
Yesterday, I had a small session on Medium Day, where I briefly talked about developing applications that use large language models.
I wanted to do a short follow-up today and write up all the talk’s content as an article as well — primarily for people who did not have the chance to attend the event.
High-Level Overview
Let’s start with a very high-level overview. When you decide to build something with large language models, your use case is the first thing to decide. There are different things you can do with these models, so it’s essential that you first decide on the high-level picture of what you’re trying to build.
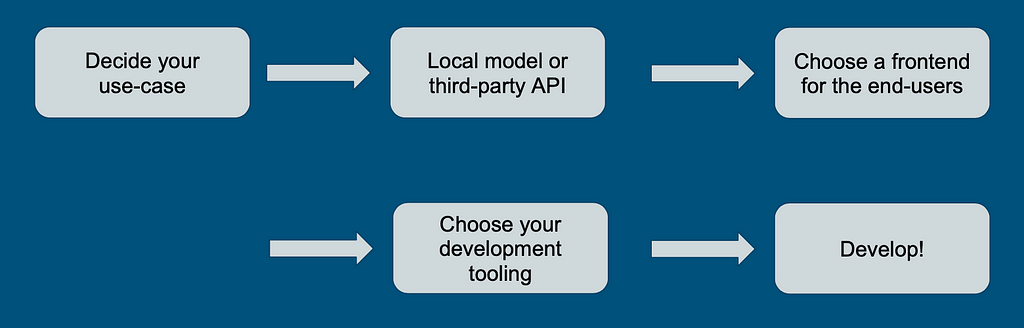
We will explore these topics and close with an example stack for one of the use cases.
Decide Your Use Case
Here are a few use cases we could think of where you could apply a large language model:
- Chatbots
- Code generation
- Game content generation
- AI agents (highly experimental)
- Natural language processing tooling
- Others
Let’s briefly check a typical scenario and expected challenges for each use case.
Chatbots
Typically, chatbots are useful for answering questions or providing automation for the user. There’s also a huge potential for tutoring and learning applications, such as language learning bots.
The main challenge you will face is the embeddings’ methods and limitations. Building a good question-and-answer bot requires a good understanding of how embeddings work, which model to use, how to store the data into vectors, which distance function to use, etc.
Expect a decent amount of time studying and understanding this topic if you plan to build chatbots.
Code generation
Everyone knows about GitHub Copilot these days. There are many emerging code-generation providers. One that is quite interesting, for instance, is codeium. I’ve also developed a small PoC plugin that generates docstrings, and it’s not hard to get interesting results.
This field has a tremendous potential to grow considerably in the upcoming years.
Some challenges you’ll face are syntax errors generated by the model and the complexity of integrating the functionality into your integrated development environment.
Game Content Generation
This is still a somewhat unexplored topic, and people are starting to experiment with it. However, some groups have a huge expectation of what will be possible for entertainment using language models. Some people use LLMs to create stories dynamically, but it’s also possible to integrate multimodality and generate other types of assets through image generation models, such as Stable Diffusion.
Some challenges:
- Ensuring high-quality content
- Be careful with potential copyright issues
- Multi-modality: image generation (stable diffusion)
AI agents
We’ve seen recently tools such as AutoGPT emerging. There are many examples and attempts with varying degrees of success. One thing is clear: language models greatly decrease the entry barrier to coding an AI agent and will only become more common with time. Do not expect to build a general artificial intelligence or some super-human type that will do all your work for you, at least not overnight. It’s a difficult topic with some promising initiatives but nothing too great yet.
If you focus on more strict, simpler use cases, you should achieve higher success. For instance, an achievable use case is setting up automation flows, for instance, generating and sending unique cold marketing emails for each user.
Natural language processing
If you work with more traditional natural language processing, you can benefit from large language models in a few ways. You can use zero-shot classification when your model is not trained on example labels or generate synthetic data to train an actual model. There are also attempts to use instruct models such as GPT-4 to label a dataset automatically.
Decide Your Approach: Local or Third Party
So once you have a use case, the next step is to decide which model you’re using. You must decide between two approaches: do you want to use an API or host the model yourself instead? Let’s see the third-party API option first.
Third-party API
This is the easiest and cheapest option. In turn, the two downsides are a lack of control over model changes. For instance, OpenAI deprecates model versions every six months, and you can never be 100% sure regarding data privacy. Some popular options are OpenAI (GPT-3.5, GPT-4) and Claude.
Local
If, for some reason, using a ready API is not feasible, hosting your models locally is your next option. This is especially relevant when you need data privacy or strict control over how the model changes over time. As a downside, you add significant infrastructure and development costs.
