The most modern mechanism for shifting your data from one cloud to another for analytics and insights might be to not move it at all

The facts of data analytics
If you’ve been following the trends around data and analytics for a few years now, you’ve probably come across one or more BI or data maturity curve graphs. You know the ones — they start with the least mature organisation dealing with static BI reports and being ‘reactive,’ and gradually ‘maturing’ towards proactive insights and a data-driven culture.
One moment, let’s see if I can find one.
(A few seconds of Google later…)
Ah, here we go!
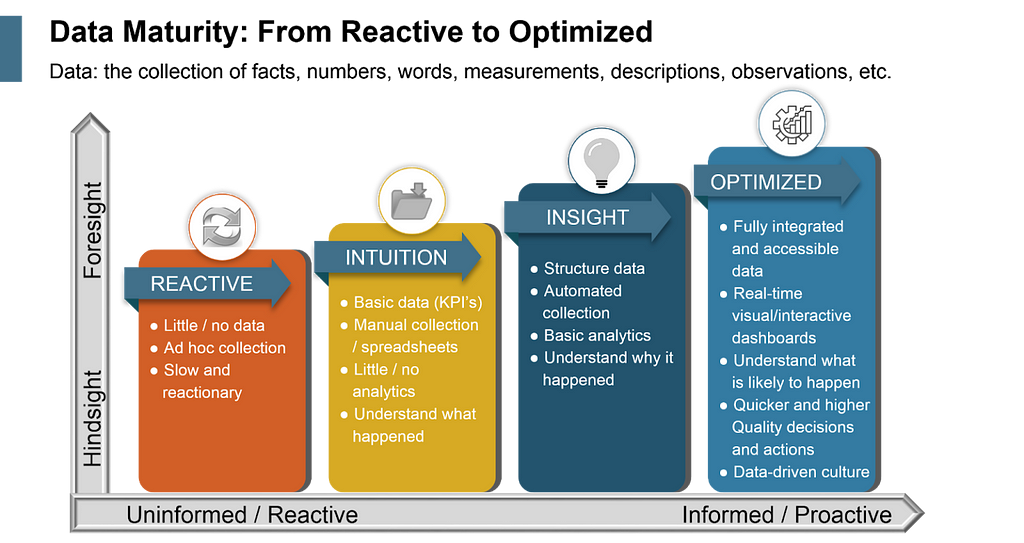
There are plenty of variations on this theme of maturity, but they all share a common thread of moving from bits of data siloed all over the place towards a fully accessible and well-formed data warehouse or lake. Here, the data from all over your landscape is brought together and surfaced in a way that makes gathering insights simple and effective.
Of course, achieving this data nirvana requires a lot of work. You need the infrastructure set up for your data lake for one thing, and to get the data into that lake, you need a potentially dizzying array of data pipelines, ETL tools, and enterprise connections to gather data from ERP systems, cross-cloud, on-premises and more. Then you need the people — the engineers — to do the following:
- build, maintain, and enhance your data ingestion setup
- create the right level of observability to detect failure and maintain quality as the data moves from the source system to its final resting place in your data lake.
This is particularly complex if you are, like most organisations, operating in more than one public cloud today.
It’s all doable, of course, but it’s a lot of work to do one thing well — move data from a source system to a target lake/warehouse so you can run analysis on it. And now it’s time for that most clichéd of lines…
But what if there was another way?
BigQuery OMNI
Enter the concept of BigQuery OMNI. For those who don’t spend much time tinkering with GCP (Google Cloud Platform), you might not have heard of BigQuery before. It’s Google’s completely managed, serverless, and fancy data warehousing solution. BigQuery allows you to run petabyte scale queries — including built-in machine learning — across your data.
As a product on its own, BigQuery has a lot of interesting and useful features for the budding data engineer (I wrote a while back on using BigQuery ML to predict the risk of heart disease if you’re interested), but in 2021, a feature was released to the public that would change the way you could work with data across public clouds in BigQuery; BigQuery OMNI.
Imagine you have juicy data sitting in an S3 storage bucket in your AWS account, but your data warehouse uses BigQuery in GCP. The first instinct might be to don your armor, smear your face with warpaint (Data Engineers use warpaint, right?), and go into battle with data pipelines, VPNs, or bucket syncing to get that data into BigQuery where it’s needed.
BigQuery OMNI allows you to leave that data sitting right where it is — in AWS S3 (or other places) — and instead query it in place from your GCP account.
That’s right, BigQuery OMNI seeks to reduce the complexity of moving data around for analytics by taking the ‘movement’ out of the equation.
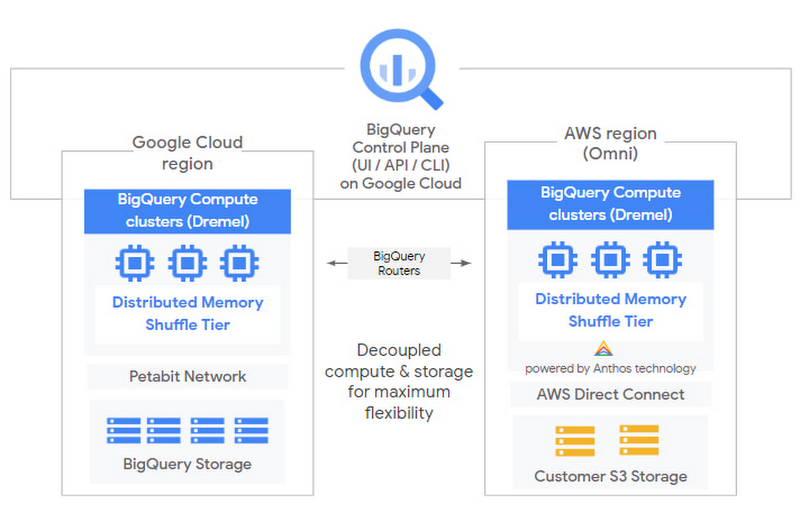
This concept can potentially eliminate much of the infrastructure and logic required to pipeline that data from AWS to GCP. Sounds incredible on paper, right? But it’s only useful if it’s easy to set up and maintain, does the job as advertised, and allows meaningful data analysis while leaving your source data right where it is.
