
Introduction
I have been working with LLM-centered development for almost two years now, and I’ve faced ups and downs in terms of results, usually fixable by using better models. But there’s always a threshold to what can be solved this way, so I developed a solution that draws on my experience as a full-stack developer.
Motivation: LLMs vector DB limitations
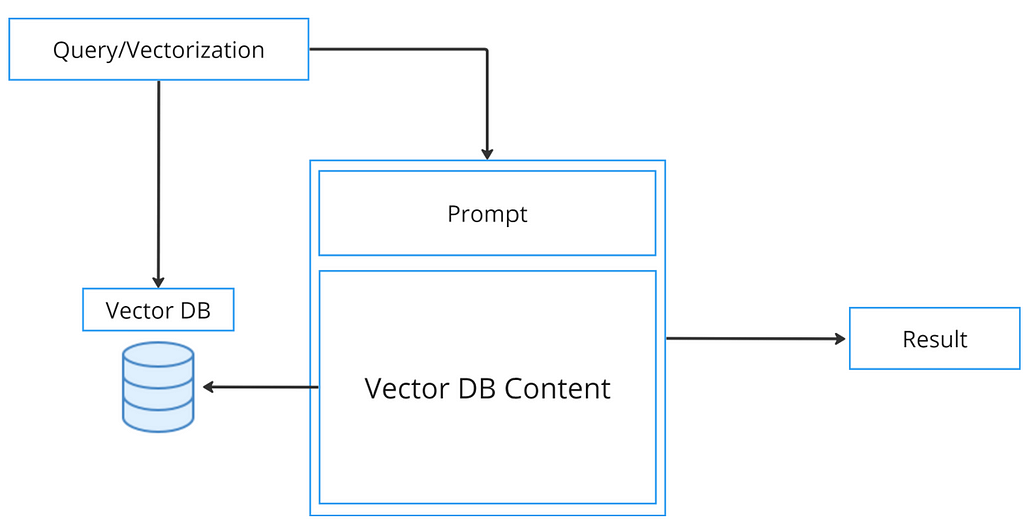
I think this piece by Greg Kamradt says it all. Vector databases have gained popularity primarily because they pair exceptionally well with LLMs. However, the issue isn’t just that development costs tend to overshadow the benefits, but also that they present specific challenges such as:
Granularity challenges: Populating the database with data involves converting your content into vectors. This process is string-based, and depending on the nature of the document, it requires breaking it into chunks. Achieving this demands a considerable amount of work.
Window/Context management: Handling chunks can be straightforward when dealing with direct and simple data, a typical scenario with database data processing. However, complications arise with lengthy documents accompanied by constant requests necessitating some form of reasoning.
Microservices Architecture and Atomicity
Microservices are like Lego blocks of the software world. Each block is a self-contained service that performs a specific function. They work in isolation but can interact with each other — sort of like how Reddit threads operate. You have a unique piece of content, yet it’s part of a colossal ecosystem.
Event-Driven Interaction & Data Flow Patterns
In an event-driven architecture, one service generates an event, and the others, interested in this message react to it, allowing the system to adapt in real time without each microservice constantly eavesdropping on the others. An event is dispatched — akin to a signal flare. The receiving service updates and the cycle continues.
Reasoning: Strengths of fine-tuning
Comes down to “reason”, in this case, reasoning skills. The fact that you can simply get the information of the trained data instead of passing the context all the time can give you better results and speed/cost reductions.
