Cost-efficient data platform in Azure, harnessing Terraform, Containers, Polars, and Blob Storage

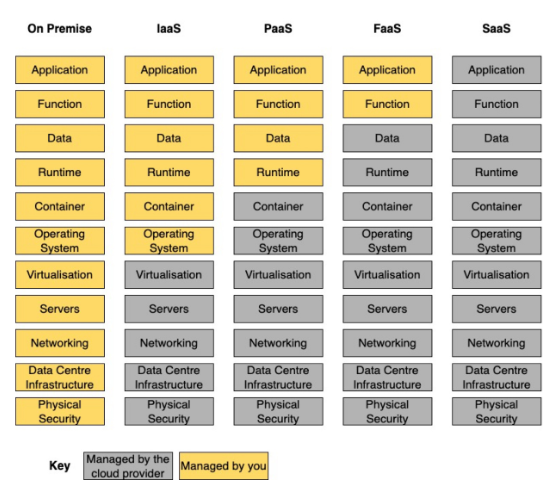
Let’s face it: data platforms in the cloud can be enormously expensive if not carefully and consciously designed. The cost tends to be pretty linear with how high up in the tech stack you decide to go.
So, what does it mean to be high up in the tech stack? For example, the managed services offered by cloud providers to make it easier to get started with your workload and use-case (e.g., AWS Glue/Lambda/Sagemaker/Athena/Lake Formation and Azure Data Factory/Functions/Data Explorer/Synapse Analytics, etc.). They all require less- to no- code to get started, and the Time To Value (TTV) is just around the corner. However, scaling these services can result in unexpectedly high invoices and not offer the flexibility enough for later customization and requirements.
“Scaling these services can result in unexpectedly high invoices and not offer the flexibility enough for later customization and requirements.”
What’s the option then? Go further down in the tech stack! Here, we can find the core components on which these managed cloud services are built (e.g., AWS EC2/Fargate/S3 and Azure Virtual Machines/Container Instances/Blob Storage).
This article will go through how to build a robust, cost-efficient, and flexible data platform in Azure that scales. It is built around Azure Container Instances for Compute, Azure Blob Storage for data storage, Terraform, and Azure Resource Groups for Infrastructure as Code deployments.
The article is split into six sections to make it a bit easier to follow along.
- Architecture
- Deployment
- Data jobs containers
- Container triggers
- Cost analysis
- Local data exploration in Jupyter Notebook
Let’s jump into it!
The full code can be found here: https://github.com/martinkarlssonio/azure-dataplatform
1) Architecture
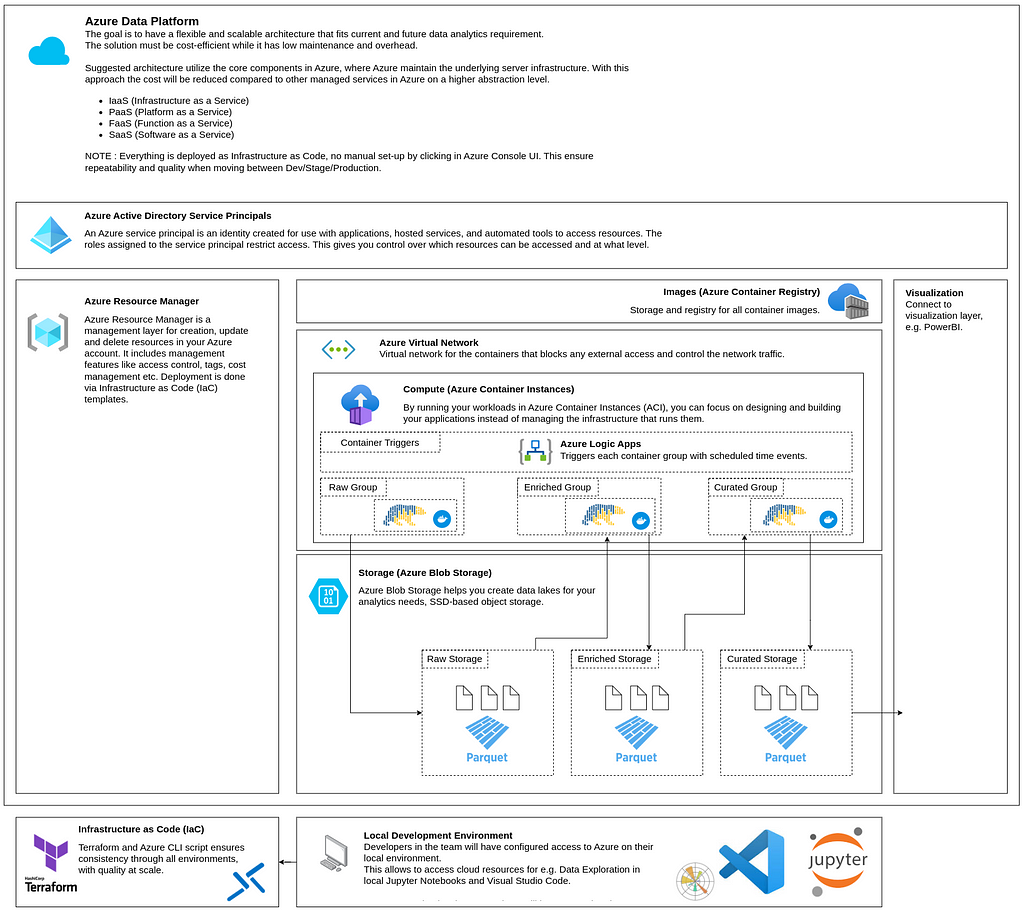
Let’s look at the components of this architecture.