So, let’s take BigQuery OMNI out for a test drive and bring you along for the ride, shall we?
The setup
To follow along at home, you’ll need access to the following:
- An AWS account that permits you to set up AWS S3 and IAM permissions.
- A GCP account and project that you can set up or operate using a BigQuery solution.
AWS steps
Let’s start our setup in AWS land!
For our test scenario, we will grab a dataset from www.kaggle.com that contains around 20,000 chess games — a mixture of ranked and non-ranked — and store those in an AWS S3 bucket.

We’ve created a simple S3 bucket called my-chess-data and uploaded our games.csv.
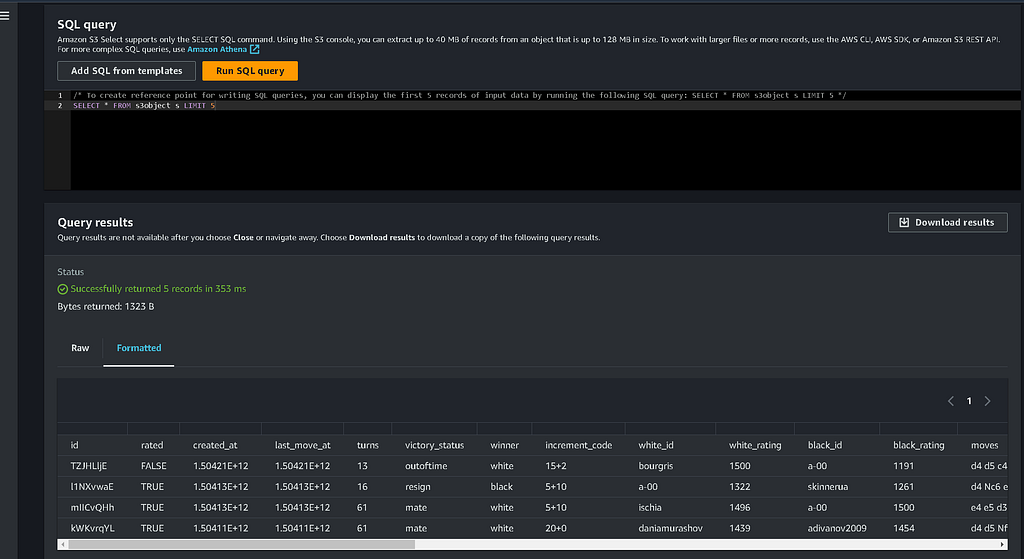
Before we go further, it’s probably worth a quick spot-check to make sure our source data looks OK. I forgot to do this with the CSV on my laptop, but thankfully, I can query the data directly in the S3 bucket using a lesser-known feature of S3 called ‘S3 Select.’
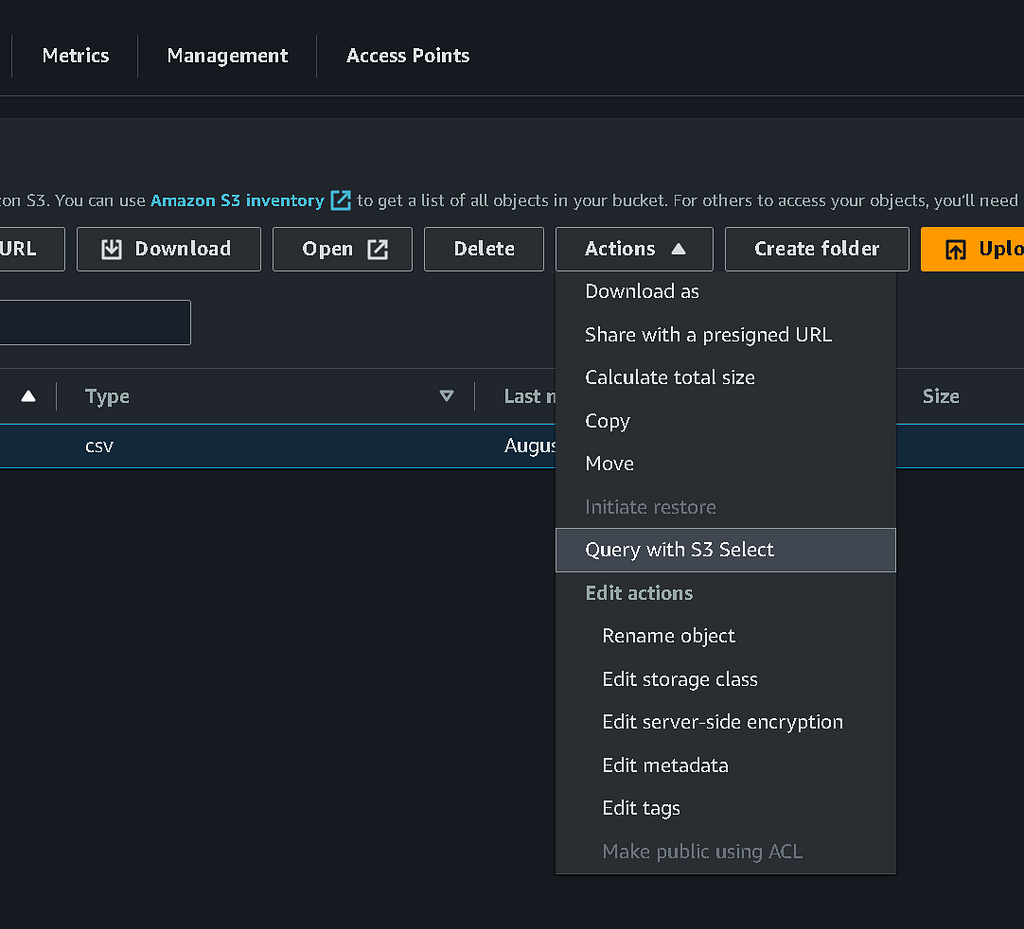
This feature lets you query your CSV or JSON data with SQL-like queries directly from the bucket! I’m no chess expert, but this data does look pretty good. A list of chess games (including the winner and loser), moves, opening gambits, etc.
