How to eliminate them

Changing an API is a big challenge for both parties — API providers and consumers. While API providers want to be fast and flexible in delivering new features and improvements, integrators expect to receive them quickly. However, the API is also expected to remain stable, and changes do not negatively impact client applications. Undoubtedly, breaking changes are the biggest blocker to achieving those two goals together. Additionally, APIs are almost always expected to fulfill both goals, not just one.
Based on it, let’s consider what options we have.
- Elimination of breaking changes: by making proper design decisions and policies to change the introduction
- Handling of breaking changes: by introducing a mechanism for breaking change introduction, e.g., API versioning
This article will focus on the first element and discuss methods to minimize or even eliminate breaking changes. Of course, each method has its own cost, so I will explain each tradeoff.
In the first part of the article, I will explain exactly what a breaking change is. Next, I will discuss which aspects of changes we should pay attention to. In the last part, we will classify changes based on this knowledge. As we will see, it is only sometimes obvious whether a change is breaking or not.
Breaking Change
Generally speaking, a breaking change refers to any change that causes another component to fail. When it comes to APIs, breaking changes usually results in failures or incorrect behavior in client applications.
Example
Let’s imagine we are maintainers of the API, which return exchange rates between two selected currencies. We are exposing the following endpoint as follows:
GET /exchange-rates?from={sourceCurrency}&to={targetCurrency}.
Which responds with a response body in XML format
<?xml version="1.0" encoding="UTF-8" ?>
<exchangeRate>
<baseCurrency>EUR</baseCurrency>
<quoteCurrency>USD</quoteCurrency>
<rate>1.1128</rate>
<date>2023-04-30</date>
</exchangeRate>
We received customer feedback that a response in JSON format would be more convenient for new clients. We decided to prepare such improvement. Change is ready, and after introduction, the response body will look as follows:
{
"baseCurrency": "EUR",
"quoteCurrency": "USD",
"rate": 1.1128,
"date":"2023-04-30"
}
The question is, what will happen with all client applications that are already using the API with XML format?
It depends on the implementation. The client could receive a response with status 406 Not Acceptable or face deserialisation errors when they try to read JSON as XML. In both cases, change will have a destructive impact on client applications and make them not work.
Does it mean we cannot introduce improvements without breaking client applications?
Not necessarily. We can retain XML representation and add JSON as a second representation. Additionally, we cannot change default behavior if such exist. If we can receive XML representation without explicit response Content-Type indication (request with header Accept: */*), we should still return XML for such request.
As a result, the change is not breaking. Moreover, in the next step, we can iteratively migrate clients using XML representation to JSON.
With that example, we showed that various factors could make change-breaking or non-breaking. Even if we want to achieve the same business goal, we can do it in many ways, with different impacts on client applications. In the next section, we will dive deeper into those factors.
Change Aspects
To better understand the challenges of introducing changes, we need to consider several factors, including:
- Change type: whether the change is an extension, modification, or removal.
- Change location: whether the change is related to the response or request, which part of the message attribute it touches (header, query parameter, etc.).
- Agreements between the API provider and consumers: what the terms are for handling unknown elements, how changes are communicated and delivered, scope of maintenance on the client side.
By examining these factors, we can more accurately determine whether a change is breaking or not. In this section, I will examine them in more detail.