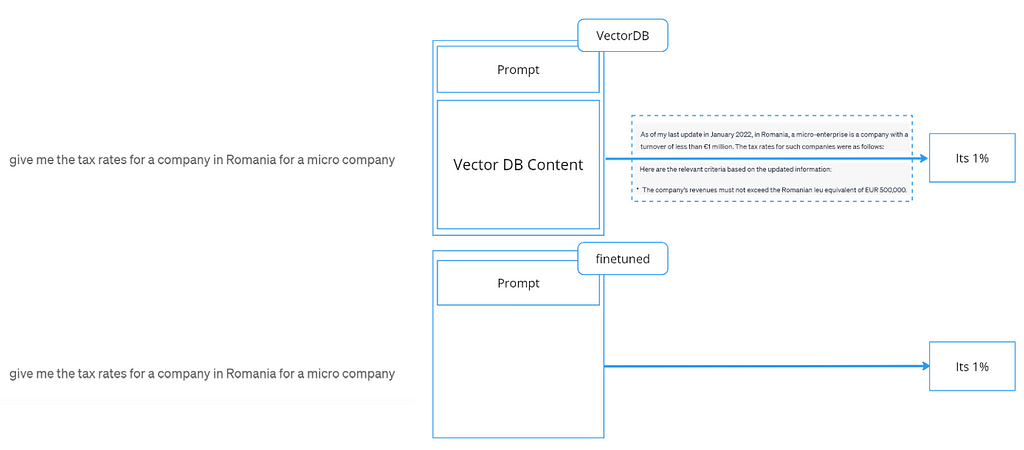
Vector DB, or in this case “prompt context” is great when your data doesn’t need reasoning skills and “granularity” of information is not a problem. Just query and process the data. But if you have a 10-page information-dense document, fine-tune and ask.
Adapting the Pieces
In this segment, we delve into a comparative exploration between Microservice and Micromodel architectures. The image above is direct and easy to understand so let’s take it one at a time.
Orchestrating with GPT-4 — The BFF for Micromodels
GPT-4, in the realm of Micromodel architecture, orchestrates the symphony of smaller models. Drawing parallels with the Back for Frontend Service in Microservices, GPT-4 navigates the flow, ensuring seamless integration and communication. Takes care of the reasoning in terms of heavy-lift, just asks for the right information.
Finetuned Functionality — The Role of GPT 3.5 Microservices
It’s simple to understand and straightforward. Does something specific and takes care of a certain type of information. Finetuned for the task, capable of summarization and digesting the information, letting the GPT4 do most of the thinking.
Synchronizing Events with OpenAI — Functions as Events
At the crossroads of communication, the OpenAI Function emerges as a sort of “Event” system. On the lower level, it was developed to run multiple services present in the Plugins and Advance Data Analytics, as a “classificatory” middleware, so it can possible to understand what task to perform. Works great as an event system for this case.
Use case: Supreme Tax Advisor
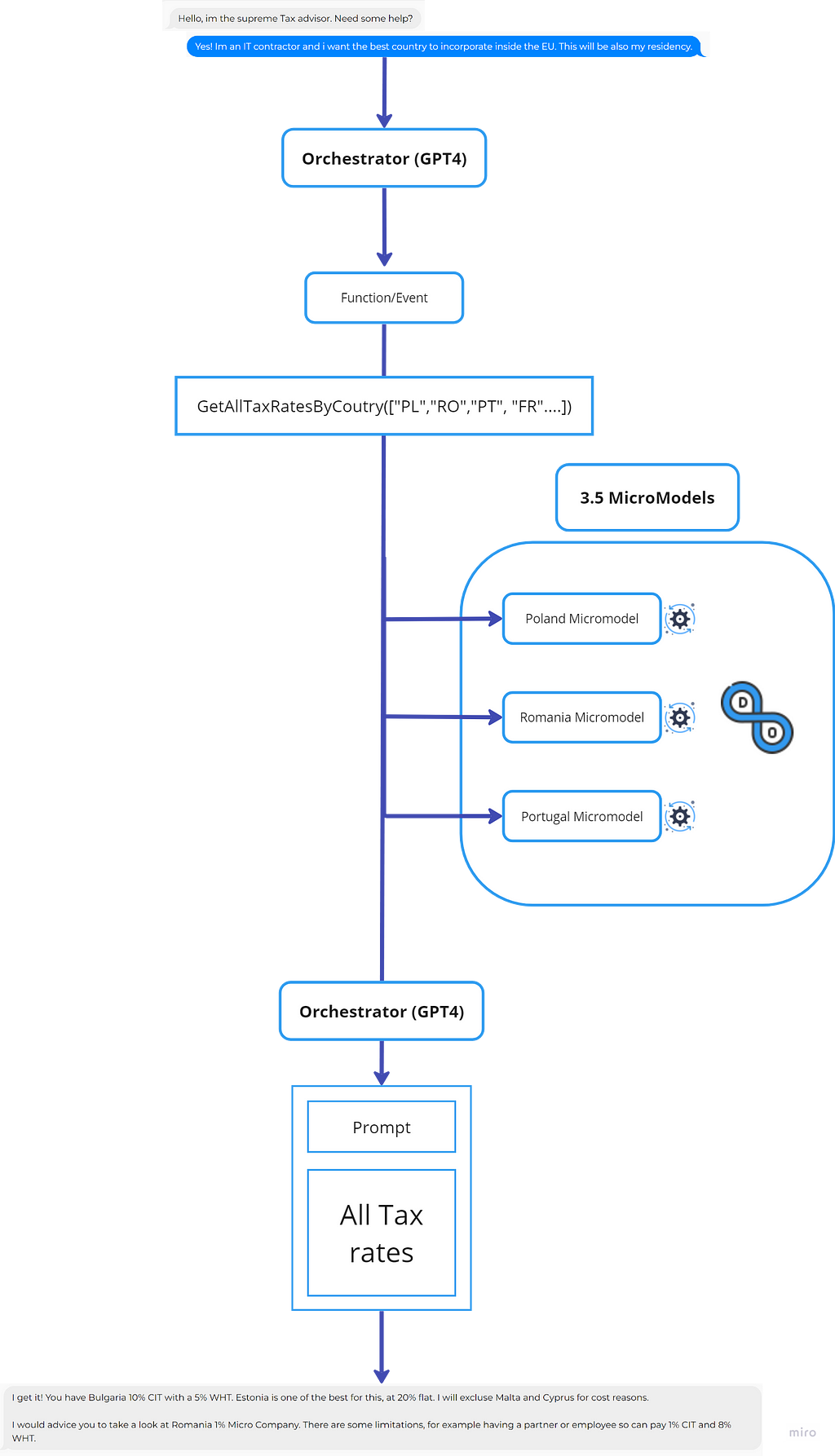
Was you may already assume, I like tax law, but this example is really good so let’s break it down with all the components!
1. Initiating Dialogue with the Orchestrator: This is the entry for the flow. Here the reasoning skills will be used to see if makes sense to trigger a function event.
2. Function Triggering: The function contains the input of the micromodel to call GetAllTaxRatesByCoutry, which in the example above calls all countries in the EU.
3. Micromodels: The micro models are prompted and the result is returned. Each model has an LLMOps behind it, so the finetuning can be done for each model with the right amount of data.