Now that we have our data, we’ll need to create an IAM role and policy that we can use to give the required permissions to access and work with the data in our bucket. Head over to the IAM console and create a new policy.
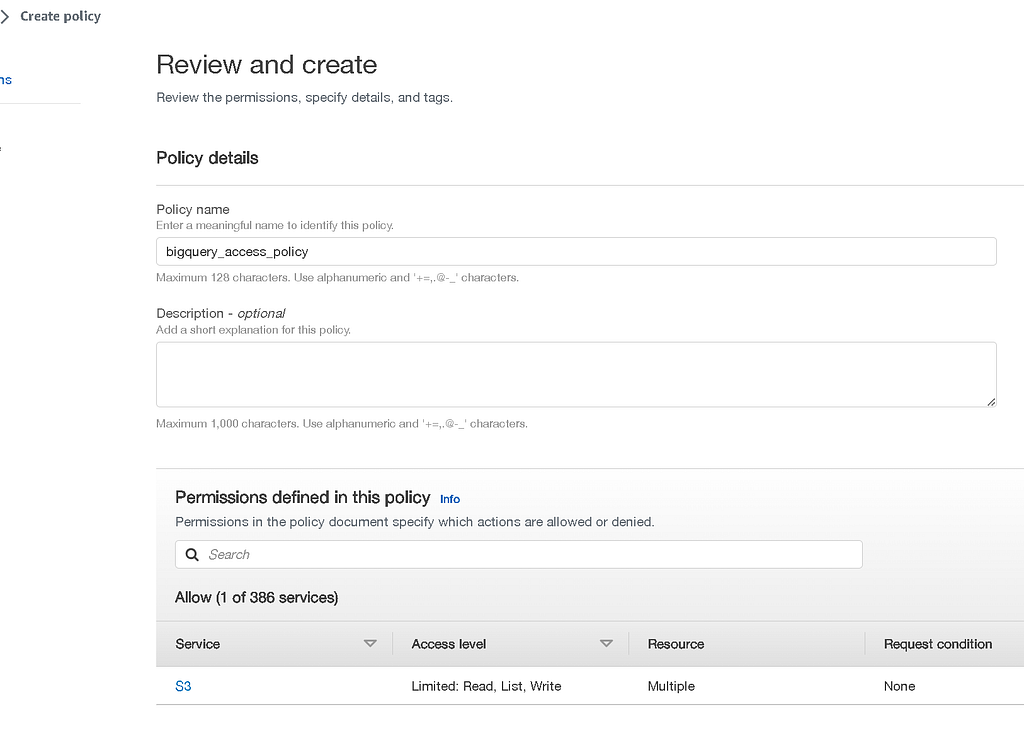
This policy will allow working with the bucket and data in question. For your convenience, here’s a pre-written policy you can attach to your IAM role:
{
"Statement": [
{
"Action": [
"s3:ListBucket"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::my-chess-data"
],
"Sid": "BucketLevelAccess"
},
{
"Action": [
"s3:GetObject"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::my-chess-data",
"arn:aws:s3:::my-chess-data/*"
],
"Sid": "ObjectLevelGetAccess"
},
{
"Action": [
"s3:PutObject"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::my-chess-data",
"arn:aws:s3:::my-chess-data/*"
],
"Sid": "ObjectLevelPutAccess"
}
],
"Version": "2012-10-17"
}
Now, create a new IAM role and attach our policy to it. Here’s what that looks like:
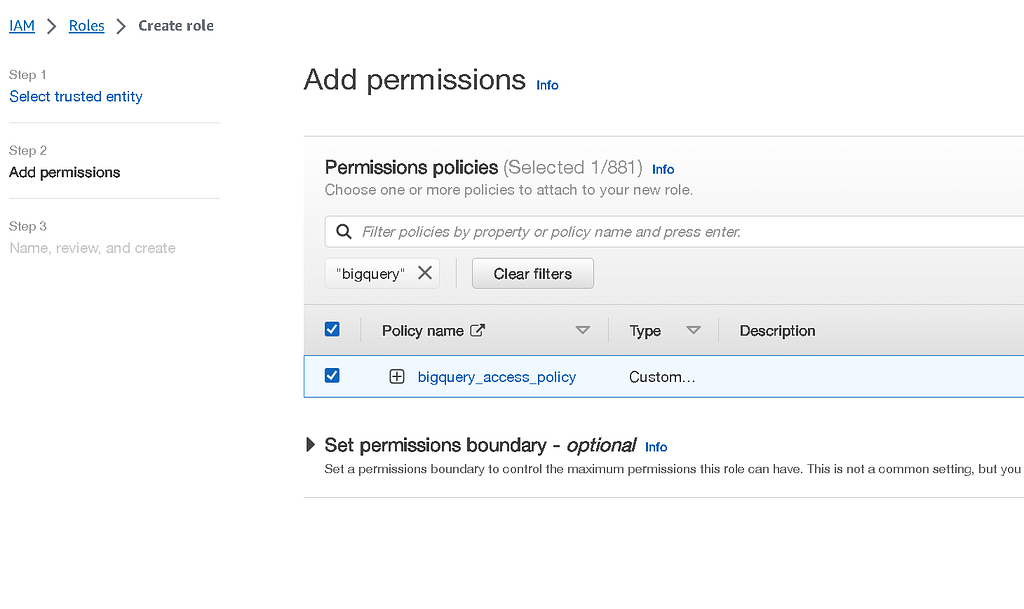
With your role created, take a note/copy of the role ARN before proceeding.
arn:aws:iam::xxxxxxxxxxxx:role/role_bigquery_access
Let’s jump from cloud to cloud and head over to GCP with that out of the way.
Google Cloud Platform steps
Our next steps assume you already have BigQuery set up in a GCP project. Doing that initial setup is outside the scope of this article, but there are many good starter guides in the official Google documentation.
In your project, open up the BigQuery SQL workspace and locate the option to add a connection to an external data source (you may be prompted — and should say yes — to the dialog asking you to enable the BigQuery Connection API).