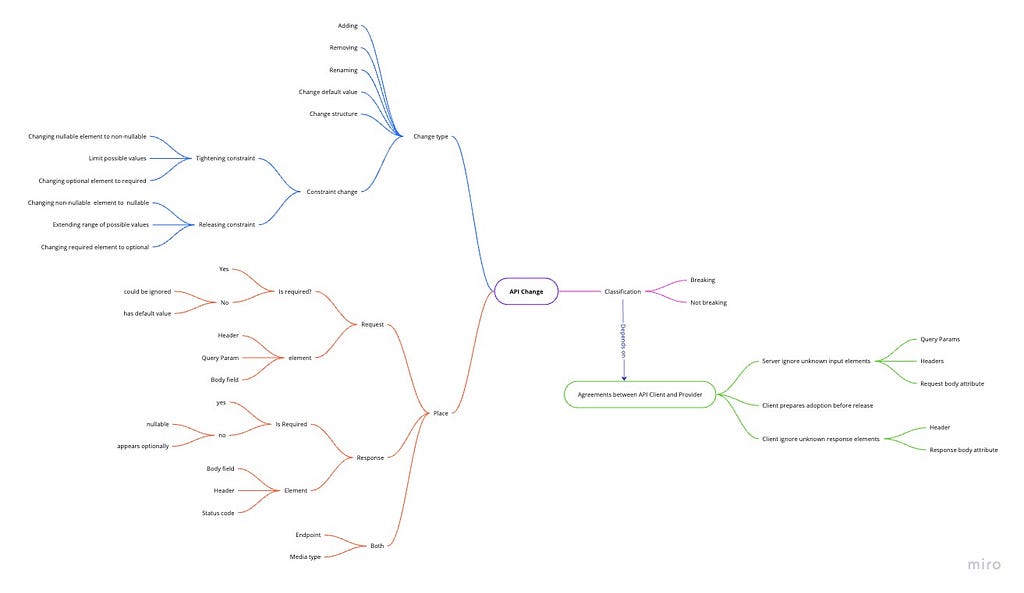
Types of API changes
API changes can fall into several categories: adding, removing, renaming, changing default values, changing structures, and constraint changes.
- Adding changes encompasses all modifications that introduce new elements to the API, including adding new endpoints, query parameters, and attributes to the message body and others.
- Removing changes refers to any modifications that eliminate existing elements from the API, such as removing an endpoint, query parameter, or attribute from the message body and others.
- Renaming changes involve modifying the names of existing elements within the API, such as changing the name of an endpoint, query parameter, or attribute in the message body and others.
- Default value changes: refers to modifying the default values of query parameters, request body attributes, request headers, or any other parameters set by default when requesting the API.
- Structure Changes: refer to modifications made to the organisation of data within message body attributes, such as changing the nesting of attributes, adding or removing fields, or modifying the data type of existing fields.
- Constraint Changes: refer to modifications made to the limitations and requirements placed on API attributes, which may involve releasing or tightening constraints on query parameters, request body attributes, response body attributes, or any other API elements. For example, a constraint change could be changing a nullable attribute to a non-nullable or extending the range of allowable values for an attribute.
Places of changes
We can classify API changes into three categories: request changes, response changes, and common changes.
- Request changes: involve modifications to the elements included in the request, such as query parameters, message body attributes, or request headers.
- Response changes: involve modifications made to the elements included in the response, such as response body attributes, headers, or status codes.
- Common changes: involve modifications made to elements that affect both the request and the response, such as changes to the API endpoint, request method, or media type.
Attribute optionality
When discussing the location of changes, it is important to consider the optionality of the changed attribute. Throughout this article, I will use the terms “optional” and “non-optional” to correspond to the “nullable” and “non-nullable” adjectives used in response messages — and the “required” and “non-required” adjectives used in request messages.
Agreements between providers and consumers
The contract between API providers and consumers typically outlines each party’s expectations and responsibilities when using the API. These agreements may cover usage limits, access rules, supported protocols, error handling procedures, and change deployment policies. By formalising their relationship through such agreements, the API provider and API consumer can establish clear expectations for how the API should be used and maintained.
To determine whether an API change is breaking or non-breaking, the following agreements are relevant:
- Client-side handling of unknown response elements
- Server-side handling of unknown request elements
- Client’s ability to prepare for incoming changes
Later, I will explain how these agreements impact the categorisation of changes.
Change Classification
Based on the abovementioned aspects, we can classify each change as breaking or non-breaking. As we said before, breaking change is a change to an API that would cause existing client applications or integrations to stop working or behave incorrectly.
