maximum size. We then run GTP compilations on the combined results and further combine those results. This continues until a single result is produced:
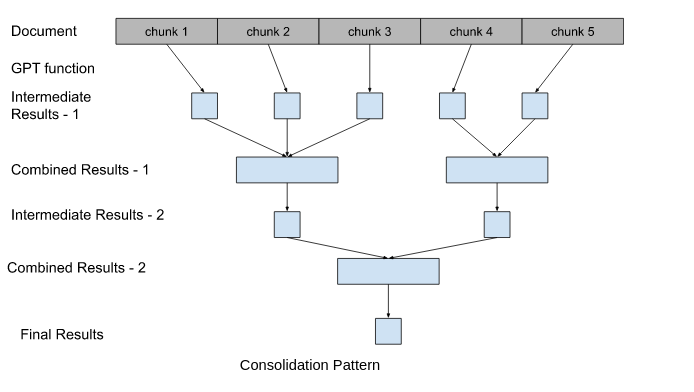
In order to reach the end state of one result, this process assumes that the resulting output of the GPT function will be small enough to combine with other results. We need each round of processing to be smaller than the one before. While this may happen, depending on the specific prompt entered by the user it is not guaranteed and the process could run forever. This would both not produce a final result, and run up quite a costly bill from OpenAI for the GTP Completion calls. We guard against this case by limiting the size of the generated intermediate results to ensure each stage of processing reduces the number of items to be processed.
Truncated Results: GPT Completions are non-deterministic, and we typically expect slightly different results each time it is run. The total size of the input plus the output can exceed the maximum capacity of the GPT model. When this happens, the generated result typically cuts off in mid-sentence and is incomplete. This can have an undesirable effect on the next round of processing. We see that the GPT model may try to continue where the text cuts off, instead of following the supplied prompt. We handle this case by checking the ‘finish_reason’ returned from the OpenAI API call. If the finish reason is due to length, then we consider the result as truncated. We attempt to fix up the truncation by cutting off the text at the last newline in the response.
Failures: It is not uncommon for the remote API call to the OpenAI service to fail with a temporary or transient error. The service may be briefly overloaded, or perhaps front-end networking configuration changes create a transient reachability issue. In any case, the solution is to retry the calls after a failure with exponential backoff for waiting between retries. We use 5 attempts waiting 5, 10, 20, and 40 seconds between the retries.
Prompts
Building effective prompts is a key aspect of using GPT Completions to produce the desired results. We start with a set of examples that should be useful in explaining and summarizing a document:
- Summarize the main points
- Explain the concepts
- List the people that are mentioned
- Explain like a pirate
Originally we simply added the prompt as a prefix to the portion of text to run a GPT Completion. This didn’t work well, producing inconsistent results. Deriving effective prompts requires experimentation. We followed the OpenAI GPT Best Practices of using delimiters to clearly indicate distinct parts of the input, and adopted the following templates for presenting the prompt for the GPT:
You will be provided with text delimited by triple quotes.
Using all of the text, <PROMPT>
“””<DOCUMENT TEXT>”””
Without these instructions, we found that the GTP would ignore parts of the text and frequently make incorrect additions to the results with information that did not appear in the original text. For example, when processing our Climate Plan document, the GPT would include elements of the Climate Plan published by the City of Santa Monica in the generated summary of our Climate Plan document. (We assume a City of Santa Monica Climate Plan was included in the training data for the GPT, and has some similarities to the document we are working with.) By delineating the text, and providing instructions to use that text, the results align more closely with the original document.