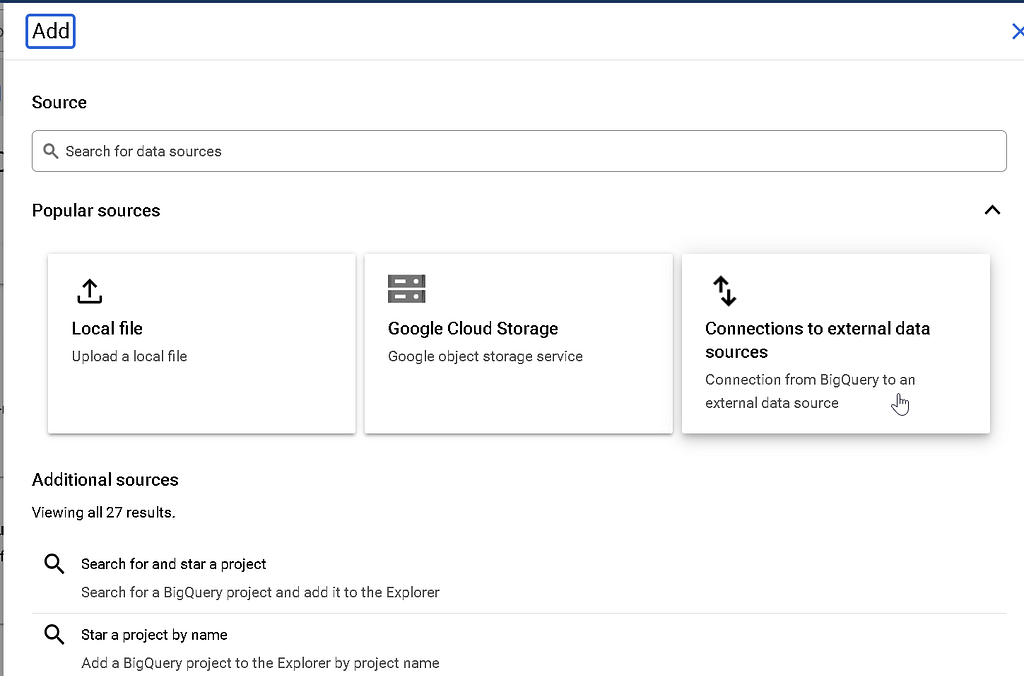
You should select the ‘BigLake on AWS (via BigQuery OMNI)’ option and be prompted to fill out some information, including the IAM role you previously created in AWS. Your finished options should look similar to the ones below:
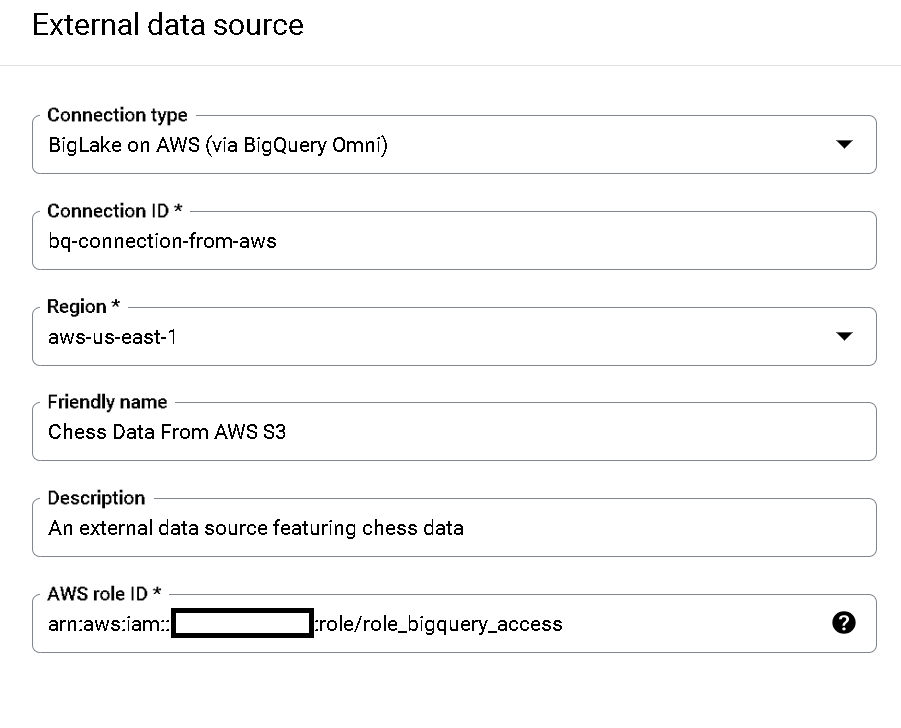
Once the connection is created, you should see it in your BigQuery project as an external data connection:

In the connection details, you should note a BigQuery Google Identity. Note this value down somewhere. We will use this back in our AWS account to establish the trust relationship between the two clouds to allow BigQuery OMNI to work.
And back to AWS…
Once we’re back in AWS, locate the IAM role you made in the IAM console and edit the ‘Trust Relationship’ tab.
