
With increasingly stronger hardware, relational databases nowadays are usually stupid fast, even when drudging through millions of records, which might make one think that knowing the fine art of SQL Tuning is no longer needed. However, if you are building any non-trivial application with large data sets, you will encounter performance problems. It might be your biggest customer, your back office, or a batch process — as the business gets tangled up and more complicated, so will your SQL.
So if you’re like me, and have better things to do than stare at a loading screen or just simply don’t want to query your data to feel like an entire rescue mission, then maybe this article is for you.
At the end of this series, you will be equipped with a Swiss army knife of skills to optimize and troubleshoot problematic queries, navigate around common performance pitfalls, and prevent problems before they even occur. You will also learn how the query optimizer works, how to use the EXPLAIN feature, and why indexes can improve performance drastically (and in which cases they can’t).

Introduction
Our journey to SQL wizardry begins with understanding the query optimizer and how data is fetched from relational DBs. I will use PostgreSQL terminology here for the sake of conciseness, but keep in mind that most other databases have some equivalent. I will not go into deep details on database engines since there are entire books on the subject, and it will bore you to death. Instead, I will concentrate on the most important things you need to know as a developer that will be enough to cover 95% of cases in real-world applications.
Developing intuition when it comes to how SQL queries fetch data is, in my opinion, one of the most critical and overlooked parts of optimizing for performance since, too many times, folks immediately run to the EXPLAIN command and then glare at the query plan, hoping to find the answers there. But while that may confirm that the query is poorly optimized (which you already knew), it won’t give you much direction on where to go from there.
Our strength as developers is that we know the data — how our customers and our application use it, the size of the data, and how it will grow as time goes by when we can cut corners and when we cannot — this analysis is the starting point of every optimization process.
Fetching Data
So how does data get fetched from the database?
Well, it generally involves two types of operations: Logical IO and Physical IO.
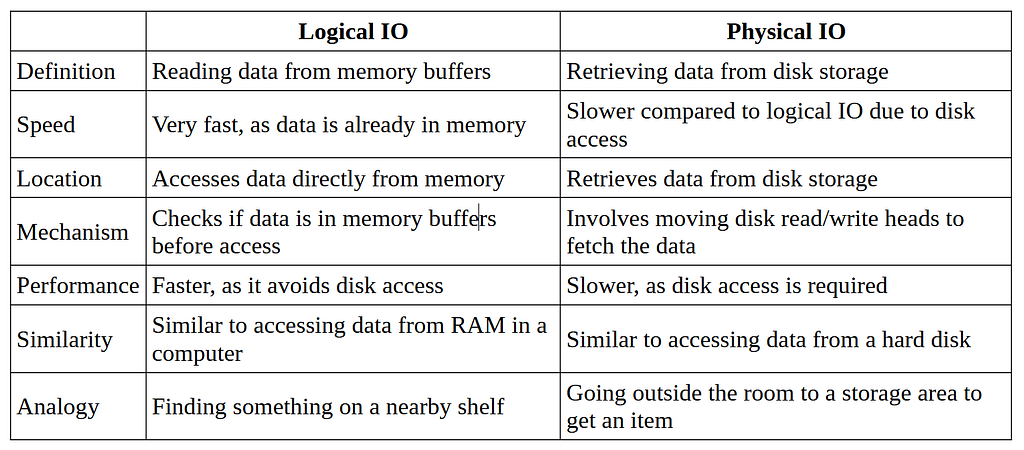
You can think of it as RAM vs HDD, so naturally, the former will be much faster (hundreds of times!) than the latter.
I know you are already thinking — how do we reduce physical IOs so we can rely on the much faster logical IOs? Couple of ways to do this:
- Implement indexes on key columns used in WHERE clauses, ORDER BY clauses, and JOIN conditions to speed up data retrieval
- Analyze query execution plans and identify opportunities for optimization. Rewrite complex queries, eliminate redundant calculations, and use appropriate join algorithms to minimize disk access
- Consider denormalizing your database schema by combining related tables into a single table. This can reduce the need for joins and decrease the amount of physical IO required for data retrieval
From my experience, the first one is by far the most important to consider during development and tuning and is the starting point before applying the other more advanced techniques.
In general, you will never have to worry about the ratio or quantity of Physical/Logical IOs in your queries since this can vary significantly depending on different factors:
- How hot is the data you are accessing? Meaning, how likely is it that the pages you want to fetch were already inside a memory buffer rather than disk?
- Is this the first, second, or twenty-second time you are running the query? This one is particularly annoying when measuring performance since a subsequent run will often complete faster due to the fact that the necessary pages/blocks may have already been loaded into memory resulting in Logical rather than Physical IO
My advice — keep it simple and use common sense.
Are you fetching more data than you actually need?
Scan Types
OK, OK, talk is cheap — show me the code.
We’ll create a sample table called customers and fill it with random data to highlight the different scan types employed by RDBMS when executing queries — think of them as strategies for loading and filtering the data we want.