Please note that this classification is just generalisation and in certain circumstances, each change could be breaking, even ones that don’t change an interface. As Hyrum’s Law says:
With a sufficient number of users of an API, it does not matter what you promise in the contract: all observable behaviors of your system will be depended on by somebody.
This has implications for API providers who want to change their APIs. Even small changes can have significant consequences if an API has many users. API providers must be careful when introducing changes to avoid breaking existing integrations and consider each case individually.
In the classification process, I will split the API changes into six groups:
- Changes considered as always non-breaking
- Changes considered as non-breaking when clients handle unknown response attributes
- Changes considered as non-breaking when the server handles unknown request attributes
- Changes considered as non-breaking when clients agree to prepare incoming changes
- Changes considered as non-breaking if clients agree to prepare incoming changes and the server handles unknown request attributes
- Special cases
1. Changes not always breaking
Agreements
- Client-side handling of unknown response elements: NO
- Server-side handling of unknown request elements: NO
- Client’s ability to prepare for incoming changes: NO
Even if clients and servers cannot handle unknown attributes and clients do not agree to prepare for incoming changes, many API changes are still non-breaking. Typically, such changes involve functionalities that would not be utilised without explicit indication in the client code or situations where the server can handle the lack of action on the client side.
Changes considered as non-breaking
Non-breaking changes include adding new endpoints, media types, optional request attributes, removal of optional response attributes, releasing input constraints, and tightening output constraints. The complete list is below:
- Adding new endpoints
- Adding optional query parameters
- Adding optional request body attributes
- Adding optional request headers
- Adding new media types
- Changing non-optional request body attributes to optional
- Changing non-optional query parameters to optional
- Changing non-optional request headers to optional
- Extending the range of possible values for request body attributes
- Extending the range of possible values for query parameters
- Extending the range of possible values for request headers
- Changing optional response body attribute to non-optional
- Changing optional response headers to non-optional
- Limiting the range of possible values in response to body attributes
- Limiting the range of possible values in response headers
- Removing optional response body attributes
- Removing optional response headers
- Changing the default value of request body attributes
- Changing the default value of query parameters
- Changing the default value of request headers
2. Clients handle unknown response attributes
Agreements
- Client-side handling of unknown response elements: YES
- Server-side handling of unknown request elements: NO
- Client’s ability to prepare for incoming changes: NO
Suppose the client agrees to handle unknown response elements, usually by ignoring them. In that case, it gives the API provider more flexibility and the possibility to introduce non-breaking changes related to response attributes.

Handling of unknown attributes is related to Robustness Principle, also known as Postel’s Law, described in RFC-1958.
Be strict when sending and tolerant when receiving. Implementations must follow specifications precisely when sending to the network, and tolerate faulty input from the network. When in doubt, discard faulty input silently, without returning an error message unless this is required by the specification.
The principle encourages developers to write code that is flexible and tolerant of errors and to be lenient in what they accept as input. This is intended to increase the robustness and interoperability of network protocols and software applications. The rule is considered an anti-pattern by many developers, and its drawbacks are described, for example, in this internet draft. Considerations about this principle could be described in a dedicated article.
This discussion will focus on the potential drawbacks of ignoring unknown elements.
Challenges
- Evaluate if clients handle unknown attributes: even if we agree with clients that they handle unknown attributes, we have no mechanism to check it. Clear documentation and communication before change introduction are important here to avoid unexpected breaks.
- Client can process incorrect data based on incomplete response: since the client application is resistant to unknown elements, it can lead to late detection of errors where important response attributes were omitted
- Integrators can omit useful features: similarly, as in the previous case, integrators could be unaware of useful response attributes since their application is working without them
To face all challenges described above, clear documentation and communication before introducing changes are crucial.