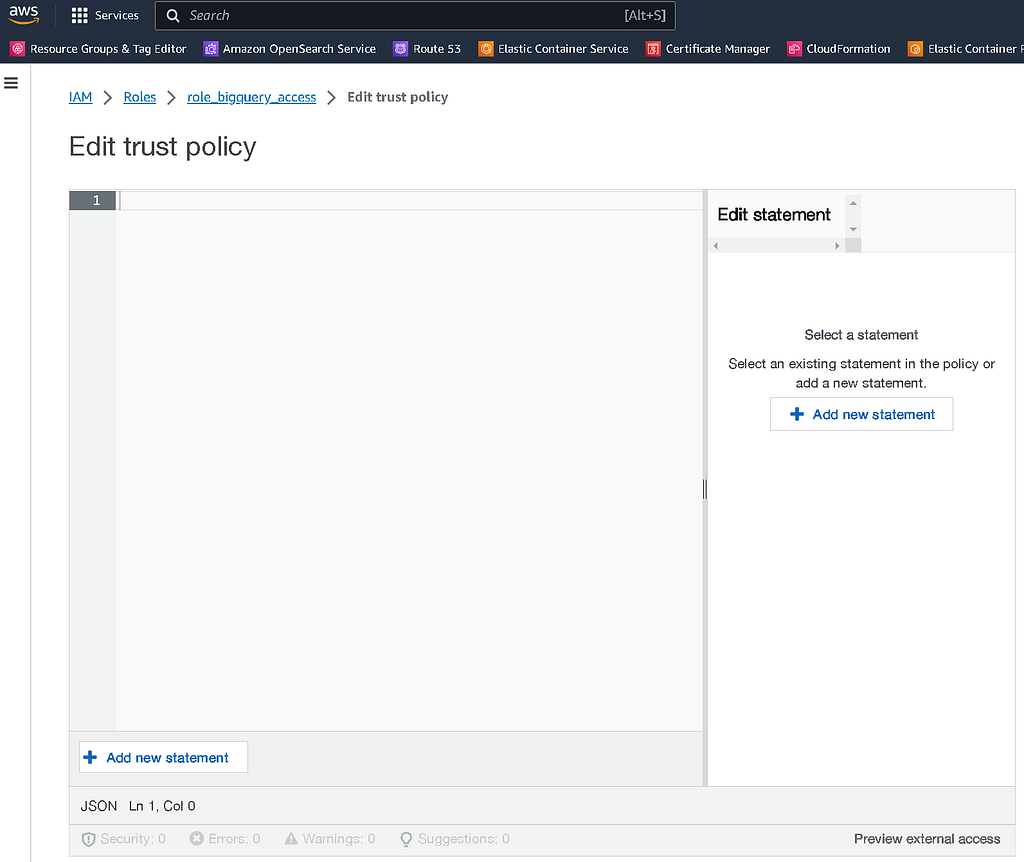
In here, we’re going to add a trust policy to allow the BigQuery Google identity to access and assume this role. Add a trust policy similar to the below JSON, but replace the x’s with your BigQuery Google identity number.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "accounts.google.com"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"accounts.google.com:sub": "xxxxxxxxxxx"
}
}
}
]
}
Save that change, and pat yourself on the back. You’ve just made AWS and GCP trust each other, at least so far as this experiment is concerned. Now, it’s back to BigQuery to test out our connection.
Time to select some data
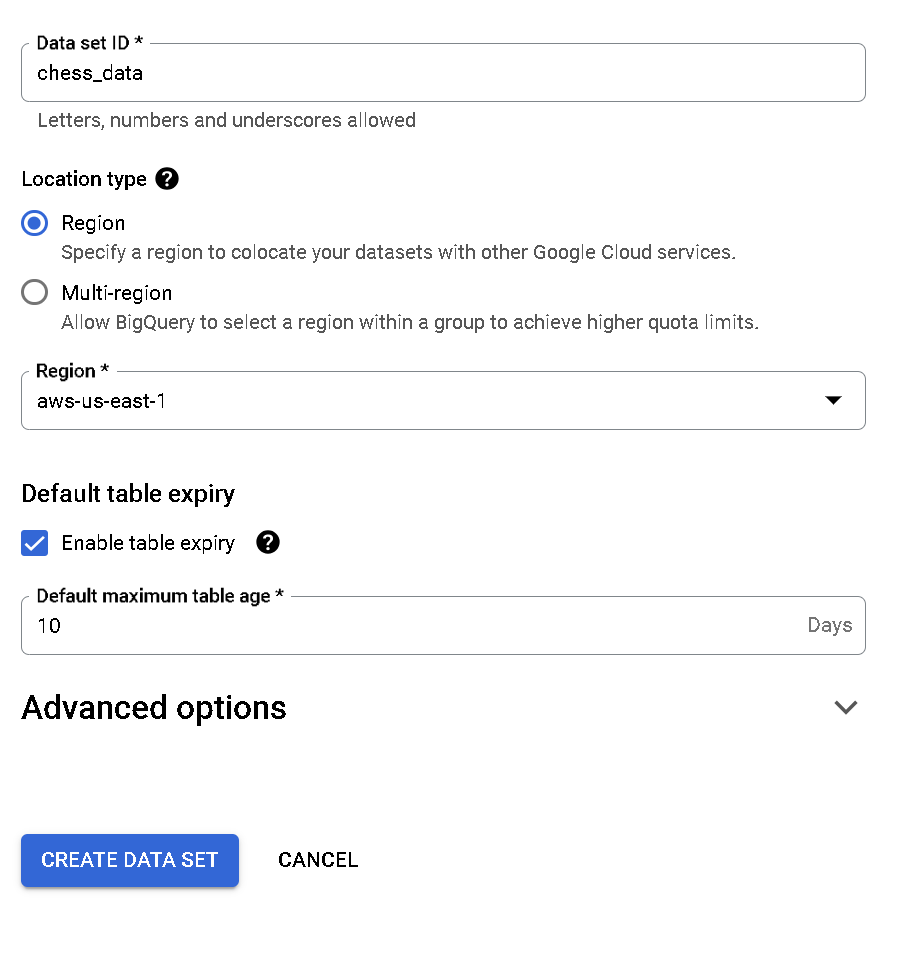
Before we can get into our chess data, we need to create a bit of a ‘container’ in BigQuery for our table to reside. In BigQuery, create a new data set with settings similar to the one below. I’ve set this one to expire in ten days because I’m all about cleaning up after myself, but you don’t have to.