Controlling the cloud resources (Azure Resource Manager)
Azure Resource Manager is a management layer for creating, updating, and deleting resources in your Azure account. It includes management features like access control, tags, cost management, etc. Deployment is done via Infrastructure as Code (IaC) templates.
Data jobs (Azure Container Instances)
By running your workloads in Azure Container Instances (ACI), you can focus on designing and building your applications instead of managing the infrastructure that runs them.
The three example containers use Azure packages to connect to Blob Storage and Polars to load the data to data frames. Polars is a high-performance data frame package written in Rust.
Network (Azure Virtual Network)
Creates a virtual network in the cloud for all the containers. The purpose of this is to control how the containers can be accessed. In this example, they are fully isolated from external access, as we have specified it to be private in Terraform deployment.
Container images (Azure Container Registry)
Storage and registry for all container images. The container images are built locally and then pushed to this private container registry.
Triggers (Azure Logic Apps)
Logic Apps allow for custom workflows. Here, we use the scheduled triggers to start each Container Group. It is impossible to trigger an individual container; therefore, we place the containers in three groups (Raw/Enriched/Curated). One container group can host up to 60 containers.
Data exploration & Data science (Jupyter Notebook)
Instead of using cloud computing during development and data exploration, this solution connects to Azure Blob Storage directly from a local Jupyter Notebook. It puts the computing on the developer’s local machine.
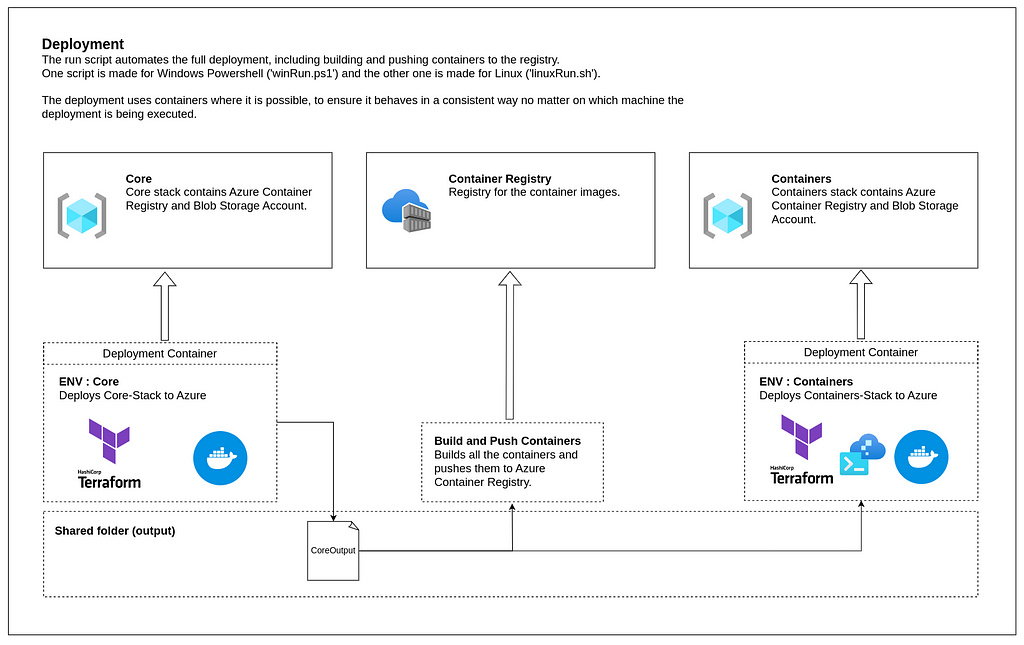
2) Deployment
The deployment is built around Terraform, an infrastructure-as-code tool (IaC). It ensures consistency when deploying through different environments, increases development speed, robust CI/CD pipelines, etc.