Changes that become non-breaking
When clients handle unknown attributes, it creates the possibility to introduce non-breaking changes related to the response, such as the following:
- Adding response body attributes
- Adding response header
- Renaming optional response body attributes
- Renaming optional response headers
3. Server handles unknown request attributes
Agreements
- Client-side handling of unknown response elements: NO
- Server-side handling of unknown request elements: YES
- Client’s ability to prepare for incoming changes: NO
If the server can handle unknown elements, it creates opportunities for changes such as removing and renaming. In such cases, if the client does not respond to the introduced changes, the server will ignore any elements that have been removed or renamed.
Challenges
- Typos on the client side may go undetected: if a client makes a typo in an optional request attribute, it will be ignored.
- Integrators may be unaware that a certain attribute is no longer supported: if we remove a request attribute without proper communication, the integrator may not know that the attribute is no longer in use.
- API evolution can lead to entropy in the client implementation: over time, the number of unknown request attributes sent by the client can increase, causing technical debt in the client implementation.
To address these challenges, we can consider implementing a soft alerting mechanism, such as introducing a response body attribute called warnings:[] that can report the appearance of unknown attributes.
Changes that become non-breaking
The list includes the removal of request attributes and the renaming of optional request attributes:
- Removing request body attributes
- Removing query parameters
- Removing request headers
- Renaming optional request body attributes
- Renaming optional query parameters
- Renaming optional request headers
4. Clients can prepare for incoming changes
Agreements
- Client-side handling of unknown response elements: NO
- Server-side handling of unknown request elements: NO
- Client’s ability to prepare for incoming changes: YES
When clients can prepare for incoming changes in advance, new opportunities arise to handle the changes in a non-breaking manner. API consumers are typically given more time to prepare for such changes. Additionally, API providers can offer a beta version that includes upcoming changes. This approach allows API customers to test their adoption of the changes safely.
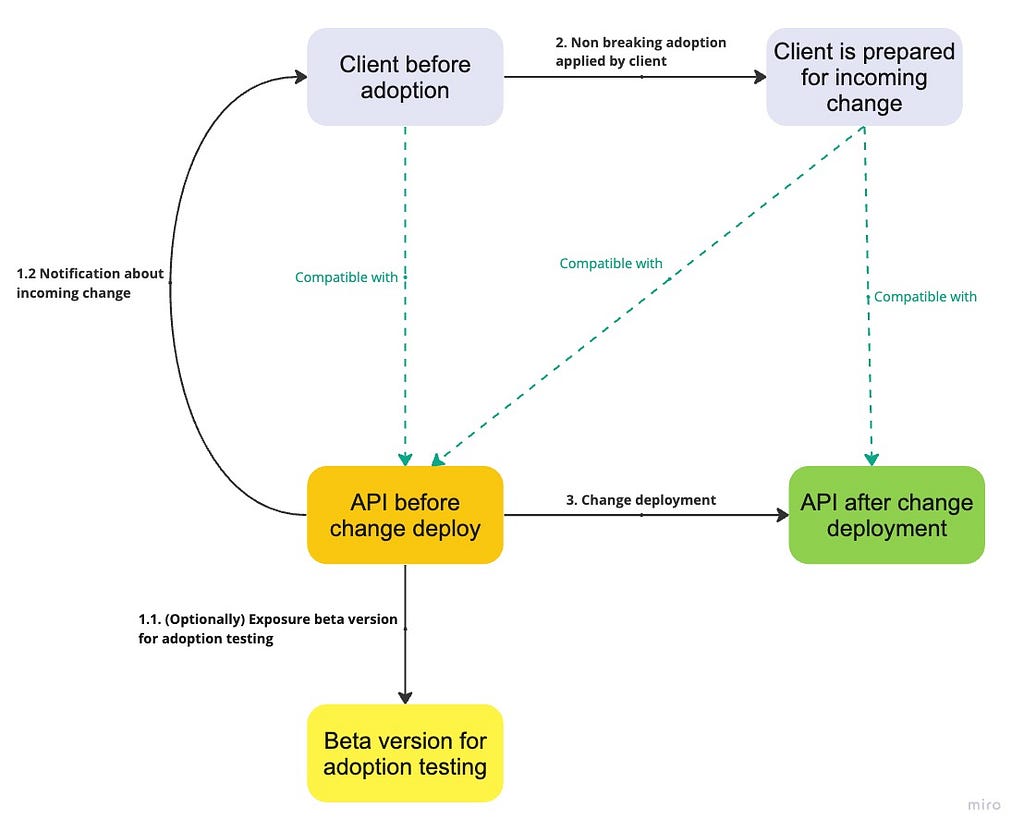
Challenges
- The adoption process can be challenging for integrators, as it may be difficult to test the correctness of the changes before they are introduced to production.