Now, create a table attached to your data set — and it’s here that the magic will happen. Choose to create a table from ‘Amazon S3’:
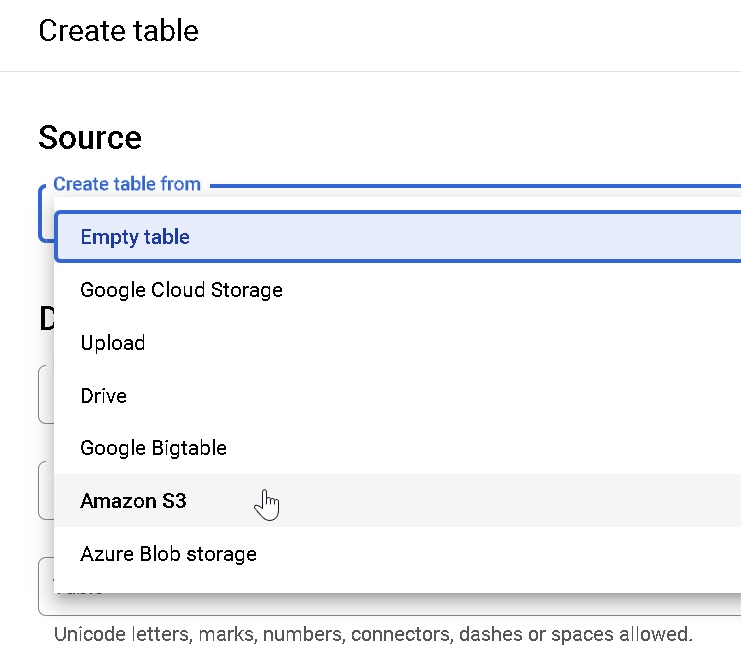
For the path, select the full path of your chess CSV in Amazon S3, and fill out the rest of the options similar to the one below (including auto-detect for schema and selecting your BigQuery external connection).
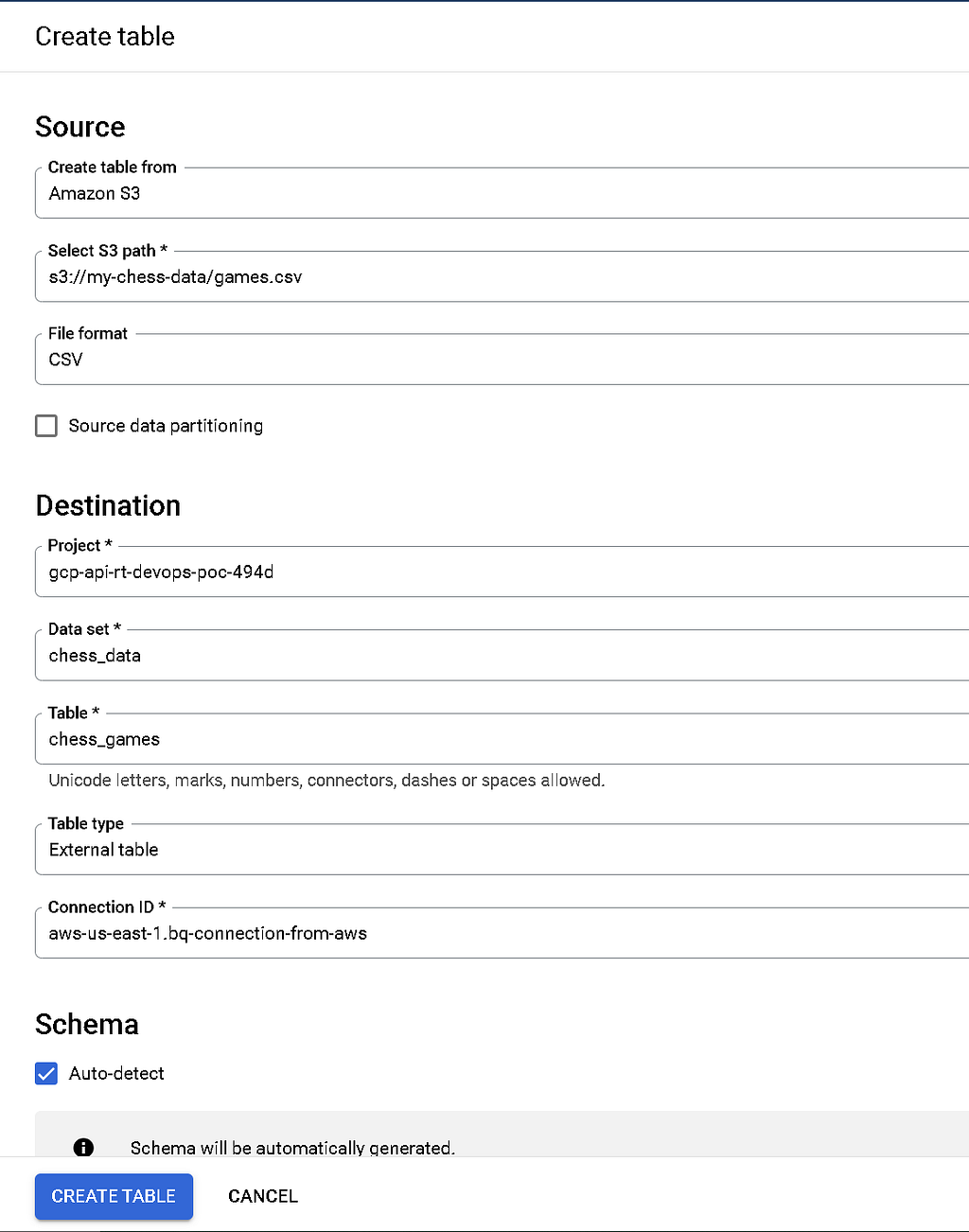
Click create, and — uh oh, an error!?