There are two deployment scripts, one for Windows (winRun.ps1) and one for Linux (linuxRun.sh), which follow these three steps.
- Deploy Core resources (Blob Storage Account & Container Registry)
- Build and Push container images to Container Registry (Raw, Enriched, Curated)
- Deploy Containers resources (Virtual Network, Container Instances, Logic Apps)
As of the writing of this article, Terraform does not fully support deploying Azure Logic Apps. Therefore, this is deployed in the end with Azure CLI (final.sh).
Note: The final Azure CLI script is automatically executed inside the container during Containers resources deployment.
3) Data jobs containers
If we look inside the containers deployed to the cloud (mocked-raw/enriched/curated), we find Polars, which is a high-performance data frame package written in Rust. It will ensure that the execution time is kept to a minimum and that the CPU and memory utilization are optimized.

You can read more about Polars on the official website.
https://www.pola.rs/
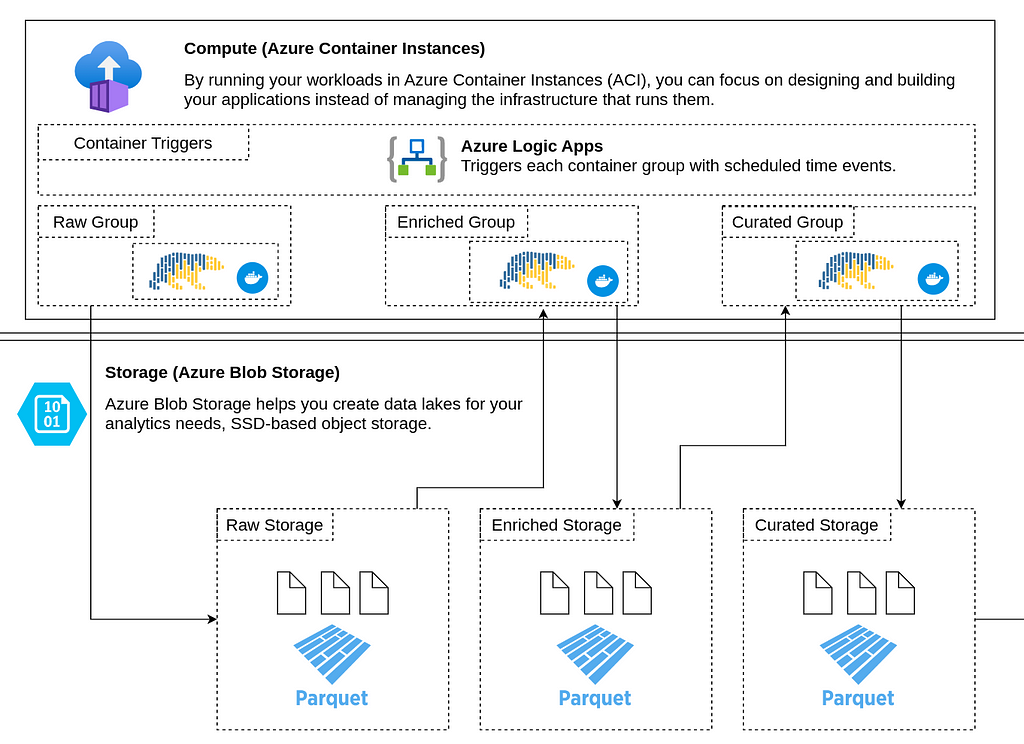