Detailed Information
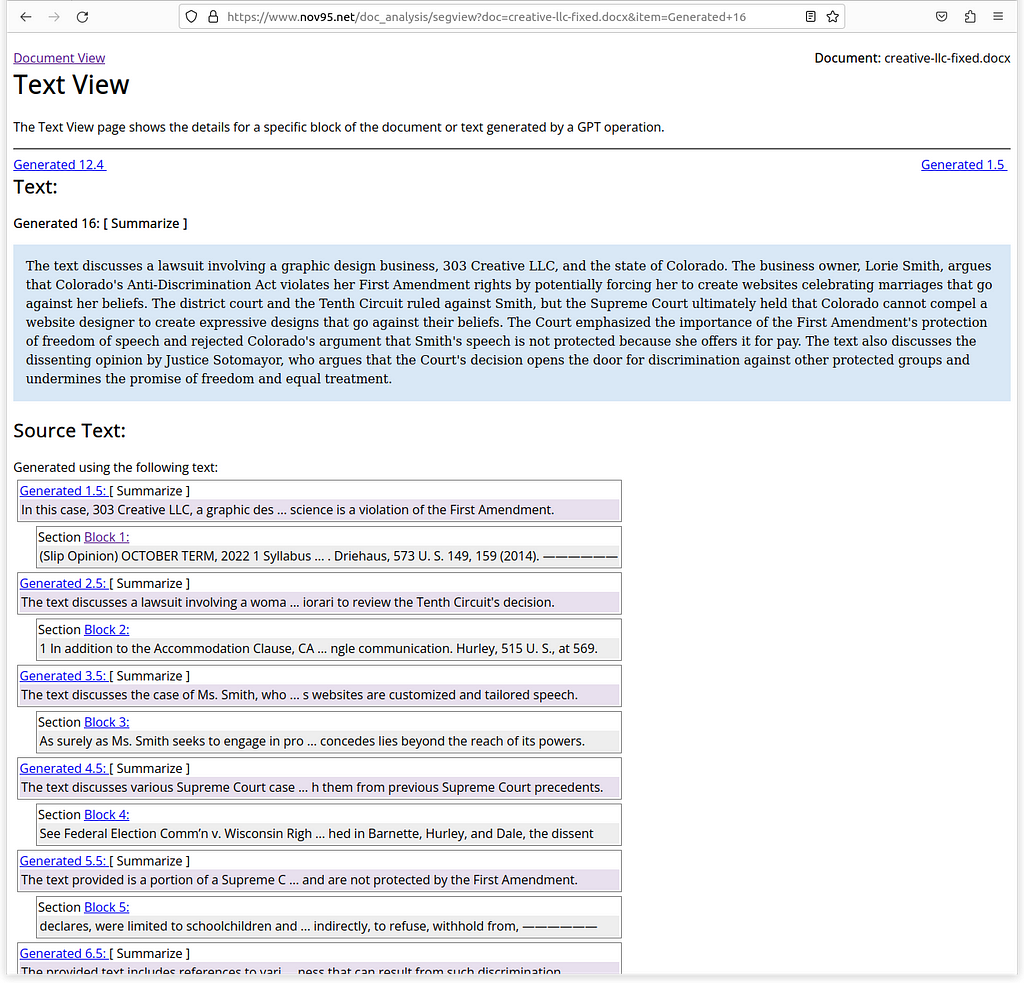
A large amount of content is generated, combined, and regenerated to produce the final result. A user may want to see the individual steps that were followed to produce the final result. This can be helpful in assessing the quality of the final result, better understanding the original document, or perhaps in creating a better final summary.
The final result is generated from a set of source text, which may in turn have been generated based on other source text, which may also have been generated from previous source text. In a detailed view, we show the full set of results and source text used to generate results in a hierarchy:
Splitting Up the Document
Dividing up, or “chunking”, documents into appropriately sized sections is the typical approach when creating input for AI models. Because we wanted to capture the key points and concepts from each chunk, we decided to attempt to split documents along the lines of logical sections as much as possible. We parse DOCX files (Microsoft Word) and use text marked with a headings style in the document (e.g. Heading 1, Heading 2, …) to identify sections. We then use a heuristic of “don’t split sections” when dividing the document into chunks. This approach resulted in a larger number of smaller chunks as compared to other options, but we hope these divisions result in better and more accurate results. It isn’t clear at this point if it makes any difference in the quality of the results.