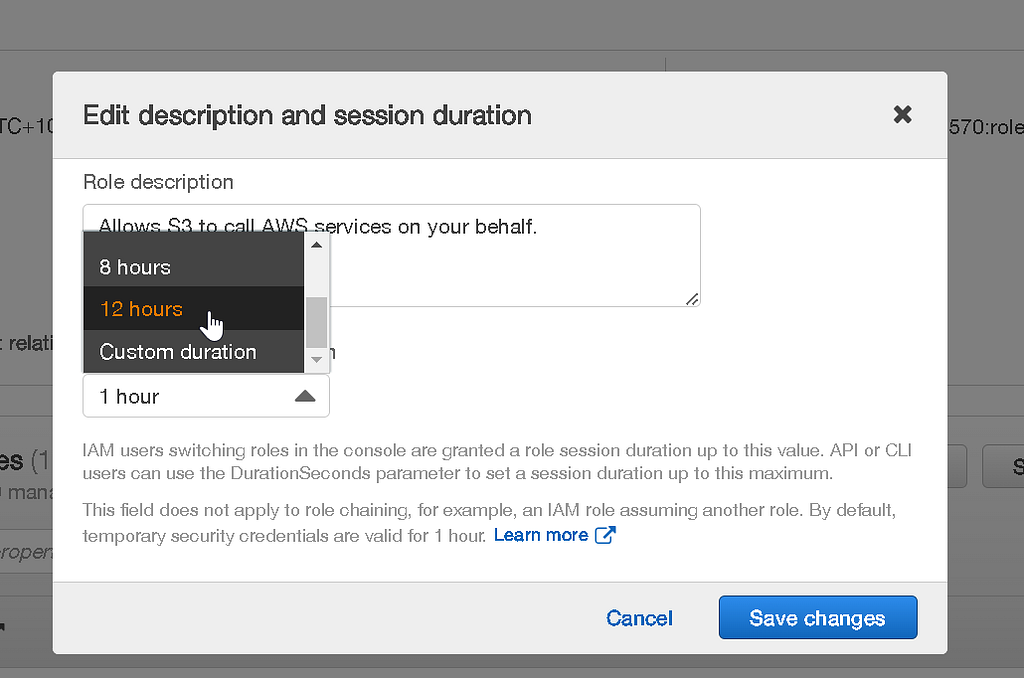
Failed to create table: Connection projects/xxxxxxxxxxxx/locations/aws-us-east-1/connections/bq-connection-from-aws failed assuming into your AWS IAM role because the session duration of your IAM Role is smaller than the requested session duration. Please edit your AWS IAM Role settings to increase session duration to 12 hours
This occurs because the default session duration for an IAM role is far shorter than 12 hours. Head back into AWS, bring up your IAM role in the IAM console, and edit it to extend the session duration to 12 hours:
Okay, with that done, our table is now created successfully, and we can move on to testing out a select query that reaches out across the gulf between clouds! It’s the moment of truth and triumph, so get your virtual drum rolls ready!
Run a query like the following on your newly created table:
SELECT * FROM `<project_id>.chess_data.chess_games`
Huzzah! We have data!
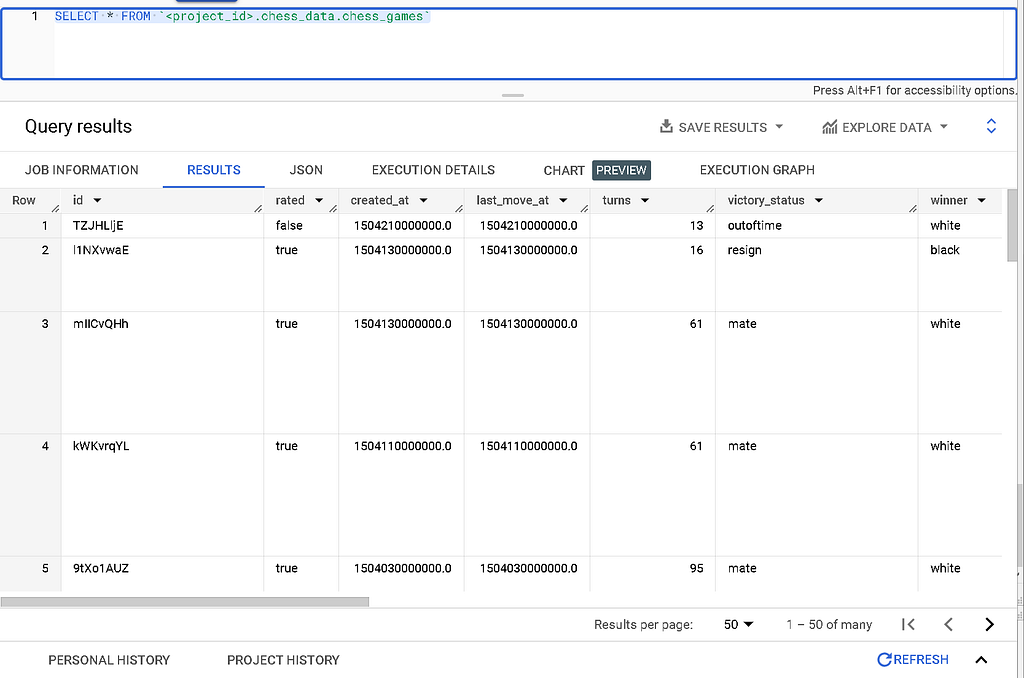
We’ve successfully been able to bridge the data gap between our source data and our data warehouse without having to move the source data from its resting place, thanks to establishing a secure trust relationship and external table using BigQuery OMNI. Very satisfying for all the data nerds out there (that includes me!).
But the story isn’t over, not just yet. By leveraging the connector we created as part of our BigQuery OMN, we can write our query results back to our source S3 bucket (useful for triggering actions or events in your source system based on analytics results from BigQuery).