Container: Mocked Raw
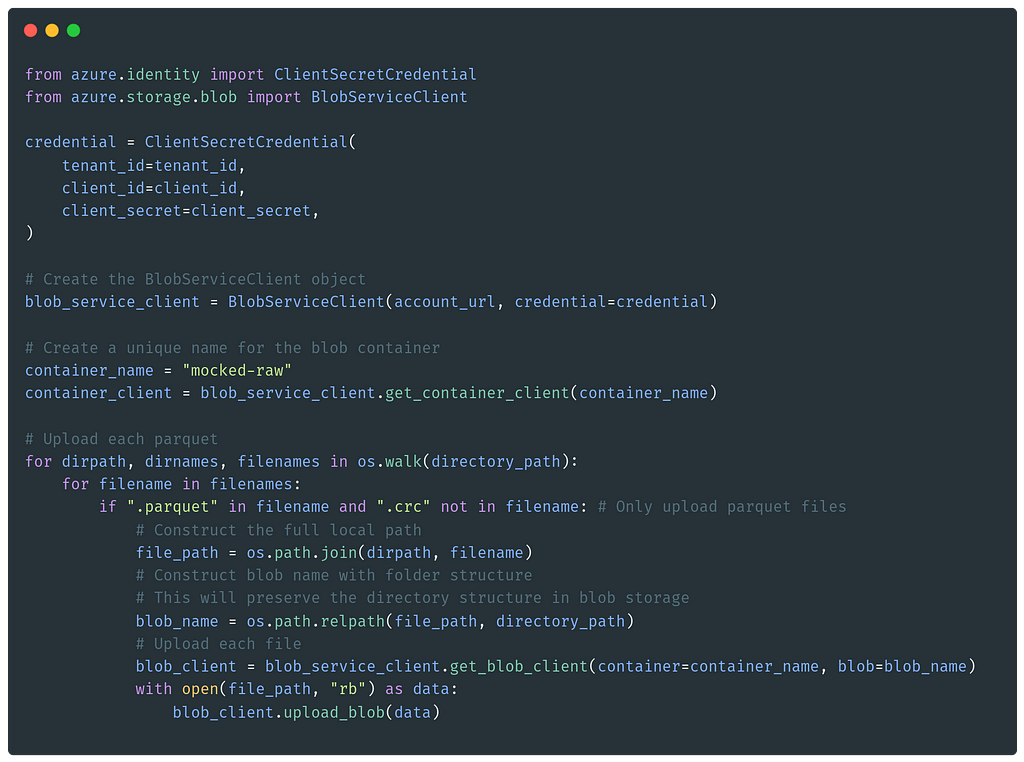
In a real scenario, the raw containers would fetch data from the sources and ensure it follows the expected data schema, then add it to the Raw Blob Storage.
In this example, the raw container creates a mocked data frame with IT ticket data, which will be used to demonstrate a real-world scenario.
The Polars data frame contains 100,000 rows and has columns such as Priority, Category, Status, and Timestamps(Open/Closed).
For partitioning purposes, it creates Open_Year/Month/Day columns. It is always a good practice to verify the data towards some data contract and ensure good partitioning already in the Raw layer. We do not want to end up with a ‘Data Swamp’.

“It is always a good practice to both verify the data towards some kind of data contract and ensure good partitioning already in the Raw layer. We do not want to end up with a ‘Data Swamp’.”
The data frame is partitioned by Year/Month/Day to Apache Parquet files and then added to Azure Blob Storage.

