A more elegant thread-safe solution

Concurrent programming in Core Data may not be difficult, but it is full of traps. Even with ample experience in Core Data, a slight negligence can introduce vulnerabilities into the code, making the application unsafe. As the successor to Core Data, SwiftData provides a more elegant and secure mechanism for concurrent programming. This article will introduce ways SwiftData addresses these issues and offers developers a better experience with concurrent programming.
This article’s content will use concurrency features like async/await, Task, and Actor in Swift. Readers are expected to have some experience with Swift concurrency programming.
Don’t miss out on the latest updates and excellent articles about Swift, SwiftUI, Core Data, and SwiftData. Subscribe to Fatbobman’s Swift Weekly and receive weekly insights and valuable content directly to your inbox.
Using Serial Queues to Avoid Data Race
We often say that managed object instances (NSManagedObject) and managed object contexts (NSManagedObjectContext) in Core Data are not thread-safe. So why do unsafe problems occur? How does Core Data solve this problem?
The main point of insecurity lies in the data race (simultaneous modification of the same data in a multi-threaded environment). Core Data avoids data race issues by operating on managed object instances and managed object context instances in a serial queue. This is why we need to place the operation code within the closures of perform or performAndWait.
Developers should perform operations on the main thread queue for the view context and the managed object instances registered within it. Similarly, we should perform operations on the serial queue created by the private context for private contexts and the managed objects registered within them. The perform method will ensure that all operations are performed on the correct queue.
Read the article, Several Tips on Core Data Concurrency Programming, to learn different types of managed object contexts, serial queues, the usage of perform, and other considerations for concurrency programming in Core Data.
Theoretically, as long as we strictly adhere to the aforementioned requirements, we can avoid most concurrency issues in Core Data. Therefore, developers often write code similar to the following:
func updateItem(_ item: Item, timestamp: Date?) async throws {
guard let context = item.managedObjectContext else { throw MyError.noContext }
try await context.perform {
item.timestamp = timestamp
try context.save()
}
}
When there are a lot of perform methods in the code, it reduces the code’s readability. This is also a problem that many developers complain about.
How To Create a ModelContext Using a Private Queue
In Core Data, developers can use an explicit way to create different types of managed object contexts:
// view context - main queue concurrency type
let viewContext = container.viewContext
let mainContext = NSManagedObjectContext(concurrencyType: .mainQueueConcurrencyType)
// private context - private queue concurrency type
let privateContext = container.newBackgroundContext()
let privateContext = NSManagedObjectContext(concurrencyType: .privateQueueConcurrencyType)
Even privately, operations can be performed directly without explicit creation.
container.performBackgroundTask{ context in
...
}
However, SwiftData has adjusted the creation logic of ModelContext (a wrapped version of NSManagedObjectContext). The type of the newly created context depends on the queue it is in. In other words, a ModelContext created on the main thread will automatically use the main thread queue (com.apple.main-thread), while a ModelContext created on other threads (non-main threads) will use a private queue.
Task.detached {
let privateContext = ModelContext(container)
}
Please note that when creating a new task through Task.init, it inherits the execution context of its parent Task or Actor. This means that the following code will not create a ModelContext that uses a private queue:
// In SwiftUI View
Button("Create New Context"){
let container = modelContext.container
Task{
// Using main queue, not background context
let privateContext = ModelContext(container)
}
}
SomeView()
.task {
// Using main queue, not background context
let privateContext = ModelContext(modelContext.container)
}
This is because, in SwiftUI, the body of a view is annotated with @MainActor, so it is recommended to use Task.detachedto ensure the ModelContext is created and used on a non-main thread with a private queue.
In the main thread, the ModelContext created is an independent instance, different from the context instance provided by the mainContext property of the ModelContainer instance. Although they operate on the main queue, they manage separate sets of registered objects.
Actor: More Elegant Implementation of Serial Queue
From version 5.5 onwards, Swift introduced the concept of Actors. Similar to serial queues, they can be used to solve data race issues and ensure data consistency. Compared to running through the perform method on a specific serial queue, Actors provide a more advanced and elegant implementation approach.
Each Actor has an associated serial queue to execute its methods and tasks. This queue is based on GCD, and GCD is responsible for underlying thread management and task scheduling. This ensures the methods and tasks of the Actor are executed serially, meaning that only one task can be executed at a time. This guarantees the internal state and data of the Actor are thread-safe at all times, avoiding issues with concurrent access.