-- Create the customers table
CREATE TABLE customers (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
status VARCHAR(20),
type VARCHAR(20),
country_of_registration VARCHAR(50),
registration_time TIMESTAMP
);
-- Generate random customer data - 1000000 (one million) rows
INSERT INTO customers (name, email, status, type, country_of_registration, registration_time)
SELECT
md5(random()::text) AS name,
substr(md5(random()::text), 1, 10) || '@example.com' AS email,
CASE floor(random() * 3)
WHEN 0 THEN 'Active'
WHEN 1 THEN 'Inactive'
ELSE 'Pending'
END AS status,
CASE floor(random() * 3)
WHEN 0 THEN 'Standard'
WHEN 1 THEN 'Premium'
ELSE 'Trial'
END AS type,
CASE floor(random() * 5)
WHEN 0 THEN 'USA'
WHEN 1 THEN 'Canada'
WHEN 2 THEN 'UK'
WHEN 3 THEN 'Australia'
ELSE 'Germany'
END AS country_of_registration,
NOW() - (random() * interval '365 days') AS registration_time
FROM generate_series(1, 1000000);
- Please note that the above script is specific to Postgres, and some vendors likely have alternative names for the functions used therein
Full Table Scan (Seq Scan)
As you can see, we created our sample table without any indexes apart from the default one generated for the primary key (id).
Let’s try a very common use case, fetching a single customer by their email:
explain select * from customers where email = '1a67b14329@example.com';
Seq Scan on customers (cost=0.00..27448.00 rows=1 width=89)
Filter: ((email)::text = '1a67b14329@example.com'::text)
As you can see, we have used the explain keyword in front of our select query, which gives us the query execution plan that the Optimizer would choose for running it. Remember that most IDEs (I am using DBeaver) will provide you with better tools for visualizing query plans. For simplicity, in these articles, I will use the default output.
Main features:
- reads all the rows in a table
- inefficient for large tables, as it requires reading and processing every row, regardless of the filtering conditions
- used when no applicable index is available or when retrieving a large portion of the table’s data
Based on these characteristics, we can see why this query took almost 70ms to find the customer we are looking for — it had to load all the rows (from disk using Physical IO) and then check every row for the filtering condition (email = ‘1a67b14329@example.com’)
So, how do we optimize this?
Index Scan
We’ll go over indexes and how they work in-depth in a later chapter, but for now, I assume you understand that an index is a separate data structure (usually B-Tree) that refers to the original table and allows for fast and efficient lookups.
Since our select uses the email column for filtering the result, let’s index it:
create index customers_email_idx on customers (email);
Now, let’s run explain again:
explain select * from customers where email = '1a67b14329@example.com';
Index Scan using customers_email_idx on customers (cost=0.42..8.44 rows=1 width=89)
Index Cond: ((email)::text = '1a67b14329@example.com'::text)
You can see that the operation changed to “Index scan” because the query optimizer now knows that there is a more efficient way to look for the data than a full table scan.
The query now takes << 1 ms because we are traversing the index tree to look for the correct row id and are only accessing the actual table for retrieving the one row using the row id, which is returned by the index scan.
Key takeaways here:
- Indexes are particularly effective on columns that are present in the WHERE clause of a SELECT query
- Indexes are best suited for highly selective columns (this means there are fewer rows with the same value). In our example, email is very selective since it is, for all intents and purposes, unique, whereas the country_of_registration column is not very selective since, on average, there are about 200,000 records for each distinct country (20% of all rows)
- The index scan involves reading data from an index structure rather than the actual table. It is used when the query can utilize an index to satisfy the filtering or sorting requirements efficiently
- During an index scan, the database engine traverses the index tree to locate the relevant data pages, after which only the necessary pages are loaded from disk
✔️ Bonus tip:
Index your foreign keys! Some organizations even have rules to enforce this, and the reasoning is that it is very likely at some point that you will be using those columns as JOIN predicates or in a WHERE clause. Aside from that, DELETE queries in the referenced table will be faster
Index-Only Scan
The power of this scan type is often overlooked, but it can bring significant performance improvements because it not only eliminates the need to access the table to evaluate the conditions specified in the WHERE clause, but it also completely avoids accessing the table altogether if the necessary columns are present in the index itself.
Let’s imagine we want to find the count of all Premium customers from Germany for the last 30 days. We can use the following code to do this task:
explain
select count(*)
from customers
where country_of_registration = 'Germany'
and type = 'Premium'
and registration_time > now() - interval '30 day';
Aggregate (cost=37461.60..37461.61 rows=1 width=8)
-> Seq Scan on customers (cost=0.00..37448.00 rows=5441 width=0)
Filter: (((country_of_registration)::text = 'Germany'::text) AND ((type)::text = 'Premium'::text) AND (registration_time > (now() - '30 days'::interval)))
We see the dreaded Seq Scan, which is what we expected since none of the columns we filter by have any indexes.
Now, we could try to index either of these columns, and this certainly will bring some improvements for our situation, but we can also leverage what is called a covering index:
create index customers_cntry_type_reg_time_idx on customers
(country_of_registration, type, registration_time);
A covering index does what it sounds like — it includes all the columns required for a specific query. While the normal Index scan has an implicit TABLE ACCESS BY INDEX ROWID operation, which loads the actual row(s) from the table (disk), the Index only scan doesn’t need to because all the necessary data is already in the index data structure.