Unrolling Tables
In our original target document, the City Climate Action Plan, a great deal of the important information was presented in the form of tables. This made it both difficult to extract manually and unclear how to send this information to the GPT.
Presenting information in tables cat make it easier for humans to understand the full context, but may make it harder to process the information with a GPT. For example, our target document included a table with bullet lists of deliverables and activities by priority for the years 2023, 2024, and 2025.
The column headings were individual years and the row headings were the priority. Our solution for this was to ‘unroll’ the table by presenting each row in the following format:
<Row Heading>
<Column 1 Heading>: <Cell Contents>
<Column 2 Heading>: <Cell Contents>
For example, a row with 4 columns may be reformatted as follows:
Priority: P1
2023: Pilot commercial HVAC electrification.
2024: Single-family home HVAC electrification
2025: Design and launch additional programs
Evaluation
We found that DocWorker leverages and delivers the basic capabilities of the ChatGPT model on documents, without the pain of cutting and pasting parts of the document and the results.
The strategy of unrolling tables into paragraphs allowed the GPT model to access the information from our target Climate Action Plan document. Our use of prompt formatting and predefined prompts worked effectively to produce reasonable results.
To evaluate the performance of full document processing with DocWorker, we used the recent US Supreme Court Opinion, 303 Creative LLC v Elenis. When uploaded, the document was broken into 12 sections of about 2000 tokens each, and the resulting size is about 22000 tokens.
Summarize
A prompt to summarize the document produced a 143-word, 5-sentence summary that covered the high-level points in the case, the appropriate background, and the dissenting opinion. We judge it to be accurate and of good quality. It took about 40 seconds to generate and included 13 intermediate steps.
Summarize Main Points
A prompt to summarize the main points of the Court Opinion generated a larger response consisting of 22 points covering the stipulated facts, the majority opinion, and the dissent. The process generated 6200 tokens at a total cost of about 33000 tokens, or about 6 cents, and took about 90 seconds. While we didn’t do a rigorous assessment, a reading of the opinion and then the generated summary appears to show that the summary delivered both a reasonably accurate and effective coverage of key points. While not every point in the summary is set in a clear context, each generated point is significant and is reflected in the Opinion.
Explain the Concepts
We also used a prompt, “Explain the concepts”, to process the Opinion. This generated a high-level 7-point list from the Opinion covering the First Amendment, Compelled speech, Public accommodation laws, constitutional limits on public accommodation laws, unique speech, stipulations and alternative theories, and Supreme Court precedents.
List People
Another prompt used was to list the people that appear in the document. It was able to extract 73 items with a few duplicates and a few items that didn’t refer to people (e. Solomon Amendment). It appeared to catch everyone mentioned in the text of the opinion.
Explain Like a Pirate
Finally, we used a prompt, Explain like a pirate. Summaries and explanations in pirate lingo can be fun and entertaining to read, making it easier to absorb what otherwise might be a dry message. In this case, the system generated an accurate overview mostly focused on the majority opinion. We note that the generated content was very supportive of the majority opinion focusing on the free speech aspects, and didn’t look at the issues of discrimination. It would be fair to say that this explanation was one-sided and perhaps biased.
Cost
The cost and resources required to process each portion of the document, plus the following runs to combine the intermediate results isn’t insignificant. The overall cost for running the 5 full document processes on the Supreme Court Opinion was $0.28. While not expensive, this cost could certainly add up with many prompts run for long documents.
Speed
In the current implementation, each GPT operation is run sequentially, and it may take from 30 to 90 seconds to produce a final result. Operations can be run in parallel in the consolidated process, likely reducing the time to process the Supreme Court Opinion by a factor of 6 to 8.