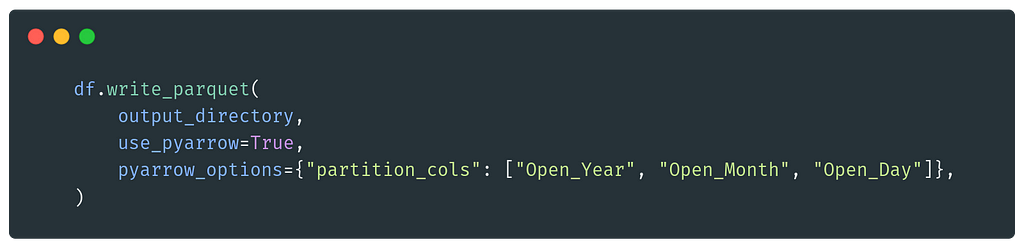
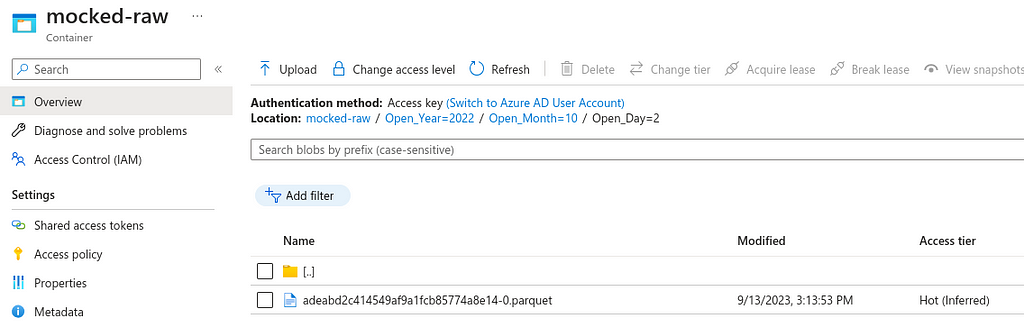
If we take a look at the Raw Blob Storage, we can see neatly structured data in the format of :
mocked-raw/Open_Year=YYYY/Open_Month=MM/Open_Day=DD
With this structure, we can load only a specific date range when accessing the data, reducing the need to load everything. This will reduce computing, network, execution time, and cost.
Container: Mocked Enriched
The container fetches the raw parquet data from Blob Storage and loads it to a Polars data frame. It then enriches the dataset with a new column that calculates the number of minutes to close each ticket, “Minutes_To_Close”.


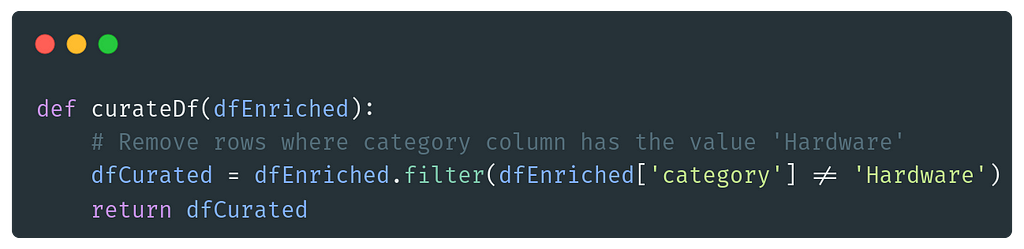
Container: Mocked Curated
In the curated container, the data is read from Enriched Blob Storage. Then it removes all the rows with the category “Hardware” because we are not interested in that data in this fictitious scenario.
4) Container triggers
Deploying the triggers was certainly not a straightforward thing. At the point when writing this article, Terraform does unfortunately not fully support deploying Azure Logic Apps; hence, there’s a CLI script in the end that deploys this.
But the key here is the files named containers/logicApp{stage}.json where the triggers and workflows are defined.
Looking at the file below, we can see a trigger that re-occurs every day at 02:01 UTC. It triggers the action start_curated_containergroup, which is pointed out under path.
If we go into the Azure portal and navigate to Logic Apps, choose logicAppCurated, and then enter Logic app designer we can see a graphical visualization of this workflow. Here, we can also see the formatting of the workflow JSON when pressing {} View Code.
