
This article is about an often misunderstood system resource — CPU time. As opposed to memory, which can be easily measured and attributed to computer processes, things are not so simple regarding the execution time of said processes. Besides explaining how CPU time is consumed, we will delve into the causes of excessive usage, how it can be mitigated, and what you can do if it is truly unavoidable.
I’m here to convince you that a seemingly trivial issue of excessive usage has practical consequences. You will see how one badly written microservice can affect the rest of your architecture components, which share resources. Worse yet, you can be one careless line of code away from selling your house to Amazon just because your app was hoarding CPU time throughout the night. At the very least, consider the damage to the environment.
Objective Facts for a Change
Processes are made up of threads. Processes merely represent programs in execution, and threads are the ones that the processor is executing. For a thread to run, it needs to be scheduled for execution on a processor core.
A CPU cycle is the time required to perform a simple processor operation. Processor clock speed is the number of cycles it can perform per second, appropriately measured in Hertz. Threads are just that — sets of operations which are to be performed. Therefore, higher clock speeds mean more work your threads can handle within a second. What’s left is to decide how many cycles each thread gets and, more importantly, which threads require these cycles in the first place. I’ll explain.
Let’s take an HTTP server as an example. When it receives a request, it handles it, requiring the processor’s attention. When our server is not busy handling requests, it is idling. There is no point in scheduling such a process when it does absolutely nothing, which brings us to our final point:
Resource usage is natural. Needless resource usage is bad. Not a hot take; we’re still talking objective facts. It does not matter whether your application performs well 100% of the time — if it’s needlessly hogging system resources, it can potentially prevent other processes from receiving them.
With that out of the way, let me introduce the three stages of CPU usage grief.
Stage 1: Denial (Naming the Core Issues)
You may disagree, but some high CPU use cases are inexcusable. Case in point, we will see some examples of faulty code snippets and how we can mitigate their issues.
The source code for the upcoming snippets can be found here. To run and easily display the resulting behavior of running these snippets, we will run a Docker container using a prebuilt image that already includes the source code.
You do not need to actually run anything. I’ve already worked hard to make this article as visually understandable as possible. With that said, if at any point you feel as if I’m taking you for an absolute buffoon, feel free to run the related commands and see the outcome for yourself.
Tight loops
Here is a code snippet for a program that performs a computation over and over:
"""
Simplest tight loop which does absolutely nothing.
"""
def do_work():
_ = 1 + 1
def problem():
while True:
do_work()
You may justify this code (hence the denial stage) — your do_work might need to poll for a change in a file, constantly update a state of some kind, or anything really. Unsurprisingly, it isn’t very CPU-friendly, as you can see below:
# runs the snippet in a container
docker run --rm --name cpu-hogging -it vladpbr/cpu-hogging:python -c "from samples.tight_loop import problem; problem()"
# displays resource statistics for the container (run in a separate terminal)
docker stats cpu-hogging

To clarify, the CPU’s 99% metric means the program utilizes 99% of a single CPU core.
A quick primer on threads, if you will: a single thread can only be scheduled for execution on a single processor core at a time, meaning as long as you’re not spawning multiple threads, CPU usage could only amount to a single core.
Conversely, because we are using Python, I have lied to your face. To regain your trust, I’ll explain why: due to Python’s Global Interpreter Lock, true parallelism will never happen in a Python process, as a single interpreter can only be controlled by a single thread at a time. Even if we used multiple threads, they would never be executed concurrently. This is what makes the difference between the following cases:
"""
Tight loop in two separate threads/processes.
"""
from multiprocessing import Process
from threading import Thread
def do_work():
_ = 1 + 1
def problem():
while True:
do_work()
def spawn(items):
for item in items:
item.start()
for item in items:
item.join()
def spawn_threads():
spawn([Thread(target=problem) for _ in range(2)])
def spawn_processes():
spawn([Process(target=problem) for _ in range(2)])
docker run --rm --name cpu-hogging -it vladpbr/cpu-hogging:python -c "from samples.tight_loop_concurrent import spawn_threads; spawn_threads()"

docker run --rm --name cpu-hogging -it vladpbr/cpu-hogging:python -c "from samples.tight_loop_concurrent import spawn_processes; spawn_processes()"

In hopes of further redeeming myself, here are two threads in Golang:
package main
func do_work() {
for true {}
}
func main() {
go do_work()
do_work()
}
docker run --rm --name cpu-hogging -it vladpbr/cpu-hogging:golang run samples/tight_loop.go

The conclusion is that our process receives all the CPU time it can get its greedy hands on. Looking at the code, it’s obvious — our program does pure computational work without ever sleeping or waiting for I/O. This is called a tight loop —“a loop of code that executes without releasing any resources to other programs or the operating system.” However, as is also true with people, having a title does not make them any better.
Look, I’m not saying these loops are always bad — they are inherently CPU-cache friendly and are widely used in video game rendering. What I am saying is that you should consider the following solution:
def solution():
import time
while True:
do_work()
time.sleep(0.001)
docker run --rm --name cpu-hogging -it vladpbr/cpu-hogging:python -c "from samples.tight_loop import solution; solution()"