- Integrators may refuse to adopt changes if they cannot do so, potentially blocking the introduction of non-breaking changes if we wish to avoid breaking changes.
- There is no foolproof method to confirm that all clients have prepared for adoption. Although we can log and monitor received requests, we have no guarantee that clients are prepared for changes related to response attributes.
To handle these points, clear communication is necessary. We need to precisely define the terms of API usage, including maintenance on the client side. We should also clearly indicate which elements are deprecated and will be removed in the future. Additionally, we should make the adoption process comfortable for integrators by providing a sufficient adoption period, clear instructions on how to perform the adoption, and the possibility of testing the adoption before changes are introduced to production.
Changes that become non-breaking
The list includes the removal of endpoints, media types, non-optional response attributes, and tightening input constraints:
- Removing endpoints
- Removing media types
- Removing non-optional response body attributes
- Removing non-optional response headers
- Limiting possible values in request body attributes
- Limiting possible values in query parameters
- Limiting possible values in request headers
- Changing optional request body attributes to mandatory
- Changing optional query parameters to mandatory
- Changing optional request headers to mandatory
5. Clients can prepare for incoming changes, and the server handles unknown request attributes
Agreements
- Client-side handling of unknown response elements: NO
- Server-side handling of unknown request elements: YES
- Client’s ability to prepare for incoming changes: YES
When agreements from points 3 and 4 are fulfilled, the possibility of adding non-optional request attributes opens up. In this case, the client is notified of the incoming introduction of the new attribute and can prepare for adoption before the server starts handling the new non-optional attribute.