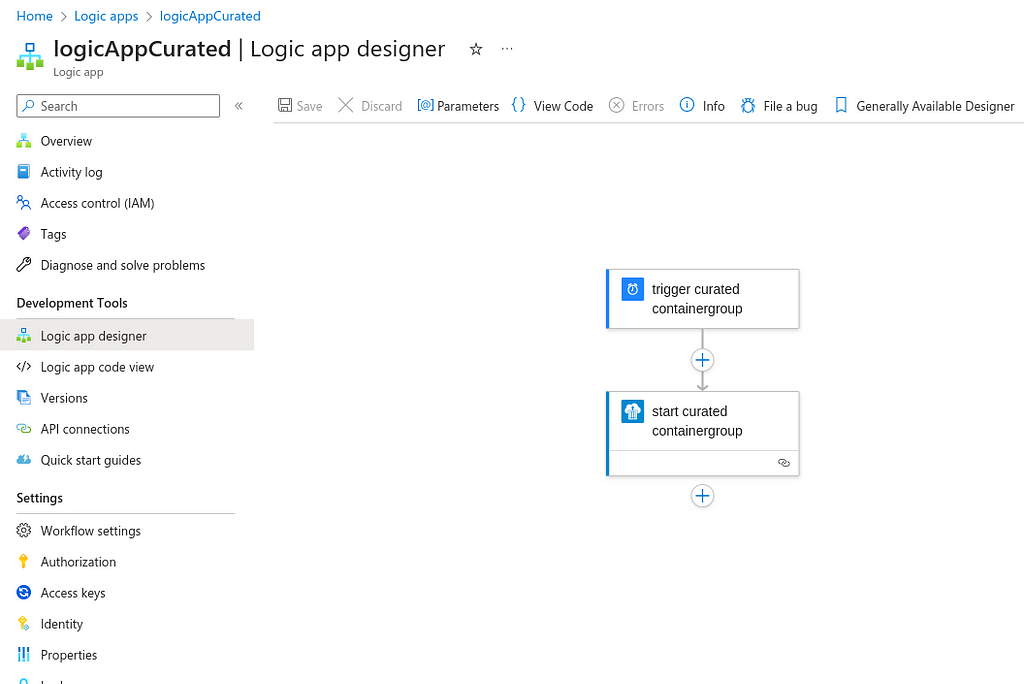
Container logs
In Azure, you can navigate into Container Instances and select your Container Group and a specific container. Apart from seeing some numbers, events, and properties, there’s a tab to access the runtime logs. This can be very useful — and it is important to know how to access it!
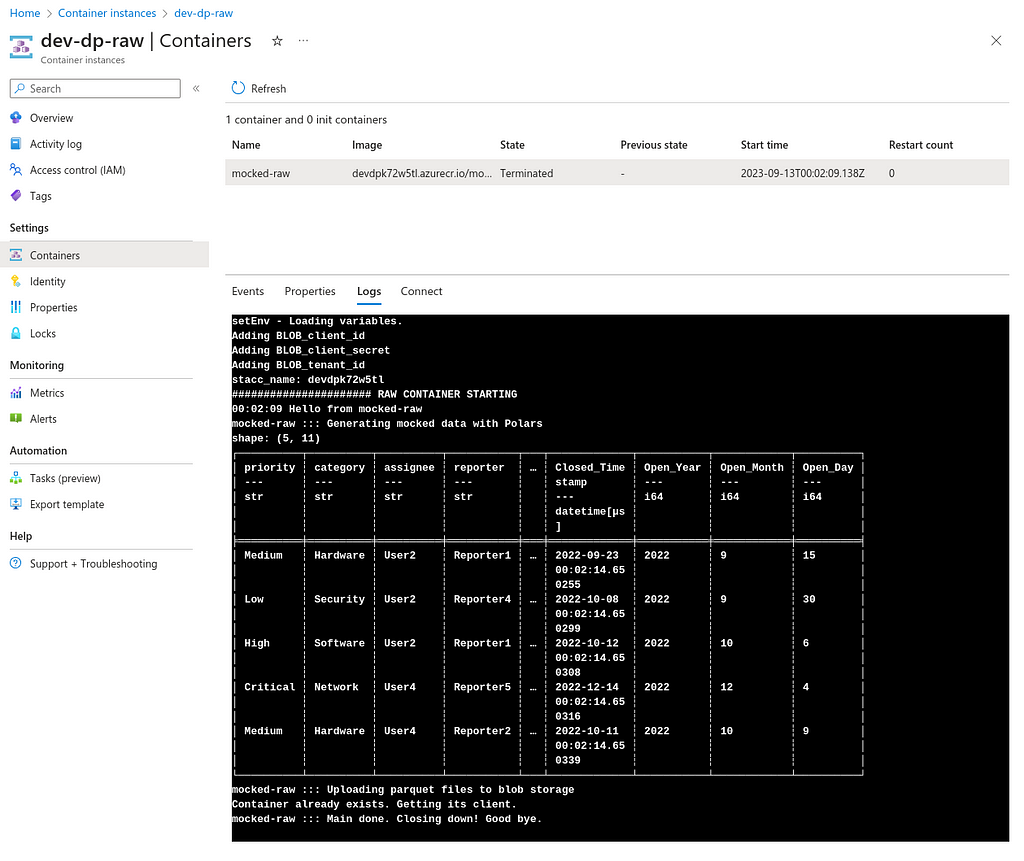
5) Cost
Looking at the Cost Analysis in Azure, we can see that this solution, with mocked data, is very low in price.