Simply adding a sleep time of one millisecond in between loop iterations fixes the issue. You’ve got to ask yourself — do you really need to poll for anything more often than that?
Busy waits
Let’s talk about why the time.sleep solution works and why the following snippet does not:
"""
Loop which uses a custom `sleep` function.
"""
from datetime import datetime, timedelta
def do_work():
_ = 1 + 1
def sleep(seconds: float):
end_time = datetime.now() + timedelta(seconds=seconds)
while datetime.now() < end_time:
pass
def problem():
while True:
do_work()
sleep(0.001)
We have implemented our own sleep function, which calculates the exact time it needs to “sleep” and then sits in a loop until the time has passed. Here is how it performs:
docker run --rm --name cpu-hogging -it vladpbr/cpu-hogging:python -c "from samples.busy_wait import problem; problem()"

If it wasn’t immediately obvious, our custom sleep function is effectively a tight loop in and of itself. This is what’s called a busy wait — a loop that does not let code advance until a condition is met. So what does the time.sleep function do any different that makes it all work?
Time to do that thing you dread doing. Let’s read some documentation:

This is different from busy waiting — time.sleep notifies the operating system that our thread is inactive. Here is a snippet from the Wikipedia article on the “sleep” system call:
A computer program (process, task, or thread) may sleep, which places it into an inactive state for a period of time. Eventually the expiration of an interval timer, or the receipt of a signal or interrupt causes the program to resume execution.
We need to notify the operating system about our sleeping process because it excludes our thread from being scheduled for execution. As long as our thread is not being scheduled, it does not receive any CPU time. This time can then be allocated to other processes that need it.
Other ways of releasing resources
So, the core issue here is that greedy processes need to release resources for others to use. Sleeping is one way of doing so, but there are others.
Your do_work might need to interact with local files or remote servers, asking the underlying operating system to perform these actions. This does not happen instantaneously, as the operating system must coordinate these actions with the actual machine hardware.
Reading from a hard drive, for example, requires the hard disk itself to move its reader-writer head to the appropriate position and read the bits off of the plates. Until the action is performed, your thread can not progress and, therefore, will not be scheduled.
Do not simply trust me on my word this time; instead, let the behavior of the following snippet convince you:
def do_disk_io_work():
result = 1 + 1
with open("temp.txt", "w") as _file:
_file.write(str(result))
def disk_io():
while True:
do_disk_io_work()
docker run --rm --name cpu-hogging -it vladpbr/cpu-hogging:python -c "from samples.tight_loop import disk_io; disk_io()"

The same goes for network I/O, as you can tell:
def do_network_io_work():
import http.client
client = http.client.HTTPSConnection("google.com")
client.request("GET", "/")
client.getresponse()
def network_io():
while True:
do_network_io_work()
docker run --rm --name cpu-hogging -it vladpbr/cpu-hogging:python -c "from samples.tight_loop import network_io; network_io()"

What’s funky about these examples is that their behavior will differ on your system, as it depends greatly on your hardware and physical location. Your hard drive might be faster than mine, performing write operations within a smaller time frame, leading to less time for I/O operations. Similarly, if you are geographically closer to Google servers than me (and you probably are), the response will arrive faster, leading to less time spent in a waiting state.


To state the obvious, this is not a complete solution. You might be tempted to leave this code as-is since it does not guzzle CPU time as much, but the underlying issue is still there. Just because the loop is “looser” does not mean it can not be improved upon.
Avoiding CPU hogging in other common scenarios
When using queues, you might be tempted to do the following:
"""
Waiting for results from a queue.
"""
from time import sleep
from threading import Thread
from queue import Queue
from random import choice
queue = Queue(maxsize=1)
def producer_thread():
while True:
queue.put(choice(["apple", "banana", "cherry"]))
sleep(1)
def problem():
Thread(target=producer_thread).start()
while True:
if not queue.empty():
print(queue.get())
As long as there are no items in our queue, we’ve got ourselves a tight loop that looks like this:
docker run --rm --name cpu-hogging -it vladpbr/cpu-hogging:python -c "from samples.queue import problem; problem()"

Queues have a mechanism for that — by default, get() is a blocking call, meaning it will not return until an item is added to the queue. The underlying item arrival notification mechanism is based on locks and does not waste precious CPU time.
As a matter of fact, any self-respecting, god-fearing data structure will handle our use case and not bother the processor when it is not actually required. If you encounter a problem with another data structure, take a deep breath and consult the relevant documentation.
Stage 2: Bargaining (What You Shouldn’t Do)
At this point, you could argue that the issue is that a process is using too many resources and should be throttled. I’m a relatively reasonable person, so I will show you how it can be done, and only then will I dunk on it.
You can always set a hard limit on how much CPU a process can use. Such solutions usually do not come built-in, but external ones do exist — BES for Windows and cpulimit for Linux, to name a few. Docker comes with the ability to set a precise CPU limit for any container via cgroups:
docker run --cpus 0.5 --rm --name cpu-hogging -it vladpbr/cpu-hogging:python -c "from samples.tight_loop import problem; problem()"