Although, in theory, it is possible to use Actors to restrict code to the context and operations of managed objects. This approach was not adopted in previous versions of Swift due to the lack of custom Actor executors.
Fortunately, Swift 5.9 addresses this shortcoming and allows SwiftData to provide a more elegant concurrent programming experience through Actors.
Custom Actor Executors: This proposal introduces a basic mechanism for customizing Swift Actor executors. By providing instances of executors, Actors can influence the execution location of their tasks while maintaining the mutual exclusivity and isolation guaranteed by the Actor model.
Thanks to the new feature “macros” in Swift, it is effortless to create an Actor in SwiftData that corresponds to a specific serial queue. Here’s how to do that:
@ModelActor
actor DataHandler {}
By adding more data manipulation logic code to the Actor, developers can safely use the Actor instance to manipulate data.
extension DataHandler {
func updateItem(_ item: Item, timestamp: Date) throws {
item.timestamp = timestamp
try modelContext.save()
}
func newItem(timestamp: Date) throws -> Item {
let item = Item(timestamp: timestamp)
modelContext.insert(item)
try modelContext.save()
return item
}
}
You can use the following method to invoke the code mentioned above:
let handler = DataHandler(modelContainer: container)
let item = try await handler.newItem(timestamp: .now)
Afterwards, no matter which thread calls the methods of DataHandler, these operations will be performed in a specific serial queue. Developers no longer have to struggle with writing a lot of code containing perform.
Do you remember the considerations we discussed in the previous section about creating a ModelContext? The same rules apply when creating an instance using the ModelActor macro. The type of serial queue the newly created Actor instance uses depends on the thread that creates it.
Task.detached {
// Using private queue
let handler = DataHandler(modelContainer: container)
let item = try await handler.newItem(timestamp: .now)
}
The Secret of the ModelActor Macro
ModelActor, what magic does it possess? And how does SwiftData ensure the execution sequence of the Actor remains consistent with the serial queue used by ModelContext?
By expanding the ModelActor macro in Xcode, we can see the complete code below:
actor DataHandler {
nonisolated let modelExecutor: any SwiftData.ModelExecutor
nonisolated let modelContainer: SwiftData.ModelContainer
init(modelContainer: SwiftData.ModelContainer) {
let modelContext = ModelContext(modelContainer)
modelExecutor = DefaultSerialModelExecutor(modelContext: modelContext)
self.modelContainer = modelContainer
}
}
extension DataHandler: SwiftData.ModelActor {}
ModelActor protocol definition
// The code below is not generated by ModelActor
public protocol ModelActor : Actor {
/// The ModelContainer for the ModelActor
/// The container that manages the app's schema and model storage configuration
nonisolated var modelContainer: ModelContainer { get }
/// The executor that coordinates access to the model actor.
///
/// - Important: Don't use the executor to access the model context. Instead, use the
/// ``context`` property.
nonisolated var modelExecutor: ModelExecutor { get }
/// The optimized, unonwned reference to the model actor's executor.
nonisolated public var unownedExecutor: UnownedSerialExecutor { get }
/// The context that serializes any code running on the model actor.
public var modelContext: ModelContext { get }
/// Returns the model for the specified identifier, downcast to the appropriate class.
public subscript<T>(id: PersistentIdentifier, as as: T.Type) -> T? where T : PersistentModel { get }
}
Through the code, it can be seen that there are mainly two operations performed during the construction process:
- Create a ModelContext instance using the provided ModelContainer.
The thread on which the constructor runs determines the serial queue used by the created ModelContext, which in turn affects the execution queue of the Actor.
- Based on the newly created ModelContext, create a DefaultSerialModelExecutor (custom Actor executor).
DefaultSerialModelExecutor is an Actor executor declared by SwiftData. Its main responsibility is to use the serial queue used by the incoming ModelContext instance as the execution queue for the current Actor instance.