Technical details
- Containers execution time : 3 x 30–50 s per day
- Containers CPU : 3 x 2
- Containers Memory : 3 x 2 GB
- Data size : 3 x 40 MB per day
Cost details
The cost for running this solution with mocked data is very low, a couple of $USD per month. But in real scenarios, you can expect longer execution time, more data storage, etc. The point is the same, though: the solution is very cost-efficient!
- Blob Storage: 60% of total cost
- Containers: 35% of total cost
- Others: 5% of total cost
“The point is the same though, the solution is very cost efficient!”
6) Local data exploration in Jupyter Notebook
Instead of deploying Jupyter Notebook instances in the cloud and paying a hefty amount for utilizing cloud computing, this solution suggests using local computing instead. It’s free of charge!
The repository contains an example Notebook that connects to Azure Blob Storage and performs some data exploration on the data.
The notebook will first establish the proper access rights and then download the data of interest. When the parquet files are downloaded, they are loaded into a Polars Dataframe.

With the data in place, we can start doing some computing. Let’s aggregate, visualize, and train a simple Machine Learning Anomaly model!
The data is categorized and summarized using Polars and visualized with matplotlib.
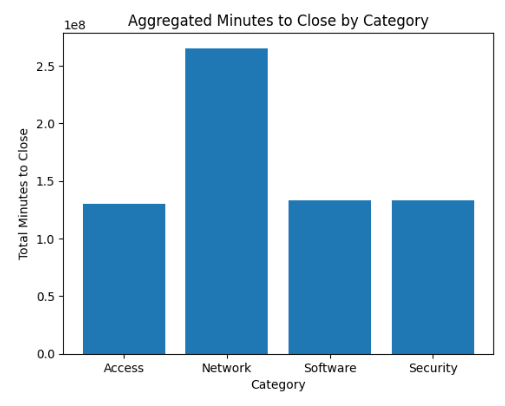
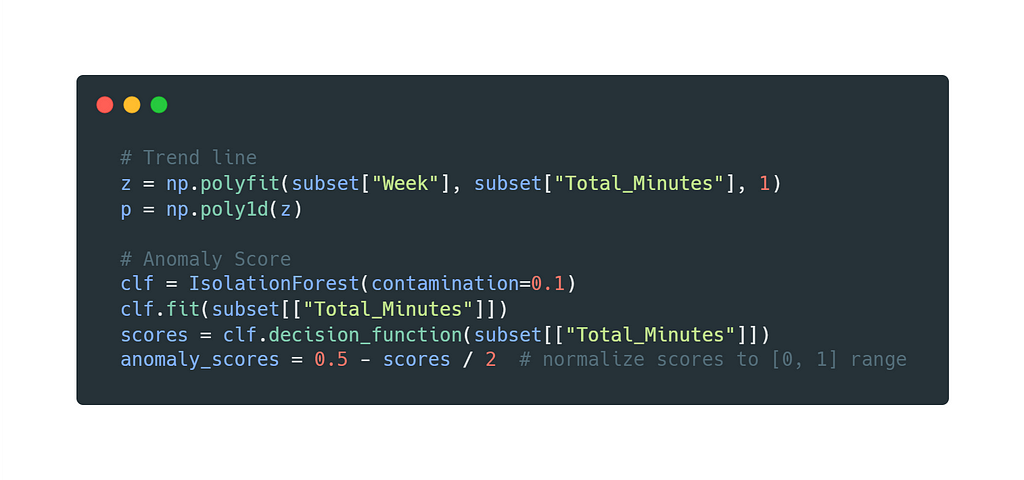
Using IsolationForest (SciKit-Learn) we can train a simple Machine Learning model, get an anomaly score on the data, and plot that right under the weekly minutes aggregation. The example also adds trend lines using Numpy.