When developing locally, it’s also good to know that the best models were usually based on LLaMA and now on LLaMA-2, although not all models are commercially usable (especially LLaMA 1 models).
It’s also very important to familiarize yourself with different quantizations methods. Quantization is the process of decreasing the precision of the pre-trained weights of a model. Instead of using 16 bits, you can reduce it to 8 or even 4 bits while maintaining almost the same model performance.
It’s also important to familiarize yourself with different libraries that help you load a model in memory:
- Transformers
- Bitsandbytes (8- and 4-bit quantization)
- GPTQ (4-bit quantization)
- ExLlama (for GPTQ 4-bit quantization)
- GGML (efficient CPU implementation)
The library Transformers from HuggingFace is the bread and butter to work with large language models. It should be your first starting point when hosting your models. If you don’t have a GPU, look at GGML models, which you can download from the HuggingFace repository. And if you need to push some extra boundaries on VRAM constraints, ExLlama offers a memory-efficient implementation for consumer hardware, such as RTX-3090/4090 GPU cards.
As for hosting options, you can try managed services such as Hugging Face inference endpoint or AWS Sagemaker first.
Then as a second option, you may try your own managed machine (or a compute cloud instance such as an EC2 instance). In this case, you’d probably roll a Python web server using transformers and FastAPI libraries.
You also have the option of fine-tuning (some API providers also have this option), and it’s worth mentioning you’ll need both expensive hardware and good data. If you delve into this topic with local models, look at PEFT.
Choose a Frontend for Your Users
Here’s a few options for your frontend to spark your imagination:
- Web app
- Mobile application
- Plugins (Browser-based, IDE-based, etc.)
- API (requires your unique model to provide value)
This is still important to consider and decide for your application.
Development Tooling
Choosing your model
So, how do you choose the best model? Well, first, there’s naturally the price it will cost to use it.
Second, how much data can you fit into the model architecture before it can no longer process? This effectively controls how large a model’s “short-term” memory is.
And finally, make sure you pick a model suitable for your use case. For instance, you shouldn’t pick a base model and try to use it directly for chatting. It needs to be fine-tuned for the tasks you intend to use it for.
Usually, models served from paid API is general purpose, but when choosing to host your model yourself, you have to pay more attention to the options:
- Base models require fine-tuning
- Coding models (Starcoder, Codegen)
- Chatting models (LLaMA-2 chat)
- Instruct following models (LLaMA-2 instruct)
- API calling models (Gorilla)
Prompting frameworks
There are many frameworks, but I like mentioning Langchain and Guidance.
Langchain excels at prompting, model chaining, and integrating with external tools. It’s great at prototyping an application.
Guidance, on the other hand, adds the possibility to influence the output of the model through bias and custom sampling algorithms. This is useful when you force your model to output certain values or in a specific format, for instance, to generate valid JSON objects.
Prompting techniques
Once you have a model, sometimes it does not give you the expected performance. A few prompting techniques can help you push the boundaries of what you can do with the model. Some popular methods are “few shot” and chain of thought.
Embeddings
They are vectors to represent data. The most famous and older example is word2vec, which maps specific words into a semantic space such that similar words hold similar meanings.
Embeddings can be useful to work around the model’s maximum context size through information retrieval and are typically used to implement question/answer chatbots.
Keep in mind: Open Source models outperform OpenAI embeddings! Most models are rather small and run fine even on CPU. Definitely worth checking this Hugging Face Leaderboard when choosing your embedding models.
It’s also important to understand what they are good at representing, typically capture semantic meaning well, and consider using different distance functions: cosine or vector magnitude.
Embeddings frameworks
Sentence transformers, integrated into Hugging Face, allow you to easily use embeddings models. Also integrated into Langchain.
In this topic, you’d often use a vector datastore, such as Chroma or Qdrant.
Finally, there are frameworks such as LlamaIndex that aim at providing easy-to-use methods to index your data with embeddings.
An Example Stack: An Adventure Game
- Web frontend app (JavaScript/TypeScript framework)
- Web backend API. Hosting FastAPI + HuggingFace transformers or working as a Proxy to OpenAI API.
- Use guidance for prompting sampling, generates unique items, scenarios, dialogs, etc.
- Optional layer: Self-hosted model a second layer. See andromeda-chain as an example.
Wrapping Up: General Tips
- Avoid fine-tuning when possible; it’s hard to get it right
- Start with a paid API (such as OpenAI) to get started and build a prototype unless your use case requires hosting models yourself
- Study existing projects to get started
Getting Started With LLM Application Development (Based on My Medium Day Talk) was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.