4. Crafting a Comprehensive Response: Once the response of the Micromodels comes back, a prompt is built and created to make the final ending with reasoning.
Conclusion
As we journeyed through the realms of Large Language Models (LLMs), Vector Databases, and Micromodel architectures, we’ve unveiled the intricate layers and components that enable nuanced solutions to diverse problems. Let’s distill the insights gained and understand when and why to leverage these powerful tools.
Balancing VectorDB and Finetuning
VectorDB shines in scenarios where data doesn’t require extensive reasoning skills and the granularity of information is manageable. It offers a swift, process-driven approach to querying and managing data. However, when dealing with information-dense documents or contexts requiring intricate reasoning, finetuning emerges as the superior option, providing enhanced results and cost-effectiveness by leveraging trained data.
The Art of Finetuning
Finetuning is an art of refinement and specialization. It empowers models to digest, summarize, and interpret vast amounts of information, allowing them to think and reason more effectively. The technique is indispensable when addressing complex queries, long documents, or nuanced requests, enhancing the LLM’s ability to provide precise and contextually relevant responses.
Embracing MicroModels
MicroModels, akin to the versatile Lego blocks of the software world, bring modularity and specificity to the table. They are particularly beneficial when a task demands diverse expertise or when interacting with multiple, specialized knowledge bases. Each MicroModel, finetuned and backed by LLMOps, can be tailored to handle specific data and tasks, ensuring a harmonious symphony of knowledge and adaptability.
Final Thoughts
In conclusion, the journey from VectorDB to MicroModels, orchestrated by GPT-4, and finetuned with precision, offers a versatile landscape for solving problems. The choice between VectorDB and finetuning, and the decision to employ MicroModels, hinges on the nature of the task, the complexity of the data, and the level of reasoning required. By understanding the strengths and applications of each component, we can craft tailored solutions that navigate the challenges and harness the potential of LLM-centered development.
MicroModel Architecture: Scaling Large Language Models with Microservices was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.