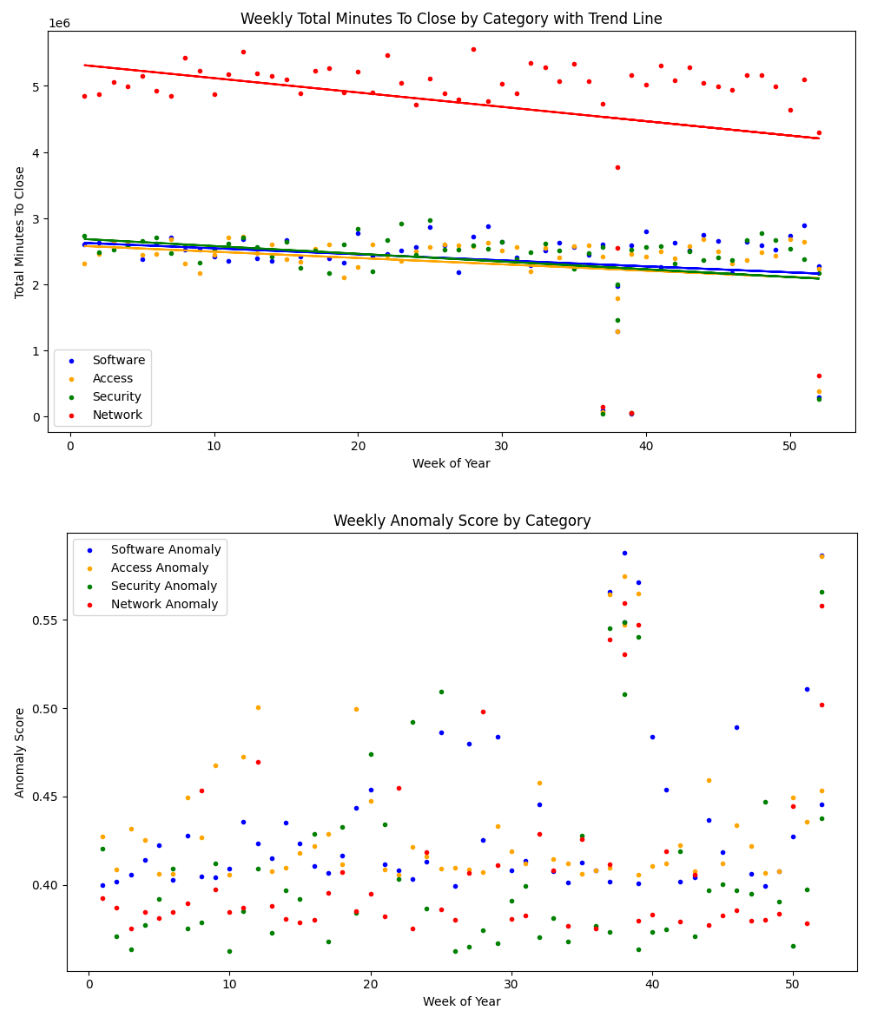
There we go — a cost-efficient data platform with data exploration on a local machine!
The intention is for this to serve as a boilerplate to continue to build upon — without the business case failing due to high cloud costs!
The full code can be found here: https://github.com/martinkarlssonio/azure-dataplatform
Cost-efficient data platform in Azure, harnessing Terraform, Cointainers, Polars and Blob Storage was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.