It’s worth noting that this scenario is more theoretical than practical, as it’s usually simpler to introduce an optional attribute and make it non-optional (by tightening input constraints) after some time. In such cases, only the client’s ability to prepare for incoming changes is needed.
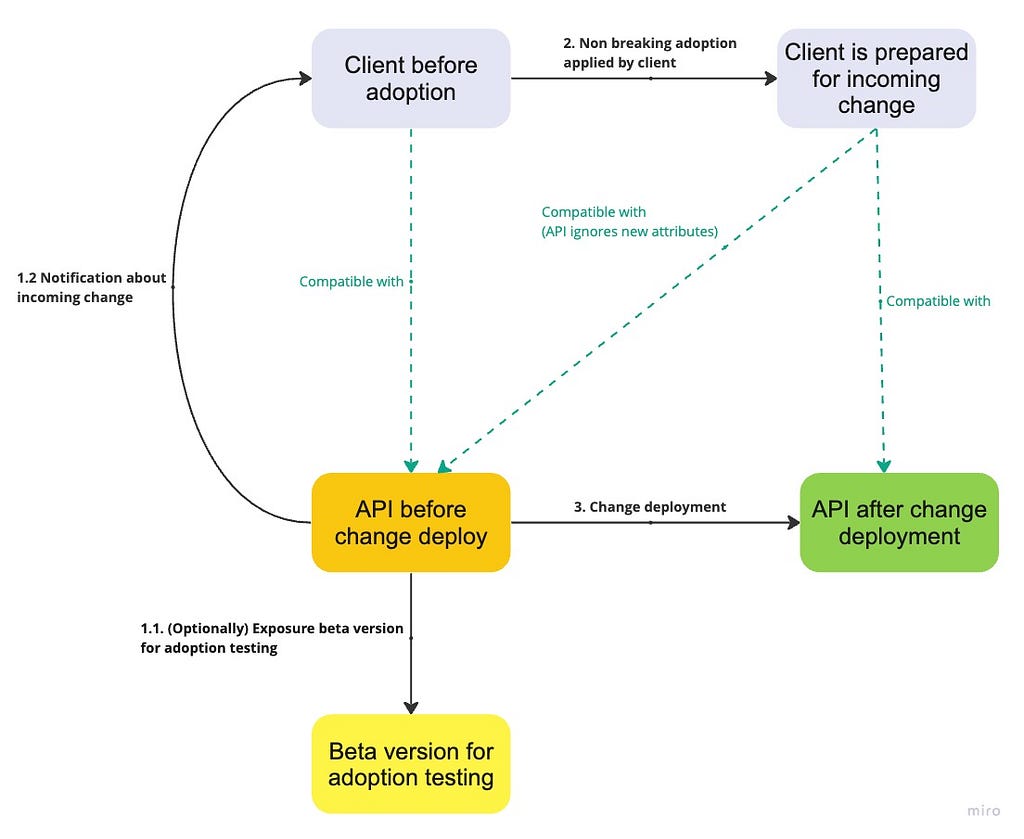
Challenges
All challenges related to the server-side handling of unknowns and the client’s ability to prepare for incoming changes.
Changes that become non-breaking
The list includes adding non-optional request attributes:
- Adding non-optional request message attributes
- Adding non-optional query parameters
- Adding non-optional request headers
6.1 Special case: renaming
Agreements
- Client-side handling of unknown response elements: NO
- Server-side handling of unknown request elements: NO
- Client’s ability to prepare for incoming changes: YES
Even if all three agreements are fulfilled, changes like renaming endpoints or non-optional attributes remain breaking if we want to do them atomically. However, they can be handled easily in two steps:
- Adding a new endpoint or attribute that behaves like the old one. The legacy endpoint or attribute can be marked as deprecated. If the change is related to the request attribute, perform the steps described in the previous point (introduce optional attribute and later tighten constraint).
- After all, clients start using the new endpoint or attribute. The old one can be safely removed.
By following this approach, only the client’s ability to prepare for incoming changes is needed.
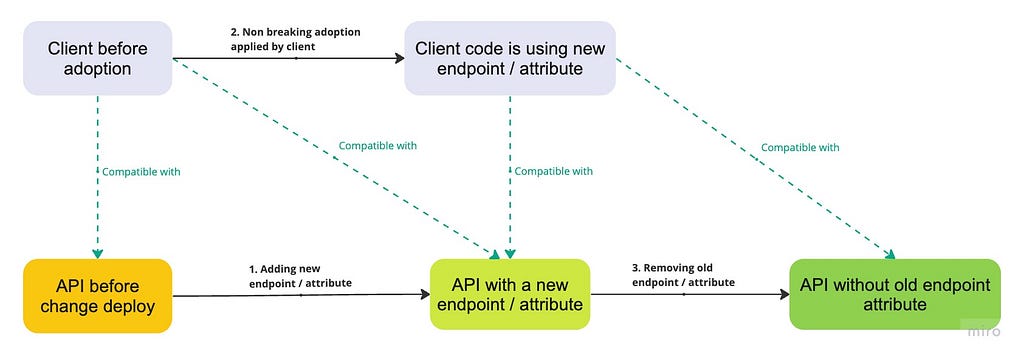
Challenges
Include difficulties related to clients’ ability to prepare for incoming changes and the fact that the process is split into steps and can therefore take longer.