To determine if the DefaultSerialModelExecutor functions as expected, we can verify it using the following code:
import SwiftDataKit
actor DataHandler {
nonisolated let modelExecutor: any SwiftData.ModelExecutor
nonisolated let modelContainer: SwiftData.ModelContainer
init(modelContainer: SwiftData.ModelContainer) {
let modelContext = ModelContext(modelContainer)
modelExecutor = DefaultSerialModelExecutor(modelContext: modelContext)
self.modelContainer = modelContainer
}
func checkQueueInfo() {
// Get Actor run queue label
let actorQueueLabel = DispatchQueue.currentLabel
print("Actor queue:",actorQueueLabel)
modelContext.managedObjectContext?.perform {
// Get context queue label
let contextQueueLabel = DispatchQueue.currentLabel
print("Context queue:",contextQueueLabel)
}
}
}
extension DataHandler: SwiftData.ModelActor {}
// get current dispatch queue label
extension DispatchQueue {
static var currentLabel: String {
return String(validatingUTF8: __dispatch_queue_get_label(nil)) ?? "unknown"
}
}
SwiftDataKit will allow developers to access the Core Data objects underlying SwiftData elements.
In the checkQueueInfo method, we retrieve and print the execution sequence of the current actor and the name of the queue corresponding to the managed object context.
Task.detached {
// create handler in non-main thread
let handler = DataHandler(modelContainer: container)
await handler.checkQueueInfo()
}
// Output
Actor queue: NSManagedObjectContext 0x600003903b50
Context queue: NSManagedObjectContext 0x600003903b50
When creating a DataHandler instance on a non-main thread, the managed object context will create a private serial queue named NSManagedObjectContext + address, and the execution queue of the Actor will be the same as it.
Task { @MainActor in
// create handler in main thread
let handler = DataHandler(modelContainer: container)
await handler.checkQueueInfo()
}
// Output
Actor queue: com.apple.main-thread
Context queue: com.apple.main-thread
When creating a DataHandler instance on the main thread, both the managed object context and the actor are on the main thread queue.
Based on the output, it can be seen that the execution queue of the Actor is exactly the same as the queue used by the context, confirming our previous speculation.
SwiftData ensures that operations are executed on the correct queue by using Actors, which can also inspire Core Data developers. Consider implementing similar functionality in Core Data by using a custom Actor executor.
Accessing Data Through PersistentIdentifier
In Core Data’s concurrent programming, in addition to performing operations on the correct queue, another important principle is to avoid passing NSManagedObject instances between contexts. This rule also applies to SwiftData.
If you want to operate on the storage data corresponding to a PersistentModel in another ModelContext, you can solve it by passing the PersistentIdentifier of the object. PersistentIdentifier can be seen as the SwiftData implementation of NSManagedObjectId.
The following code will attempt to retrieve and modify the corresponding data by passing in a PersistentIdentifier:
extension DataHandler {
func updateItem(identifier: PersistentIdentifier, timestamp: Date) throws {
guard let item = self[identifier, as: Item.self] else {
throw MyError.objectNotExist
}
item.timestamp = timestamp
try modelContext.save()
}
}
let handler = DataHandler(container:container)
try await handler.updateItem(identifier: item.id, timestamp: .now )
In the code, we use a subscript method provided by the ModelActor protocol. This method first tries to find the corresponding PersistentModel from the ModelContext held by the current actor. If it doesn’t exist, it will attempt to retrieve it from the row cache and persistent storage.
You can think of it as the equivalent version of Core Data’s existingObject(with:) method. Interestingly, this method directly accessing the persistent storage is only implemented in the ModelActor protocol. From this perspective, the development team of SwiftData is also consciously guiding developers to use this kind of data operation logic (ModelActor).
Additionally, ModelContext also provides two methods to retrieve PersistentModel through PersistentIdentifier. registeredModel(for:) corresponds to the registeredObject(for:) method in NSManagedObjectContext, while model(for:) corresponds to the object(with:) method in NSManagedObjectContext.
func updateItemInContext(identifier: PersistentIdentifier, timestamp: Date) throws {
guard let item = modelContext.registeredModel(for: identifier) as Item? else {
throw MyError.objectNotInContext
}
item.timestamp = timestamp
try modelContext.save()
}
func updateItemInContextAndRowCache(identifier: PersistentIdentifier,timestamp: Date) throws {
if let item = modelContext.model(for: identifier) as? Item {
item.timestamp = timestamp
try modelContext.save()
}
}
The differences between these three methods are as follows:
- existingObject(with:)
If the specified object is detected in the context, this method will return that object. Otherwise, the context will retrieve and return a fully instantiated object from persistent storage. Unlike the object(with:) method, this method will never return an object in a fault state. If the object is neither in the context nor persistent storage, this method will throw an error. Unless the data does not exist on persistent storage, it will always return an object in a non-fault state.