Overall
We judge most of the generated results to be accurate and comprehensive. We note that this GPT model didn’t add any significant insights or useful conclusions. For example, in this case, it is notable that the majority opinion didn’t draw a line for future cases for freedom of speech vs anti-discrimination, but this AI model didn’t catch this. In at least one case, the generated output was heavily biased to one side, perhaps to help make the summary a compelling story. You can try this out yourself to make your own assessment.
Conclusions
Automated GPT operations over full documents appear to generate useful information that helps in understanding, analyzing, and summarizing complex documents at a reasonable cost. There does exist a risk of inaccuracies or an incomplete/biased perspective being introduced by the GPT operation, and it is clear that a knowledgeable human should review any generated material prior to being published.
Providing a web-based user interface turned out to be considerably more work than building a simple Command Line Interface, but has enabled more users to try out and experiment with the prototype, helping us learn more.
A promising application of DocWorker functionality that may help citizens be more engaged with their local democracy, could be to summarize and publish information based on City Council and City Commission meeting minutes. Local newspapers have limited resources for reporting and a labor-saving inexpensive service may enable a larger quantity of high-quality information about the activities of local government to be accessible to more people. Such a service would support, but not replace, a human reporter publishing such material.
Future Work
During the course of the project, we discovered possible future directions in applying GTP technology to documents.
PDF Support
A great deal of information is published as PDF files. Extracting high-quality information from PDFs can be a challenge because pages in PDF files are more like pictures than text documents. However, there are good libraries for extracting text, and GPT functions might be helpful in cleaning up the extracted data.
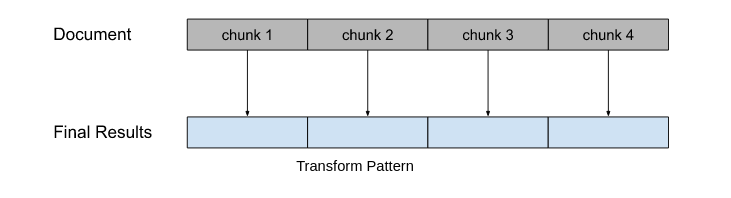
Transform Document
Instead of summarizing and consolidating a document, a user may want to transform or rewrite a document to improve, fix, or translate the text. We intend to implement a “transform” pattern for document processing.
Iterative Changes
Once a user generates a result for a document (a summary, explanation, etc), that user may want to request modifications. Perhaps they want results that are more detailed, shorter, longer, perhaps to include content about a specific subject, etc. An interesting feature would be to allow the user to ask for changes. We could use GPT to update the prompt based on the user request, and perhaps reuse some of the intermediate steps to produce results more quickly at less cost.
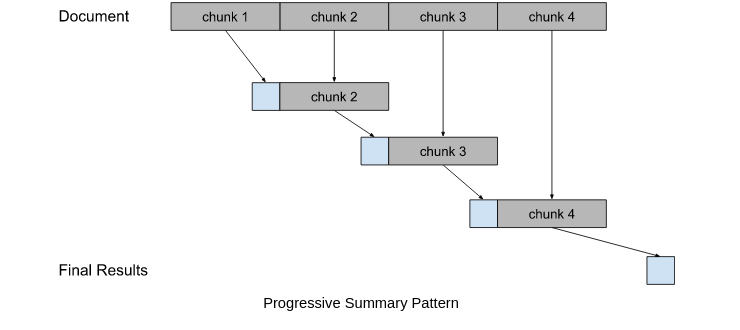
Progressive Summary
Sometimes a summary needs to be created in the context of previous information. An alternate strategy for multi-part processing is to process the first section, combine the results with the contents of the next section, and then process the combination. This continues for all sections of the document. This carries the initial context of the document through the entire process. We call this pattern “Progressive Summary” and intend to implement this process and compare the approaches for various use cases.
Thank you for reading! The code is available as open source, and you can try this yourself.
DocWorker: GPT Applied to Documents was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.