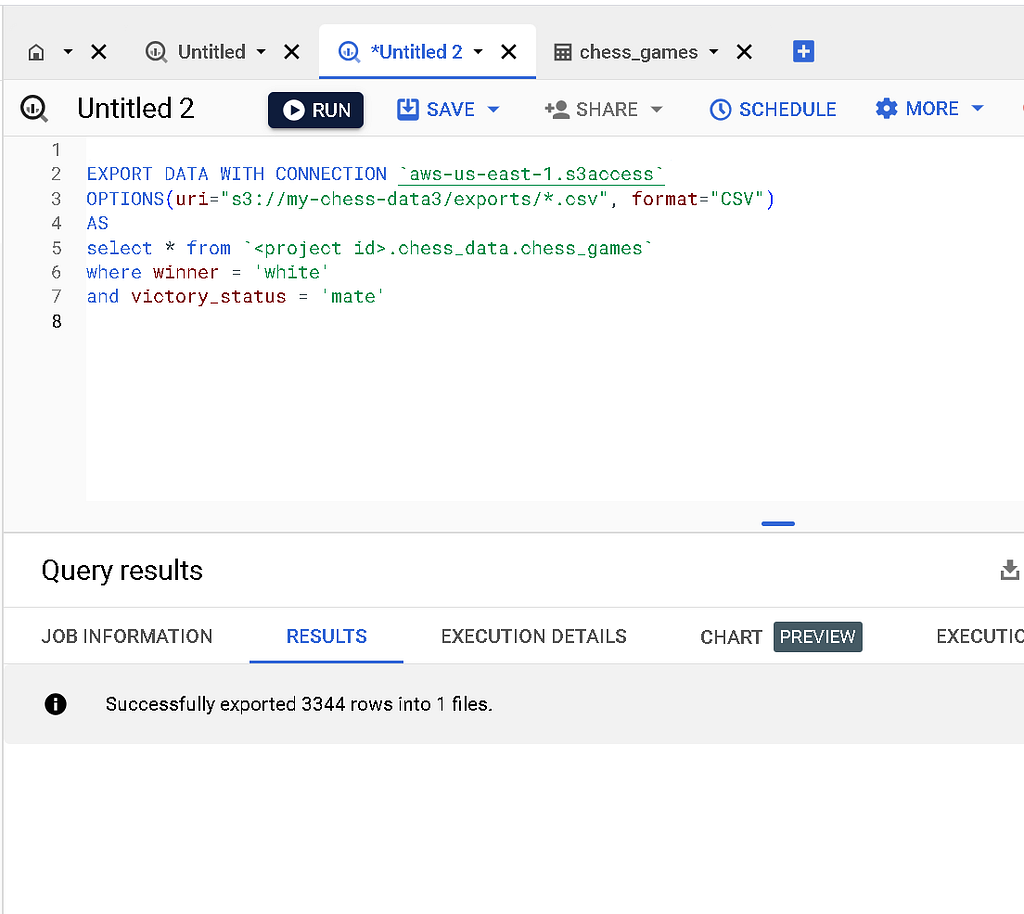
Create the following EXPORT DATA query in your BigQuery window, substituting your project id, connector id, etc. In the below example, I’ve decided to export only chess matches where the winner was white and it was a checkmate. (Make sure to keep the *wildcard in your URI; the export function won’t allow you to make the filename completely static).
EXPORT DATA WITH CONNECTION `aws-us-east-1.s3access`
OPTIONS(uri="s3://my-chess-data3/exports/*.csv", format="CSV")
AS
select * from `<project id>.chess_data.chess_games`
where winner = 'white'
and victory_status = 'mate'
Run the command, and BigQuery should report the number of rows exported:
Let’s check in on our S3 bucket in AWS. Here’s what that looks like:
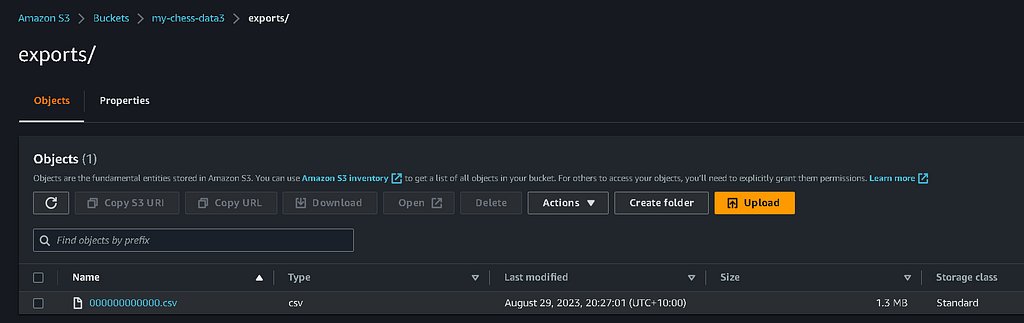
Like that, we now have our exported query results back into AWS for use with an event-driven architecture as simply triggering an event on object put. Brilliant!
A quick spot check of our CSV reveals that we’ve got exactly the data we want (though granted, it has no column names. I think that’s an oversight on my export command — but hey, it gives you something to improve on — right?).
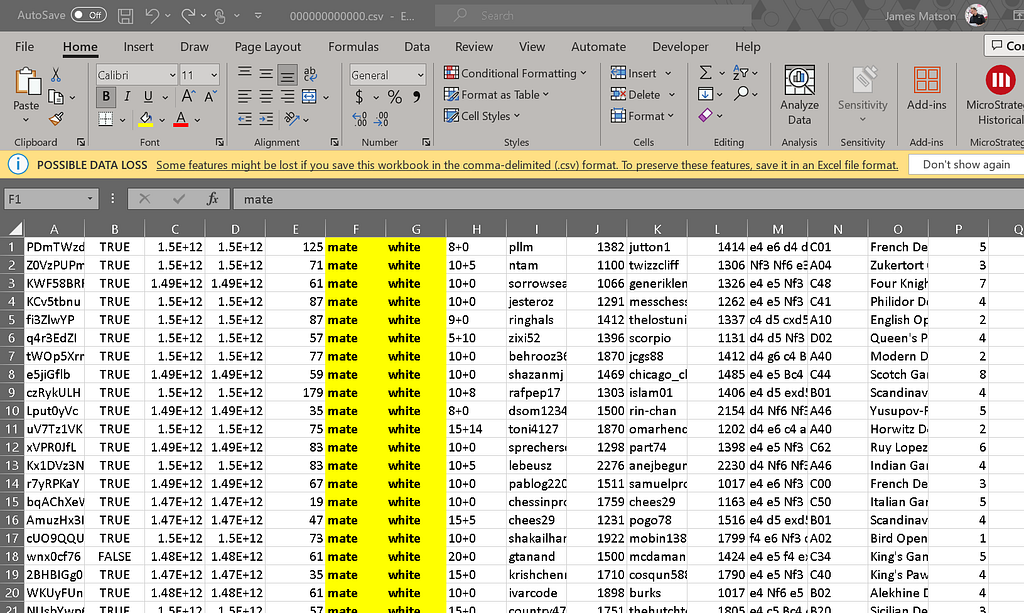
So there we have it. With just a little configuration in your source and destination, BigQuery OMNI provides an excellent pattern for in-place analytics on source data. There’s much more to consider here, like how to operationalise this setup and practices you’d want to adopt at the scale of hundreds or thousands of data sources. Still, there’s no denying that BigQuery OMNI provides a compelling starting point.
If you’ve made it this far — thank you for sticking with me!
Using Google BigQuery OMNI to Query Data In-place From AWS S3 was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.