Changes that could be handled in a non-breaking manner
- Renaming endpoints
- Renaming non-optional request body attributes
- Renaming non-optional query parameters
- Renaming non-optional headers
- Renaming non-optional response body attributes
- Renaming non-optional response headers
6.2 Special case: change structure
Agreements
- Client-side handling of unknown response elements: NO
- Server-side handling of unknown request elements: NO
- Client’s ability to prepare for incoming changes: YES
Structural changes are special API change that typically involves representing message attributes. These changes are often considered breaking, but it is possible to handle them non-breakingly using a special approach.
Example
Let’s imagine we have a simple API for collecting information about a user’s weight and height, with the following attributes in the request and response body:
- name: person’s name represented as a text value
- height: value in cm, represented as a floating point number
- weight: value in kg represented as a floating point number
Here’s the structure of request/response body:
{
"name": "Luke",
"height": 188,
"weight": 98
}
After some time, the business requirements change, and we need to handle other units, such as feet, inches, and pounds. In this case, we would need to change the representation of the “height” and “weight” attributes to accommodate these new units. One possible solution is to represent those attributes as a nested structure composed of the following elements:
- value: a floating-point number
- unit: text value
Proposed structure of request/response body:
{
"name": "Luke",
"height": {
"value": 188,
"unit": "cm"
},
"weight": {
"value": 98,
"unit": "kg"
}
}
How can we handle such change in a non-breaking way?
It’s important to support multiple representations of the attribute during a transition period to handle structural changes in a non-breaking way. If the change occurs in the request body, the logic should be implemented on the server side. If the change occurs in the response body, the logic should be implemented on the client side. The difficulty of implementing such logic depends on the programming language and frameworks used in the code.
This is an example of how it could be done in Java with the Jackson library.
Firstly, we need to implement classes that we will use for deserializing the message body.
record Person(String name, Weight weight, Height height) {
}
@JsonRootName("value")
record Weight(@JsonProperty("value") Double value, @JsonProperty("unit") String unit){
@JsonCreator
Weight{}
@JsonCreator(mode = JsonCreator.Mode.DELEGATING)
Weight(Double value) {
this(value, "kg");
}
}
@JsonRootName("value")
record Height(@JsonProperty("value") Double value, @JsonProperty("unit") String unit){
@JsonCreator
Height{}
@JsonCreator(mode = JsonCreator.Mode.DELEGATING)
Height(Double value) {
this(value, "cm");
}
}
In the second step, we must apply additional configuration to the ObjectMapper.
public ObjectMapper objectMapper() {
return new ObjectMapper().enable(WRAP_ROOT_VALUE);
}
With the approach outlined above, we build an adapter that can handle both the original JSON structure and the updated structure with the nested “value” and “unit” elements. This adapter can be used to deserialize incoming requests or responses, ensuring compatibility during the transition period when both representations of the attributes are possible.
Challenges
When working with many clients, predicting which programming languages and frameworks they use can be difficult. As a result, we cannot assume that a structural change in the response message will be easy for all clients to handle. It is essential to allow clients adequate adoption time and provide clear instructions on updating their code to handle the new message structure.
If the change only affects the request body and the API provider has the necessary tools to implement and document the logic properly, then the change can be considered safe for API clients.
Changes that became non-breaking
- Changing the structure of response body attributes
- Changing the structure of request body attributes
Summary
We have established that API changes can be described by a combination of parameters, such as change place and change type. Furthermore, we have demonstrated that each variation of these parameters has the potential to be handled in a non-breaking way, depending on the type and location of the change, as well as any agreements between the API provider and consumers. However, as Hyrum’s Law states, any change that affects the product exposed by the API can be considered breaking in certain circumstances.
The main point of this article is to explain the factors determining whether an API change is considered breaking. Understanding these factors makes it easier to assess whether a given change is breaking and how it should be handled. Additionally, by understanding how agreements between API providers and consumers can impact breaking changes, we can adjust them to our needs during the API design or maintenance.
Breaking Changes in APIs was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.