Let’s see the plan now:
explain
select count(*)
from customers
where country_of_registration = 'Germany'
and type = 'Premium'
and registration_time > now() - interval '30 day';
Aggregate (cost=252.41..252.41 rows=1 width=8)
-> Index Only Scan using customers_cntry_type_reg_time_idx on customers (cost=0.43..238.81 rows=5439 width=0)
Index Cond: ((country_of_registration = 'Germany'::text) AND (type = 'Premium'::text) AND (registration_time > (now() - '30 days'::interval)))
The Optimizer now employs an Index-Only Scan, filtering the result in place. Using this index reduced the execution time of this query on my computer from 250ms to 6ms. Not too shabby.
Here’s a summary:
- Index-only scans are especially beneficial when dealing with large tables, as they avoid accessing the table’s data blocks
- Utilizing covering indexes can be advantageous in scenarios where frequent queries are executed against specific columns, allowing for faster data retrieval without accessing the table
- To create a covering index based on a query, create a composite index containing the specific columns you are selecting/filtering. Inspect your query afterward using the explain feature to make sure you did it right — look for the “Index only scan” node type rather than an “Index scan”
- An index-only scan is an aggressive indexing strategy. Do not go overboard with it as, in many cases, a multi-purpose index will do the job sufficiently well without taking as much space
Bitmap Index Scan
A somewhat peculiar thing about indexes is that they don’t make queries faster unless selectivity is high. If an index has to scan and fetch many rows, it might be slower than a full table scan. This is due to one simple fact: random I/O is much more expensive than sequential I/O.
A Bitmap Index Scan combines the best of both worlds — the fast lookup of the Index Scan and the sequential I/O of the Seq Scan. Of course, nothing comes for free — to use Bitmap Scan, there are actually two parts of the equation:
- Bitmap index scan — used almost in the same way as a normal Index scan — but instead, return the page ids/offsets needed for fetching the rows
- Bitmap heap scan — reads and fetches the table blocks based on the returned page ids/offsets from the previous operation. The idea is that a single block is only used once during a scan, and blocks are read in a sequential manner
Are you tired yet? Let’s see an example:
create index customers_country_idx on customers (country_of_registration);
explain select * from customers where country_of_registration = 'Germany' and "status" = 'Active';
Bitmap Heap Scan on customers (cost=2243.16..20250.67 rows=67948 width=89)
Recheck Cond: ((country_of_registration)::text = 'Germany'::text)
Filter: ((status)::text = 'Active'::text)
-> Bitmap Index Scan on customers_country_idx (cost=0.00..2226.18 rows=203967 width=0)
Index Cond: ((country_of_registration)::text = 'Germany'::text)
If you remember, the number of rows that fulfill the country_of_registration = ‘Germany’ predicate is roughly 20% of the rows in our sample table, so even though we have an index on this column, the Optimizer chose the Bitmap Index Scan strategy, which in our case brought the execution time from ~160ms (Seq scan) to ~80ms (Bitmap index scan).
So little in terms of improvement since 20% of all rows is still a huge portion of the table that needs to be read, but an improvement nonetheless.
Key takeaways:
- The main reason a normal Index scan can result in slow queries is random I/O which is done to access each row from the table while traversing the index
- Bitmap Index Scan is chosen when the number of records selected is neither too less for an index scan nor too large for a Seq scan
- Bitmap Index Scan combines the power of the Index lookup while mostly eliminating the random I/O which is needed for Index Scan
✔️ Bonus tip:
Bitmap scans can utilize multiple indexes at once. This is very useful when you have OR / AND predicates in your query, and there are separate indexes on the respective columns but not a composite one (imagine we had separate indexes on the email and name columns and we had the predicate name = ‘John’ OR email = ‘john.smith@example.com’).
The database will allow you to benefit from the BitmapOr and BitmapAnd scan types and combine the results from both index scans, before using the Bitmap Heap Scan to actually load the data from the table.
Conclusion
We’ve covered a lot in this article, so here is what you need to remember:
- Physical I/O refers to accessing data from disk storage, which is slower compared to logical I/O that involves retrieving data from memory buffers
- Index scans effectively retrieve data based on indexed columns in the WHERE clause. Highly selective columns tend to yield better performance, while less selective ones may not provide substantial improvements
- Index-only scans are particularly valuable for large tables, as they avoid accessing data blocks. Creating covering indexes with all the necessary columns can facilitate faster data retrieval without accessing the table directly
- Bitmap index scans offer a combination of the speed of index scans and the efficiency of sequential I/O. By utilizing a bitmap index scan and bitmap heap scan, the database can retrieve the required rows with a balance between random and sequential I/O
- Sequence (full table) scans can be preferable in case a large portion of the table needs to be read, or the table itself is small (think hundreds or a couple of thousands of records, though this may depend on the row size). The benefit here is sequential I/O
References
PostgreSQL indexing: Index scan vs. Bitmap scan vs. Sequential scan
Demystifying SQL Query Execution: Scan Types, IOs, Indexing was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.