Two problems with this “solution”:
- The core issue still needs to be resolved. Congratulations, your code still smells, and the thread running it will also be scheduled at inconsistent times.
- You are using an inherently infrastructural mechanism to solve an application-level problem. Hard limits are meant to act as safeguards, not solutions.
Stage 3: Acceptance (Legitimate CPU-Related Issues)
We now agree that the code is at fault here. Some of it can be refactored to release resources once in a while, but there are scenarios when your code really is optimized, yet there isn’t enough CPU time to go around for everyone else. If that is the case, you may avoid leveraging scheduling priority in your favor.
Modern operating systems implement advanced CPU scheduling algorithms that consider how important the process is relative to other existing processes when deciding on who gets the execution time. This importance is based on process priority — an integer value given to a process during its creation, which can also be changed at runtime.
You could argue that, similarly to setting a hard CPU limit, this is a function of infrastructure and, therefore, can not be a viable application-level solution. I disagree. We’re talking about a specific use case where the infrastructure is at “fault,” so to say, for not having enough resources. When push comes to shove, application developers are the only people who can decide on their processes’ importance and priority.
Process priority in practice
Let’s say our tight loop sample does actual work. Assuming you are using Linux, here is how you launch a process with custom priority (in Linux, priority values range between 19 and -20, where the value is lower priority and the default is 0):
nice -n 15 python3.11 -c "from samples.tight_loop import problem; problem()" &

Let’s see how it performs:
top -p 34376

It seems like the priority setting did not help because our machine had unused cores to give to all the processes, including ours.
top

This superuser.com response has put it quite elegantly:
Suppose you have a “go to the head of the line” card for the grocery store. You go to the store, fill your cart, go to the checkout counters, and find there’s no one in line. Does your card help you get checked out faster? Nope.
Priorities don’t affect processing speed, in that a higher priority process doesn’t get to run faster or even to use more CPU time… not if it’s the only thing that wants to use the CPU.
Do not forget to game-end our rogue process with this code:
kill -9 34376
Process priority in a CPU-limited environment
As we’ve stated above, the problem resides in environments that do not have enough processing time to go around. Therefore, we need an environment where CPU time is scarce to see this behavior in action and show how process priority can mitigate the issue. For this purpose, I have gone out of my way to spin up a single-core TinyCore virtual machine (as I was too lazy to download another heavy Linux distro) using VirtualBox:
Perhaps a bit out of scope for this article, but here is how you get Python and the relevant code in TinyCore:
tce-load -wi python3.9 git
git clone https://github.com/vlad-pbr/cpu-hogging.git
cd cpu-hogging
- TinyCore comes with its own package management tools, which can be used to install prepackaged software via tce-load
- As of writing, the highest Python version available in official TinyCore package repositories is 3.9
- TinyCore also does not come with ssh installed, so https cloning will do
For starters, let’s see how two tight loops behave when being executed with the same priority:
python3.9 -c "from samples.tight_loop import problem; problem()" &
python3.9 -c "from samples.tight_loop import problem; problem()" &
top
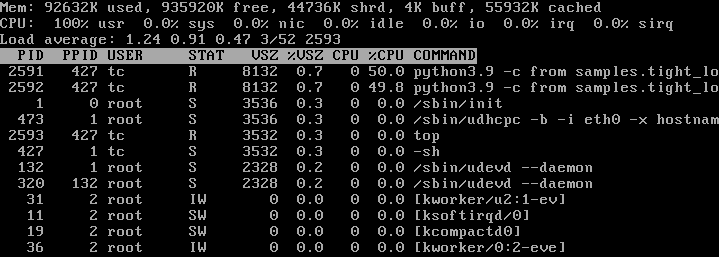
Now, let’s lower the priority for one of our tight loops:
renice -n 5 2591
top

Priority matters when there isn’t enough CPU time to spare. If adding more resources to your environment is not an option, prioritizing more important processes can be.
kill -9 2592 2591
Conclusion
As far as the main topic is concerned, case closed. But, in truth, an additional goal of this article was to widen your scope when it comes to such infrastructural issues. To investigate the whole CPU time shebang, we happened to do a whole bunch of other things:
- Gave names to bad coding practices
- Brushed up on Python concurrency
- Delved into process scheduling mechanics
- Ran Docker containers and viewed their statistics
- Learned quite a bit about Linux and some common bash commands
- Booted an entire virtual machine and simulated a lack of CPU time!?
As much as we like to separate infrastructure from the application (judging by the memes), IT is inescapably interconnected. Knowing the works of your underlying infrastructure lets you write better code, making you a better programmer. Knowing the nitpicks of programming makes you a somewhat less angry system administrator.
Finally, talking about a wide range of topics is way more fun than something super specific and close-ended. I mean, do you really, truly learn something by reading an article that only shows cause and effect? Neither do I.
Three Stages Of CPU Usage Grief was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.