- registeredModel(for:)
This method can only return objects already registered in the current context (with the same identifier). If the object is not found, it returns nil. When the return value is nil, it does not necessarily mean that the object does not exist in persistent storage but is not registered in the current context.
- model(for:)
Even if the object is not registered in the current context, this method will still return an empty fault state object — a placeholder object. When the user accesses this placeholder object, the context will try to retrieve data from persistent storage. If the data does not exist, it may cause the application to crash.
The Second Line of Defense
Not every developer will strictly follow the expected way of concurrent programming in SwiftData (ModelActor). As the code becomes more complex, there may be accidental access or modification of PersistentModel properties on other queues.
Based on the experience with Core Data, such access will inevitably lead to application crashes when the debugging parameter com.apple.CoreData.ConcurrencyDebug 1 is enabled.
For more debugging parameters, please read the article Core Data with CloudKit: Troubleshooting.
But in SwiftData, despite receiving some warning messages (Capture non-sendable), the above operations do not cause issues and allow normal data access and modification. Why is that?
The following code will modify the properties of an Item object on the main thread from a non-main thread. After clicking the button, the property modification will be successful.
Button("Modify in Wrong Thread") {
let item = items.first!
DispatchQueue.global().async {
print(Thread.current)
item.timestamp = .now
}
}
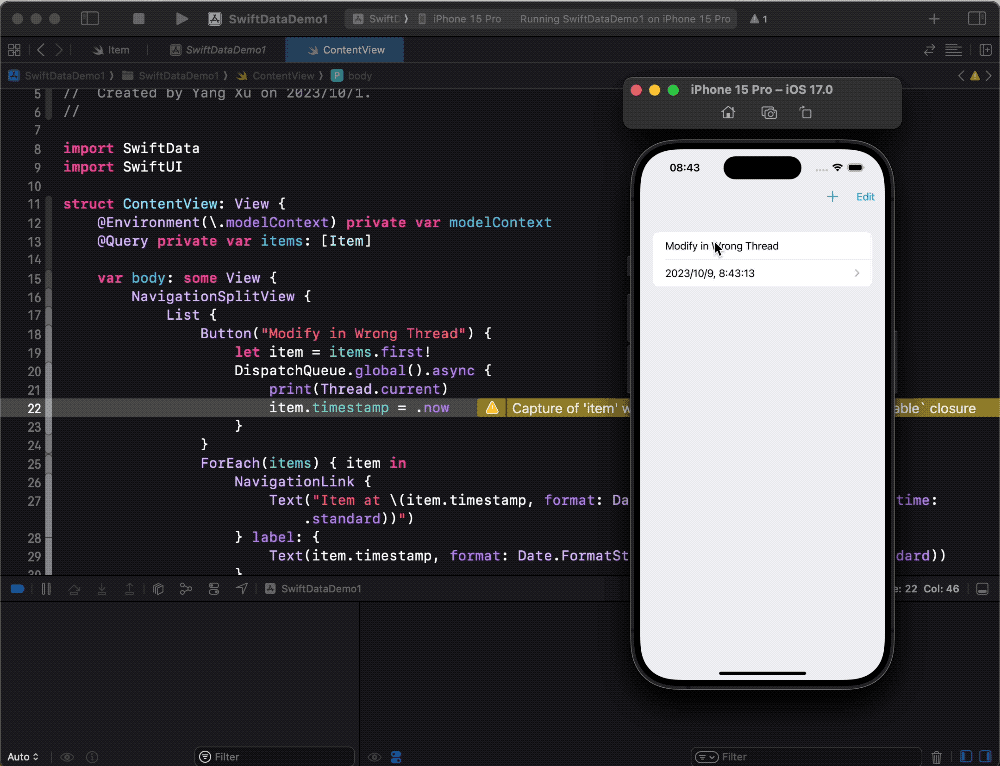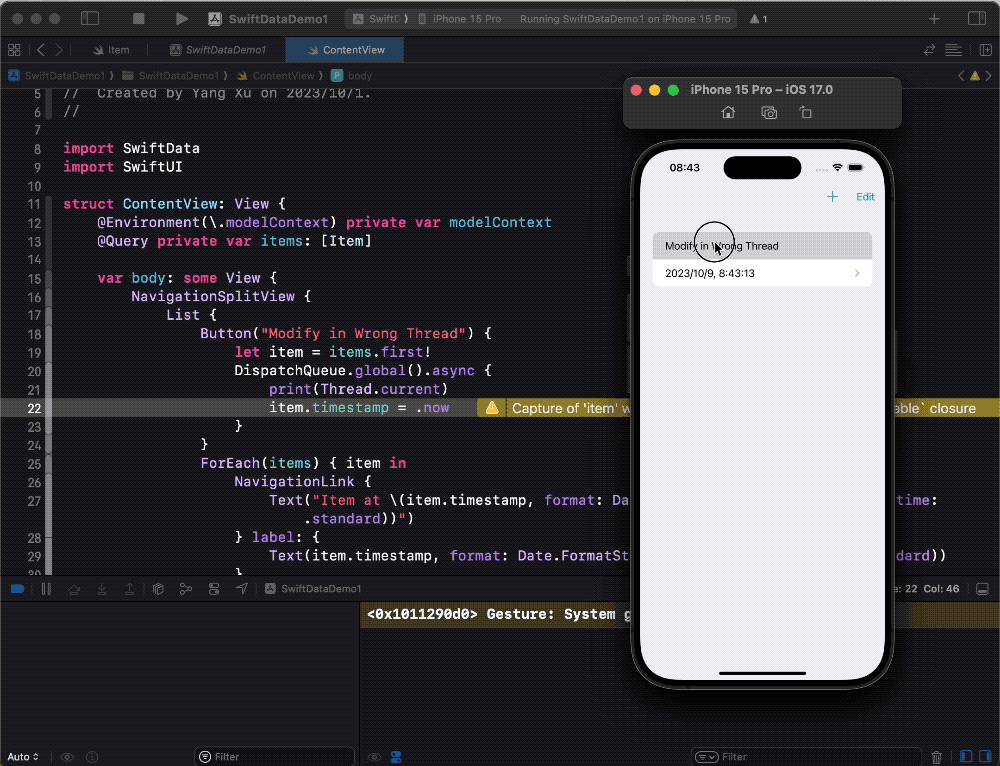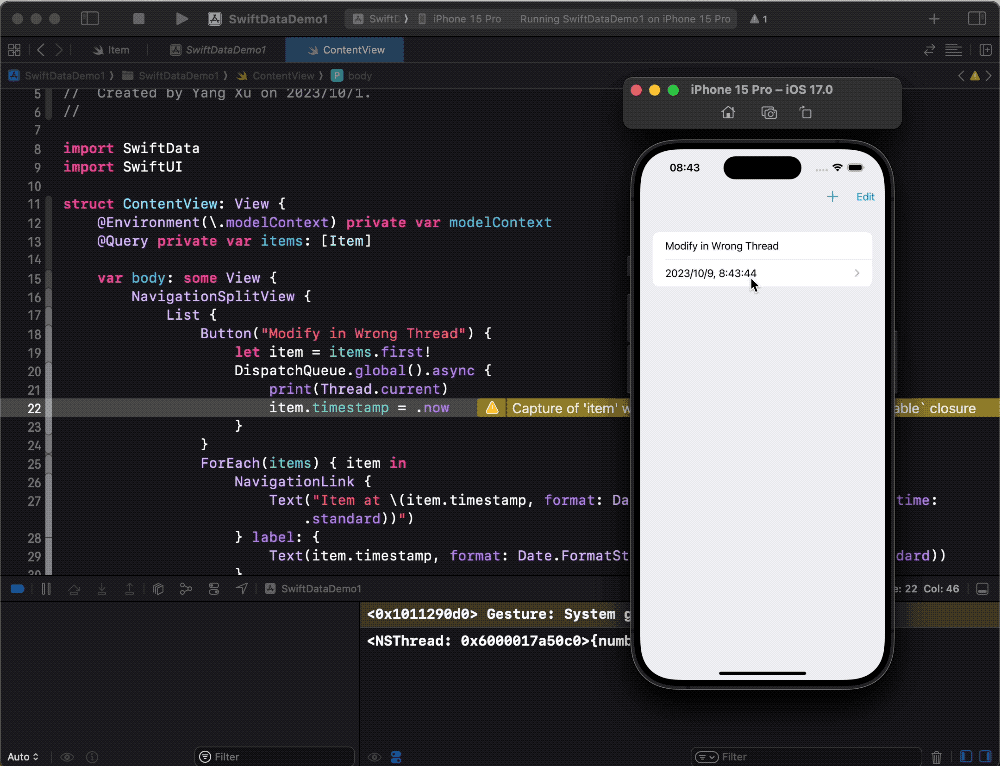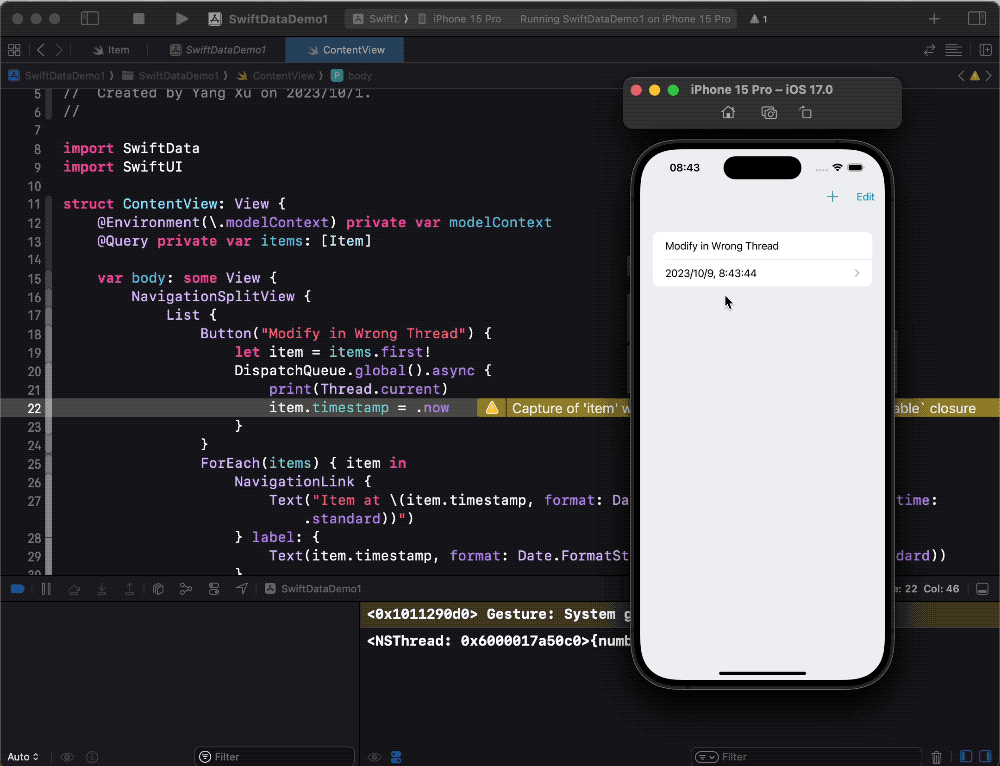
If you have read the previous article, Unveiling the Data Modeling Principles of SwiftData, you may remember that it mentioned SwiftData provides Get and Set methods for PersistentModel and BackingData.
These read and set properties can also schedule tasks in a queue (ensuring thread safety). In other words, even if we modify properties on the wrong thread (queue), these methods automatically switch the operation to the correct queue. Through further experimentation, we discovered that this scheduling ability exists, at least at the implementation level of the BackingData protocol.
Button("Modify in Wrong Thread") {
let item = items.first!
DispatchQueue.global().async {
item.persistentBackingData.setValue(forKey: .timestamp, to: Date.now)
}
}
This section does not encourage bypassing ModelActor for data operations, but through these details, we can see that the SwiftData team has made a lot of effort to avoid thread safety issues.
Summary
Perhaps some people, like me, upon learning about the new concurrency programming approach in SwiftData, would first feel delighted, followed by an indescribable sensation. After some reflection, I have found the reason for this peculiar feeling — code style.
The data processing logic commonly used in Core Data does not fully apply to SwiftData. So, how can we write code that has a more SwiftData flavor? How can we make the data processing code better align with SwiftUI? These are the topics we will study in the future.
If you found this article helpful or enjoyed reading it, consider making a donation to support my writing. Your contribution will help me continue creating valuable content for you.
Donate via Patreon, Buy Me aCoffee or PayPal.
Want to Connect?
@fatbobman on Twitter.
Concurrent Programming in SwiftData was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.